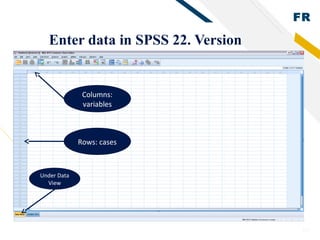
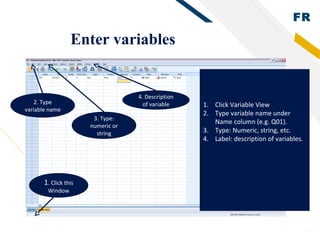
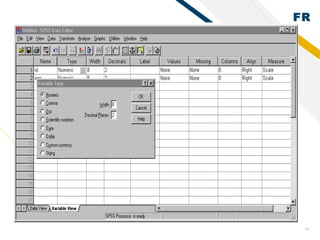
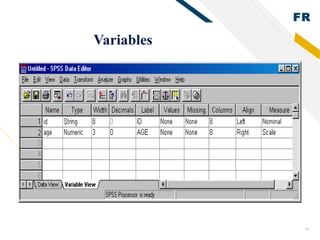
SPSS is statistical software used by researchers to perform statistical analysis. It was first released in 1968 as the Statistical Package for the Social Sciences. SPSS is now owned by IBM and allows users to manage and analyze data, perform statistical tests, and produce graphs and reports. Researchers use SPSS to clean, code, and enter data, choose appropriate statistical tests to analyze the data, and interpret the results.




























































![SPSS Lecture_1 [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/spsslecture1autosaved-231105165336-b29c7b18-thumbnail.jpg?width=640&height=640&fit=bounds)











































