Downloaded 20 times









![IT@Intel 9
BDRF: Seamless Spark job deployment
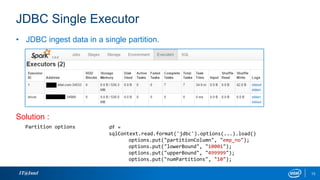
• Job Deployment is easier than ever in -local, yarn-client or yarn-cluster mode.
spark_mode: yarn-cluster
• Dependencies management in yarn-cluster mode.
#Run spark batch job
if [ "$SPARK_MODE" = 'yarn-cluster' ]; then
spark-submit --master ${SPARK_MODE}
--conf "spark.driver.extraClassPath=${SPARK_CLUSTER_EXTRACLASSPATH}"
--conf "spark.executor.extraClassPath=${SPARK_CLUSTER_EXTRACLASSPATH}"
--conf "spark.executor.memory = ${exec-mem}"
--conf "spark.yarn.dist.files=${SPARK_YARN_DIST_FILES},${INI_FILE}"
--py-files "${SPARK_PYTHON_FILES}"
${SPARK_SCRIPT} $(basename ${INI_FILE}) ${HDENV} ${NUM_EXEC} ${GATEWAY}
• Put a framework utilization dashboard for projects.](https://image.slidesharecdn.com/snehalsakharespeeditupandsparkitupatintel-170622195035/85/Speed-it-up-and-Spark-it-up-at-Intel-9-320.jpg)




![Challenge with Big datasets
IT@Intel 17
Failures when running queries:
– > 2.3 TB
– > 6 billion records
WARN servlet.ServletHandler: Error for /jobs/job/
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:2367)
ERROR server.TransportRequestHandler: Error sending result RpcResponse{requestId=8891220538372697062,
body=NioManagedBuffer{buf=java.nio.HeapByteBuffer[pos=0 lim=166 cap=166]}} to node019:40175; closing connection
org.apache.spark.SparkException: Error sending message
Caused by: java.nio.channels.ClosedChannelException
ERROR executor.CoarseGrainedExecutorBackend: RECEIVED SIGNAL 15: SIGTERM
Container
is killed](https://image.slidesharecdn.com/snehalsakharespeeditupandsparkitupatintel-170622195035/85/Speed-it-up-and-Spark-it-up-at-Intel-17-320.jpg)









During the 2017 Dataworks Summit, Sandra Guija and Snehal Sakhare from Intel IT shared insights on enhancing data ingestion using Spark, emphasizing the development of a reusable ingestion framework to improve application performance and productivity. They discussed challenges related to big data management, including optimizing job performance, managing dependencies, and ensuring efficient resource utilization. Key techniques included using Spark SQL, tuning executor memory, and deploying libraries properly to optimize Spark job execution.






















































































