Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
itoyan110
870 views
NagoyaStat #4 ご挨拶と前回の復習
尤度比検定、二種類の過誤、p値、パラメトリックブートストラップ法、ロジスティック回帰などについて20分程度で復習しました。
Science
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
NagoyaStat #5 ご挨拶と前回の復習
by
itoyan110
PDF
Chapter7 回帰分析の悩みどころ
by
itoyan110
PDF
なめるな!plot
by
itoyan110
PDF
データ解析のための統計モデリング入門 1~2章
by
itoyan110
PDF
Rで確認しながら解く統計検定2級
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2017
by
itoyan110
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2018
by
itoyan110
NagoyaStat #5 ご挨拶と前回の復習
by
itoyan110
Chapter7 回帰分析の悩みどころ
by
itoyan110
なめるな!plot
by
itoyan110
データ解析のための統計モデリング入門 1~2章
by
itoyan110
Rで確認しながら解く統計検定2級
by
itoyan110
このIRのグラフがすごい!上場企業2017
by
itoyan110
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
このIRのグラフがすごい!上場企業2018
by
itoyan110
What's hot
PDF
このIRのグラフがすごい!上場企業2021
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2019
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2016
by
itoyan110
PDF
Rでノンパラメトリック法 1
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2015
by
itoyan110
PDF
コイン投げの分析を一捻り (Japan.R 2013 LT)
by
itoyan110
PDF
絶対に描いてはいけないグラフ入りスライド24枚
by
itoyan110
PDF
35thwebmining_lt
by
Daisuke Amano
PPTX
Bi&データ可視化ツール@tokyowebmining35
by
智明 高松
PPTX
Kandai R 入門者講習
by
考司 小杉
PDF
Kandai.R #1 公開用
by
Daisuke Nakanishi
PPTX
心理統計の課題をRmdで作る
by
考司 小杉
PDF
相互運用可能な知的活動測定システムの研究
by
yamahige
PPTX
データプランナーによるデータ系施策について
by
Recruit Lifestyle Co., Ltd.
PDF
リクルートライフスタイル流!分析基盤との賢い付き合い方
by
Recruit Lifestyle Co., Ltd.
PDF
RでTwitterテキストマイニング
by
Yudai Shinbo
このIRのグラフがすごい!上場企業2021
by
itoyan110
このIRのグラフがすごい!上場企業2019
by
itoyan110
このIRのグラフがすごい!上場企業2016
by
itoyan110
Rでノンパラメトリック法 1
by
itoyan110
このIRのグラフがすごい!上場企業2015
by
itoyan110
コイン投げの分析を一捻り (Japan.R 2013 LT)
by
itoyan110
絶対に描いてはいけないグラフ入りスライド24枚
by
itoyan110
35thwebmining_lt
by
Daisuke Amano
Bi&データ可視化ツール@tokyowebmining35
by
智明 高松
Kandai R 入門者講習
by
考司 小杉
Kandai.R #1 公開用
by
Daisuke Nakanishi
心理統計の課題をRmdで作る
by
考司 小杉
相互運用可能な知的活動測定システムの研究
by
yamahige
データプランナーによるデータ系施策について
by
Recruit Lifestyle Co., Ltd.
リクルートライフスタイル流!分析基盤との賢い付き合い方
by
Recruit Lifestyle Co., Ltd.
RでTwitterテキストマイニング
by
Yudai Shinbo
Viewers also liked
PDF
ビジネスマン必見!キレイな提案書を作るためのデザインの基礎知識
by
Tsutomu Sogitani
PDF
レッツノートを業務用途にカスタマイズする
by
itoyan110
PDF
しょぼいプレゼンをパワポのせいにするな! by @jessedee
by
「MakeLeaps」請求書の作成、管理、郵送
PPT
色彩センスのいらない配色講座
by
Mariko Yamaguchi
PDF
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
PDF
TAL2016 University of Twente
by
AIMTEC
PDF
Smm2: Social Media Management_Gestao dos Social Media 2
by
Manuela Aparicio
PDF
Smm1: Social Media Management_Gestao dos Social Media 1
by
Manuela Aparicio
PPTX
Fonética francesa
by
Dona Ortega
PDF
Fermentasi nira siwalan
by
Dhe Dhewy
PPTX
Me mes
by
Tomohiko Aoyama
PPTX
超スマート社会の光と影:普通の人はどう変わる Opportunities and Perils of the "Society 5.0": What it...
by
Takushi Otani
PDF
Austin T Schaffer - Writing Sample - NASA LaRC Internship Responsibilities
by
Austin Schaffer
PDF
Rで実験計画法 前編
by
itoyan110
PDF
Pet4 schoolswriting
by
Cecilia Fc
PDF
Enerji̇ santrali̇ buhar jeneratörü doğalgaz isitma
by
Murat Cengiz
ビジネスマン必見!キレイな提案書を作るためのデザインの基礎知識
by
Tsutomu Sogitani
レッツノートを業務用途にカスタマイズする
by
itoyan110
しょぼいプレゼンをパワポのせいにするな! by @jessedee
by
「MakeLeaps」請求書の作成、管理、郵送
色彩センスのいらない配色講座
by
Mariko Yamaguchi
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
TAL2016 University of Twente
by
AIMTEC
Smm2: Social Media Management_Gestao dos Social Media 2
by
Manuela Aparicio
Smm1: Social Media Management_Gestao dos Social Media 1
by
Manuela Aparicio
Fonética francesa
by
Dona Ortega
Fermentasi nira siwalan
by
Dhe Dhewy
Me mes
by
Tomohiko Aoyama
超スマート社会の光と影:普通の人はどう変わる Opportunities and Perils of the "Society 5.0": What it...
by
Takushi Otani
Austin T Schaffer - Writing Sample - NASA LaRC Internship Responsibilities
by
Austin Schaffer
Rで実験計画法 前編
by
itoyan110
Pet4 schoolswriting
by
Cecilia Fc
Enerji̇ santrali̇ buhar jeneratörü doğalgaz isitma
by
Murat Cengiz
More from itoyan110
PDF
このIRのグラフがすごい!上場企業2024 (The graph on this IR is amazing! Listed companies in J...
by
itoyan110
PDF
Reviewing Let's Note CF-FV3 (レッツノート CF-FV3 をレビューする)
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2023
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2020
by
itoyan110
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
PDF
2018年6月期 統計検定2級&準1級 対策スライド
by
itoyan110
PDF
Rの拡張を書く (R 2.15.2)
by
itoyan110
PDF
Rで実験計画法 後編
by
itoyan110
このIRのグラフがすごい!上場企業2024 (The graph on this IR is amazing! Listed companies in J...
by
itoyan110
Reviewing Let's Note CF-FV3 (レッツノート CF-FV3 をレビューする)
by
itoyan110
このIRのグラフがすごい!上場企業2023
by
itoyan110
このIRのグラフがすごい!上場企業2020
by
itoyan110
Chapter9 一歩進んだ文法(前半)
by
itoyan110
2018年6月期 統計検定2級&準1級 対策スライド
by
itoyan110
Rの拡張を書く (R 2.15.2)
by
itoyan110
Rで実験計画法 後編
by
itoyan110
NagoyaStat #4 ご挨拶と前回の復習
1.
NagoyaStat #4 ご挨拶と前回の復習 @ito_yan E-mail: 1mail2itoh3
[at] gmail.com 2017.02.03 NagoyaStat #4
2.
今回の内容 • ご挨拶と前回の復習 • 重要なところを思い出しましょう •
参加者による自己紹介・近況報告 • 「データ解析のための統計モデリング入門」発表 • 第7章 Yukix2200 様 • 第8章 t_yamagu 様 2
3.
主催者について • TwitterID: @ito_yan •
ITインフラ屋さん • 仮想サーバ(構築、運用) • Javaアプリケーション開発 • 後輩の指導やユーザサポートなど面倒を見る業務 • 小規模ネットワーク構築(入門中) • CiscoやHPの機器と戯れてます 3
4.
勉強会で取り上げる書籍について • 「データ解析のための統計モデリング入門」 • 通称:緑本 •
農学系のデータを扱っているが、農学系以外の 分野でも適用可能な内容となっている 4
5.
第5章の概要 • 尤度比検定 • 2つのネストしたモデルの逸脱度の差をみて、モデ ルがデータによく適合しているかを統計の検定の 手法に基づいて判断する •
ネイマン・ピアソン検定の枠組みを利用 • 帰無仮説と対立仮説を用意する • 第3章のポアソン回帰を例にとって検定を行う 5
6.
第5章の問題設定 • 検定したい内容 • 帰無仮説:一定モデル •
対立仮説:xモデル(体サイズを考慮) • 逸脱度の差は4.5となっている • 帰無仮説が真のとき、偶然と言えないほどの差か? • ネストしたモデルの比較では、パラメータが多くなる ほど逸脱度は小さくなる 6 「xモデルの方が一定モデルよ り、データによく当てはまると 主張したい」ための検定
7.
二種類の過誤 • 第一種の過誤 • 帰無仮説が正しいのに棄却する •
逸脱度の差が大きいのだから、xモデルが正しい、帰無仮 説は正しくない と誤る • 第二種の過誤 • 対立仮説が正しいのに、帰無仮説を棄却しない • 逸脱度の差は小さく、xモデルは意味もなく複雑、帰無仮 説を棄却する必要はない と誤る 7 帰無仮説は 逸脱度はめったにない差 逸脱度はよくある差 真のモデルである 第一種の過誤 正しい 真のモデルでない 正しい 第二種の過誤
8.
二種類の過誤の関係 • 一般的にトレードオフの関係にある • 手元のデータだけで、二種類の過誤を同時に減ら すのは無理 •
帰無仮説を棄却する基準を下げると(有意水準を 上げていくと)、棄却すべきでないものまで棄却して しまう。逆に、帰無仮説を棄却する基準を上げると、 棄却すべき結果を棄却しないことにつながる。 • 有意水準5%というよく見かける表現は、第一種 の過誤を5%に抑えるための方法である • 過誤の重大さによって、5%という数値は変わる 8
9.
p値 • 帰無仮説の下で、観測された現象以上に極端な ことが起こる確率をp値と呼ぶ • 今回の例では、逸脱度の差が4.5以上になる確率 •
p値が有意水準より小さければ、帰無仮説の設定 が間違っていたと考えて、対立仮説を採択する • 逆に帰無仮説を棄却できないとき、積極的に「帰無 仮説の採択」とは言わない • 第一種の誤りは有意水準5%でコントロールされているが、 第二種の誤りはコントロールされていないため • 積極的に言えるようにするには、事前にサンプルサイズを 増やすなど計画しておく必要がある 9
10.
パラメトリックブートストラップ(PB)法 • 帰無仮説が正しいとして、乱数を用いて大量に データを発生させ、検定統計量の分布を作る • 大量のデータ
= 平均7.83のポアソン分布から生成 • 平均7.83は種子数の最尤推定値(第3章で導出済) • 検定統計量 = 2モデル間の逸脱度の差 • 検定統計量でヒストグラムを作ると、逸脱度が4.5 以上の差になるのは5%にも満たず、p値は0.05 を下回るため、帰無仮説は棄却し、対立仮説が 採択される • 乱数次第で結果が変わることもある 10
11.
PB法のコードとその結果 • 逸脱度の差の分布は右図 • p値は0.03となり、帰無仮説は棄却される 11
12.
検定統計量の近似計算 • サンプルサイズが大きい場合、逸脱度の差の分 布はカイ二乗分布で近似できる • 例題(サンプルサイズ=100)ではPB法を推奨 12
13.
第6章の概要 • GLMは確率分布、リンク関数を組み合わせること で、さまざまなタイプのデータを表現できる • 第6章では、上限のあるカウントデータの表現方 法として、ロジスティック回帰が登場した •
参考:ポアソン回帰は確率分布がポアソン分布、リ ンク関数は対数をとったものだった • ポアソン回帰は上限がなく、平均と分散がほぼ同じ データに対するモデルに対して有効だった 13
14.
第6章の問題設定 • 観測対象の100個体の植物群からN個の種子を 取得し、y個が発芽し、N-y個が死滅した • 発芽するものは0~N個と整数で、かつ上限がある •
今回はN=8で固定としている • 植物の大きさと施肥処理で、発芽率が変化する様子 をモデル化してみよう • 植物の発芽と死滅は二項分布で表現できる • qは発芽確率、yが実際に発芽した数 14
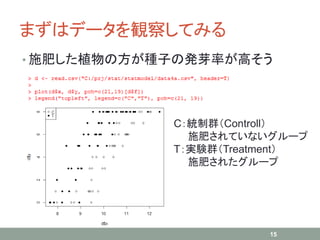
15.
まずはデータを観察してみる • 施肥した植物の方が種子の発芽率が高そう 15 C:統制群(Controll) 施肥されていないグループ T:実験群(Treatment) 施肥されたグループ
16.
ロジスティック関数 • 上限が1であり、割合を表現することに使える 16
17.
ロジット関数 • ロジスティック関数をzについて解いたものをロ ジット関数と呼ぶ • ロジット関数は生存確率(q)と線形予測子(z)をう まく結びつける関数である •
(パラメータの関数)=(線形予測子)の形ができた 17 をオッズという
18.
尤度関数表示 • 尤度関数を最大化するようにパラメータを決めれ ばよく、その計算はGLM関数で行うことができる • 対数尤度関数 18
19.
Rによるロジスティック回帰の結果 • 最尤推定の結果は となり、 体が大きくなるか、施肥をすると発芽率が高まる 19
20.
stepAIC関数 • 変数を増減させて、ネストしたモデルの間で、予 測がもっともよいモデルを選択できる • AICが最小となるのは
x + f モデル 20 x + f モデル、x モデル、f モデル の順 -fはfを考慮しないxモデルの意味
21.
交互作用 • 複数要因の積で表される効果 • 交互作用の項はむやみに入れない方がよい •
解釈が難しくなる 21
22.
次回日程について • 2016年3月末~4月上旬近辺を予定しています • 9章発表予定者:
tmkz.it 様 • 10章発表予定者: nishioka0902 様 • その次が11章のみになる • 次回までに60~90分程度の企画を考える • 次の書籍に入る、問題演習などの案があります 22
Download
![NagoyaStat #4
ご挨拶と前回の復習
@ito_yan
E-mail: 1mail2itoh3 [at] gmail.com
2017.02.03
NagoyaStat #4](https://image.slidesharecdn.com/nagoyastat4greeting-170208133920/85/NagoyaStat-4-1-320.jpg)