Downloaded 178 times






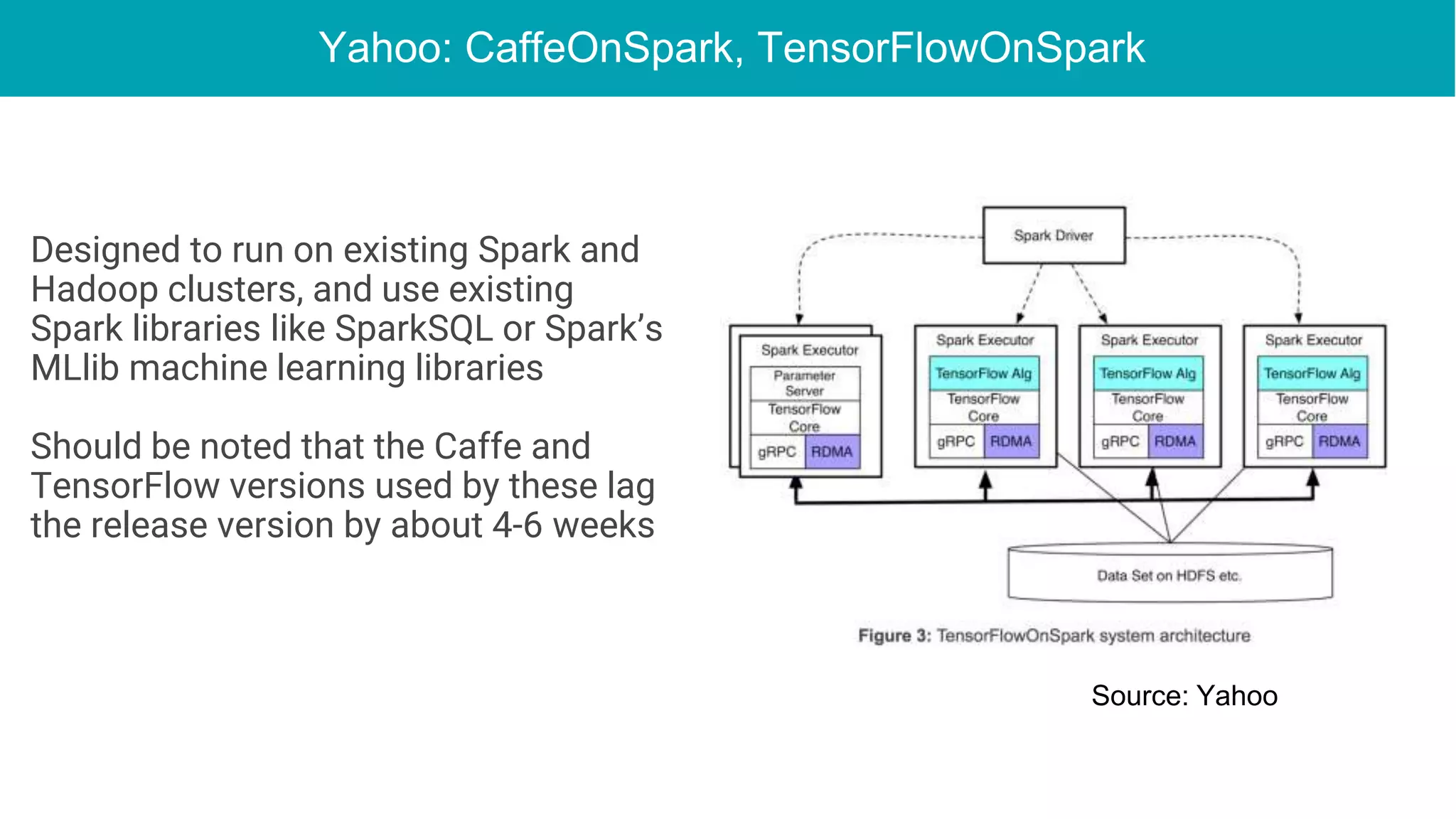
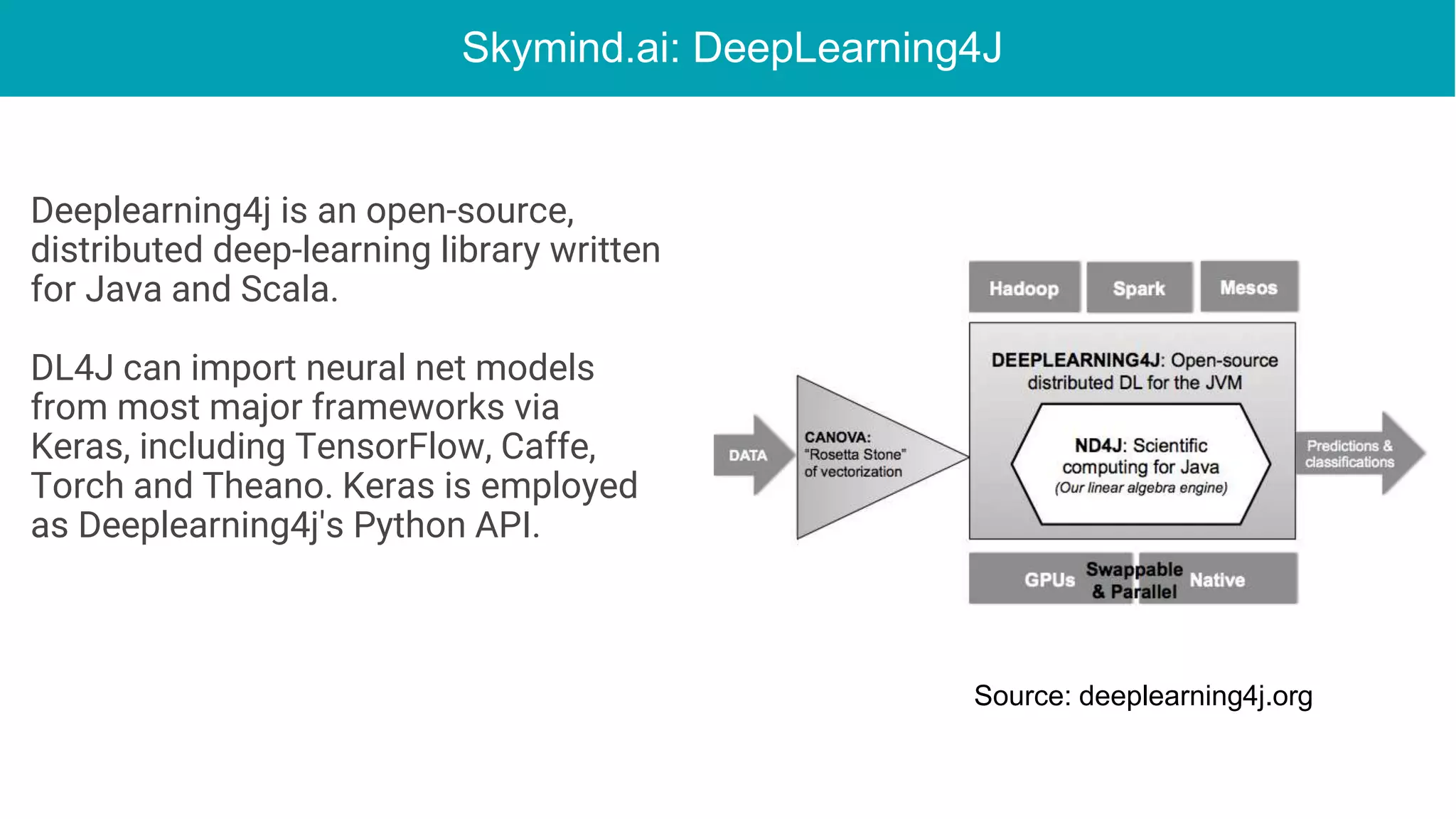
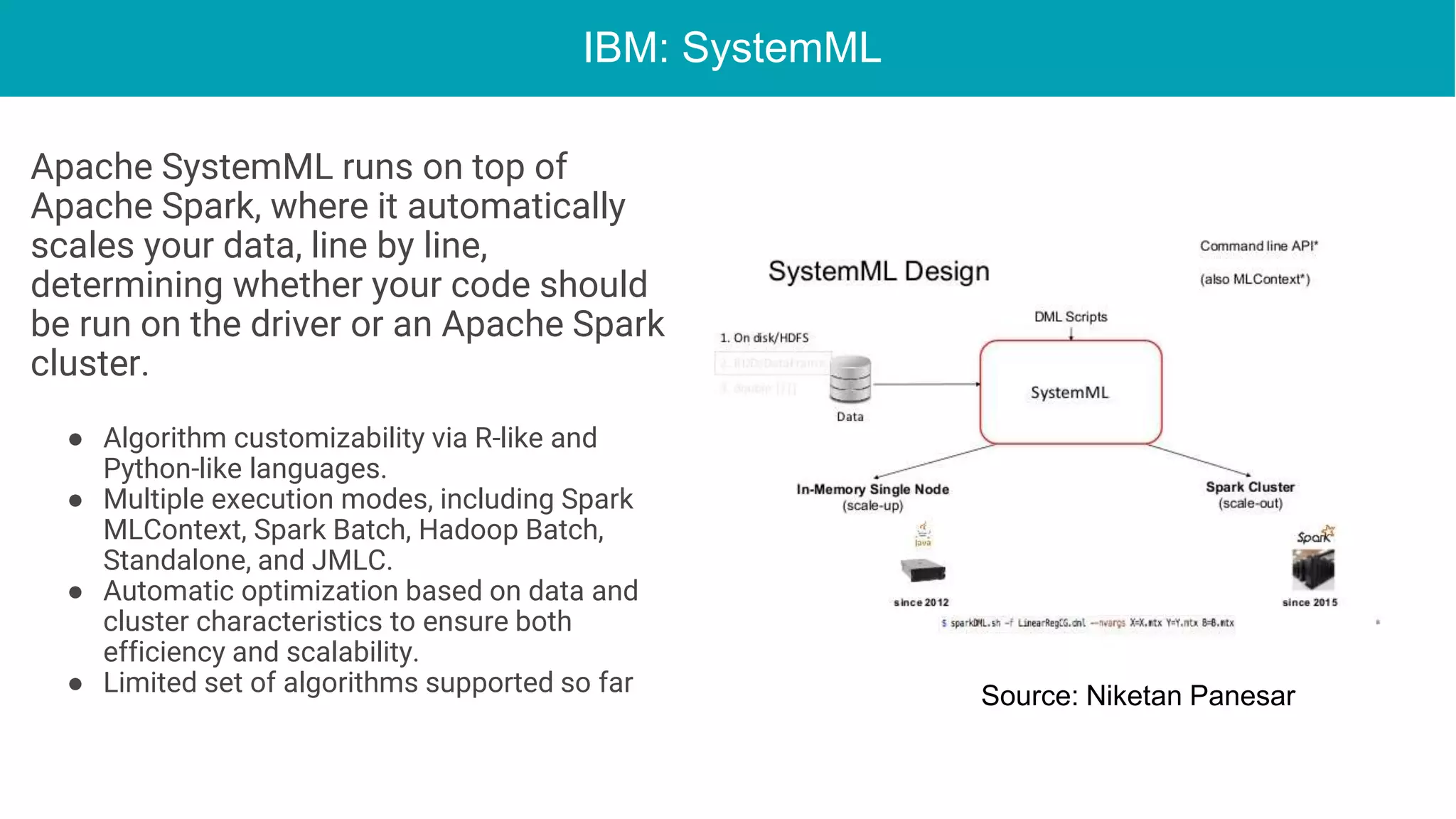
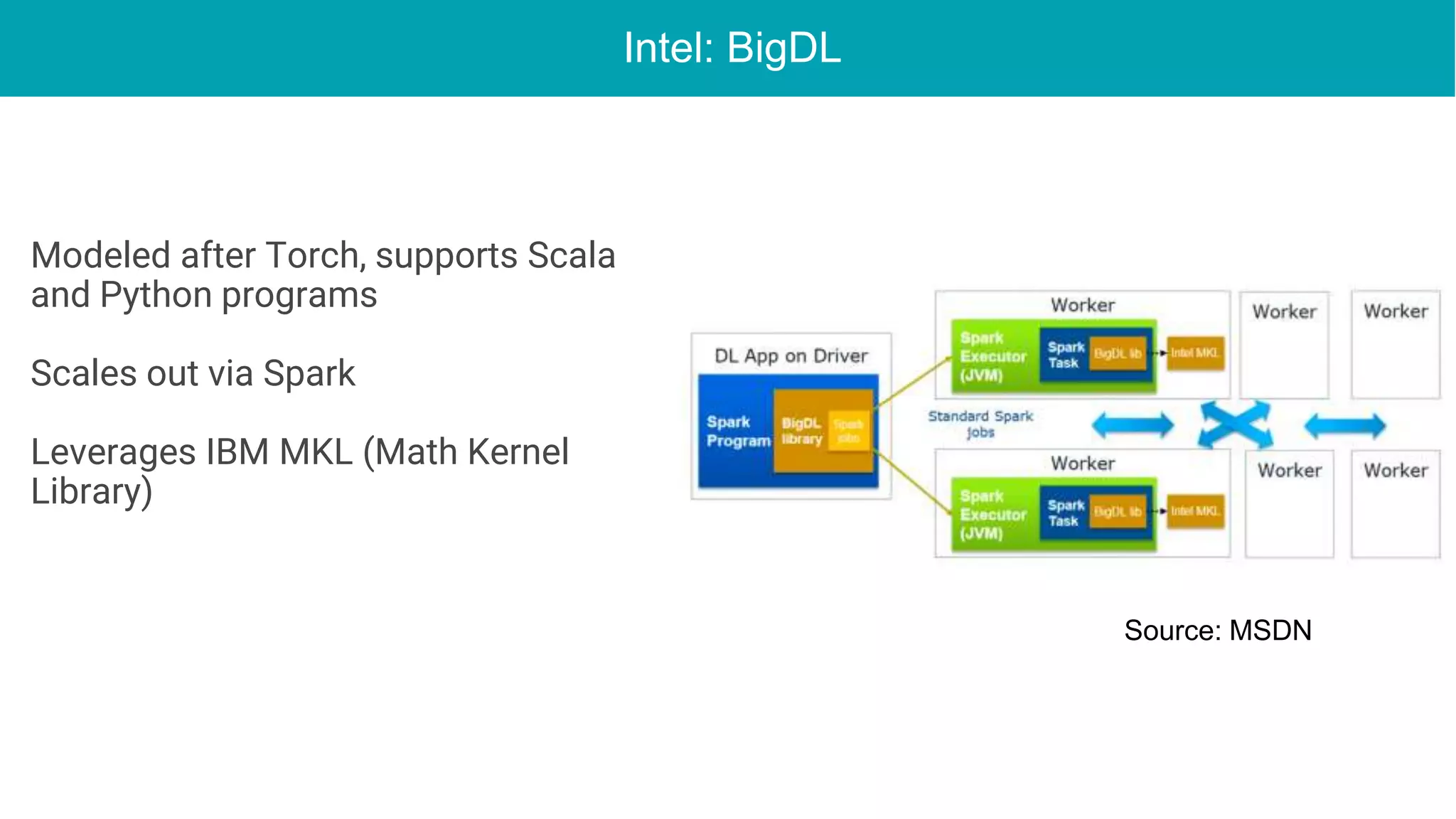
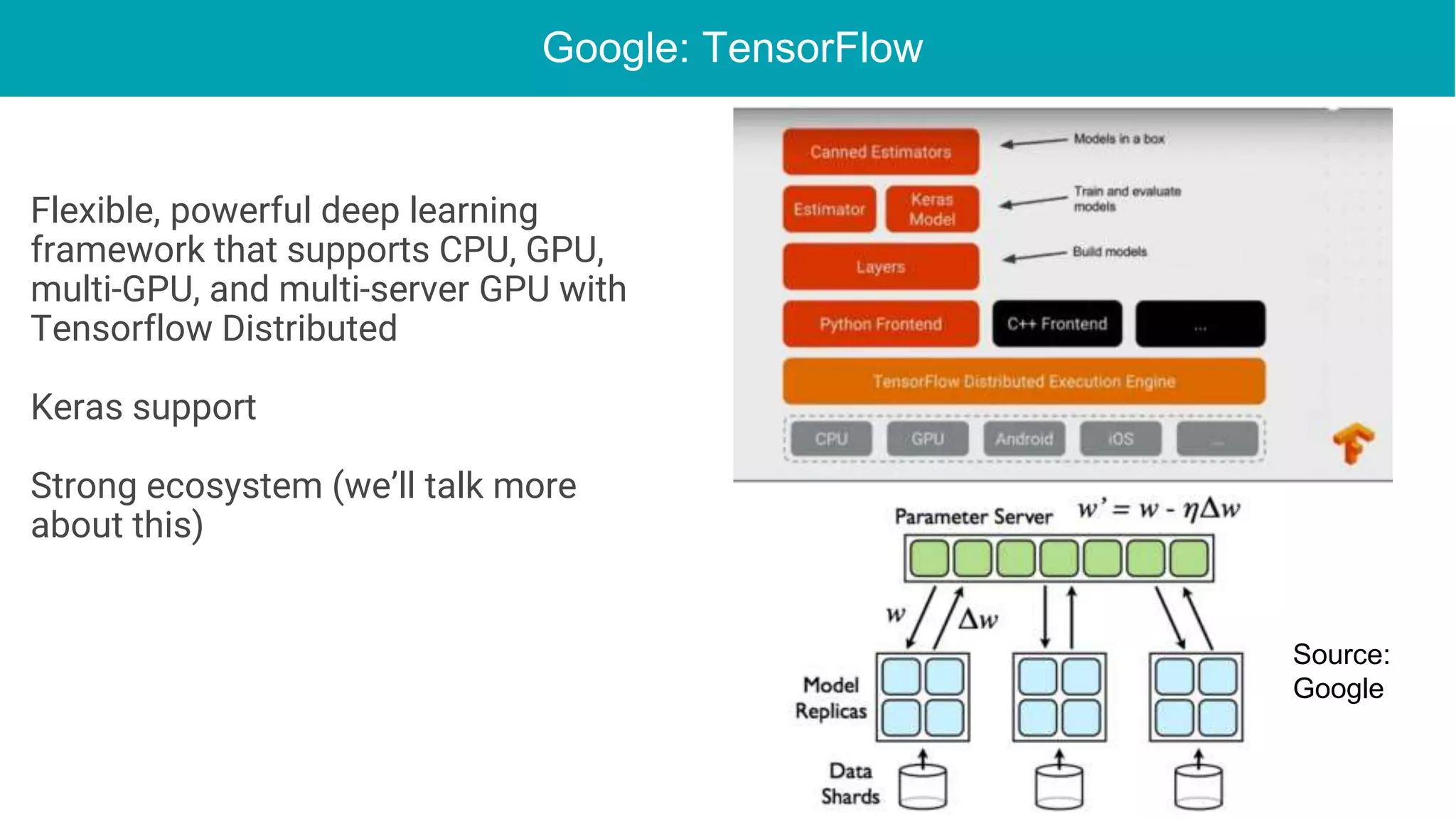

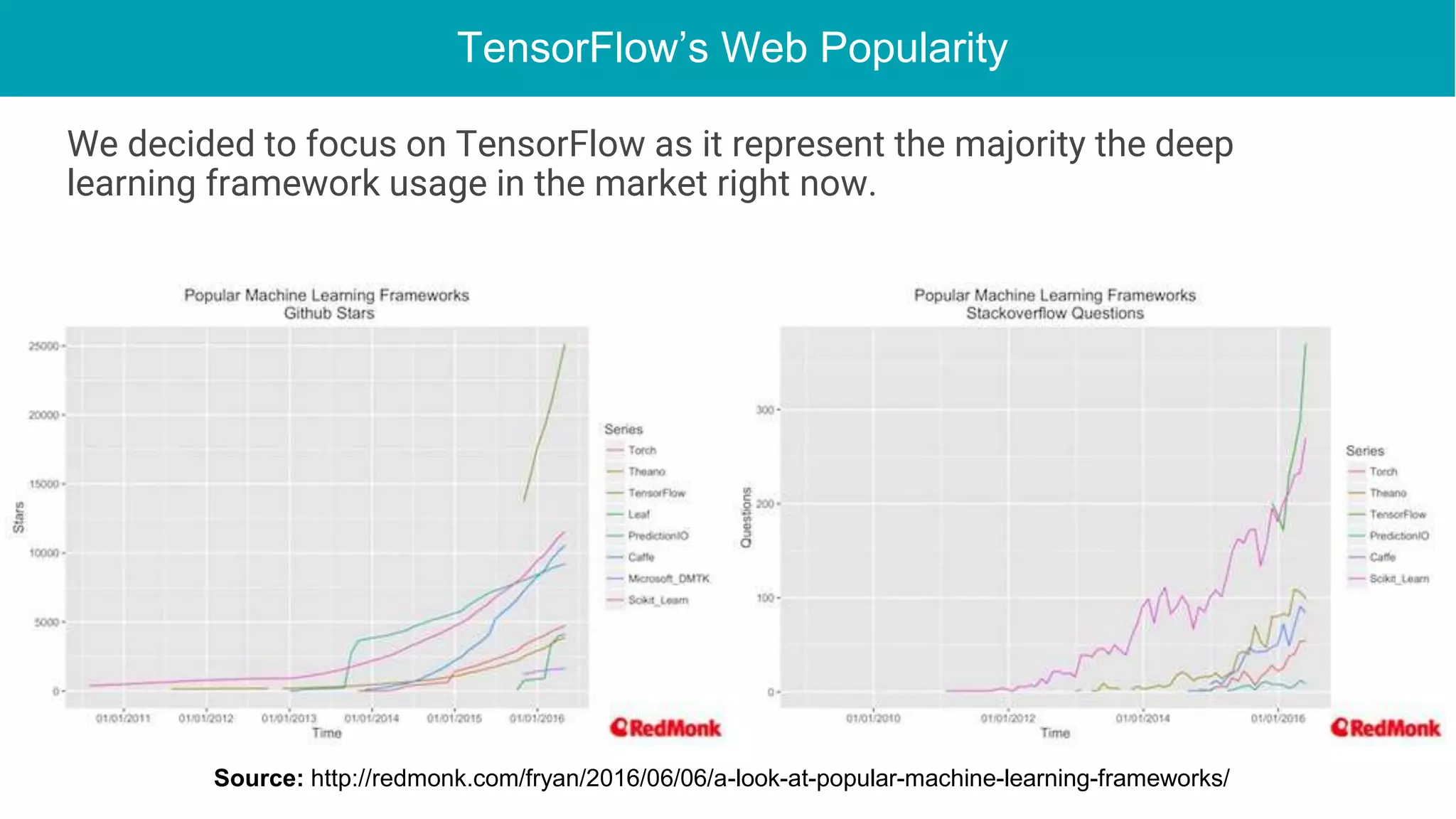
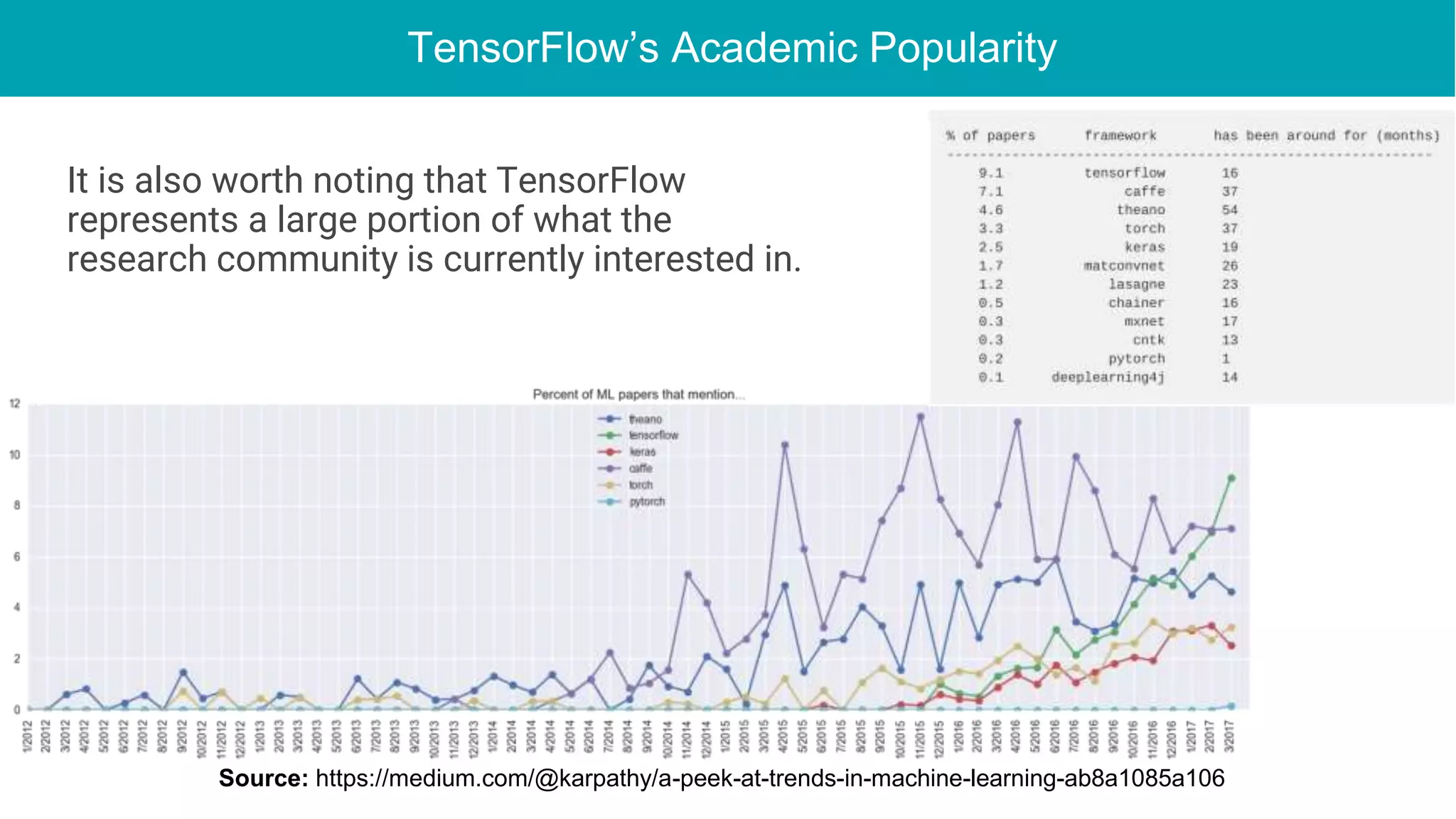

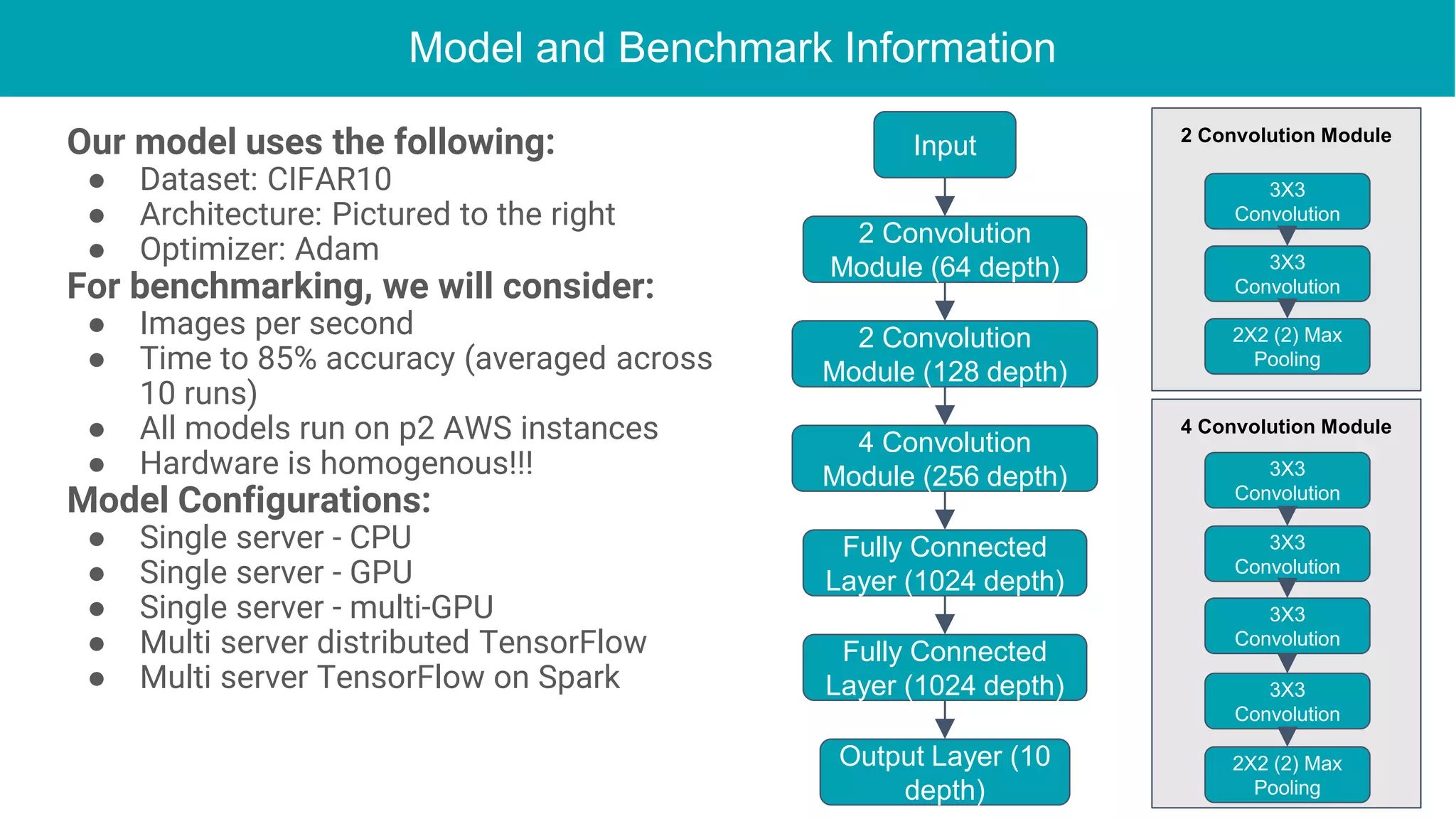

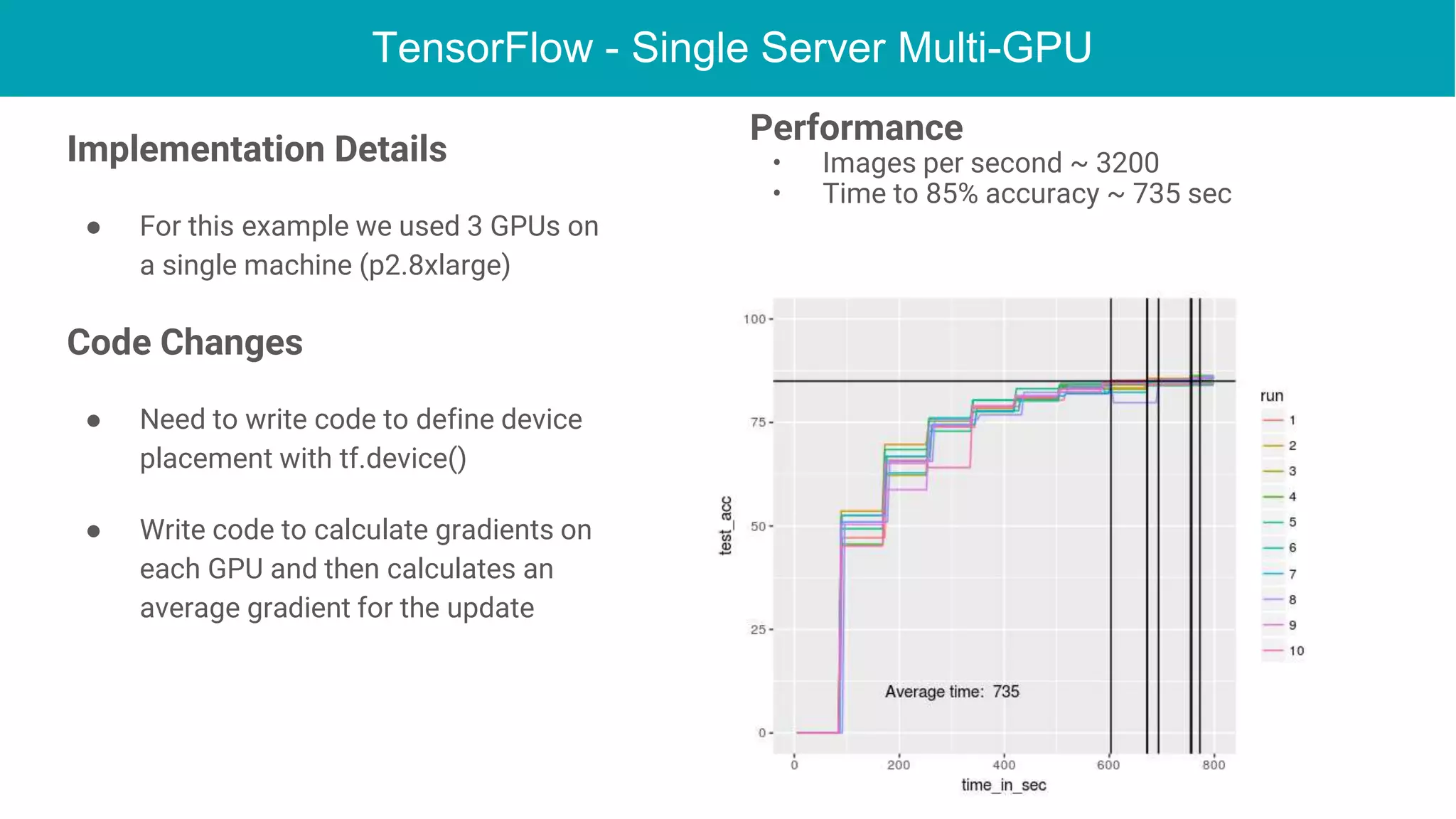


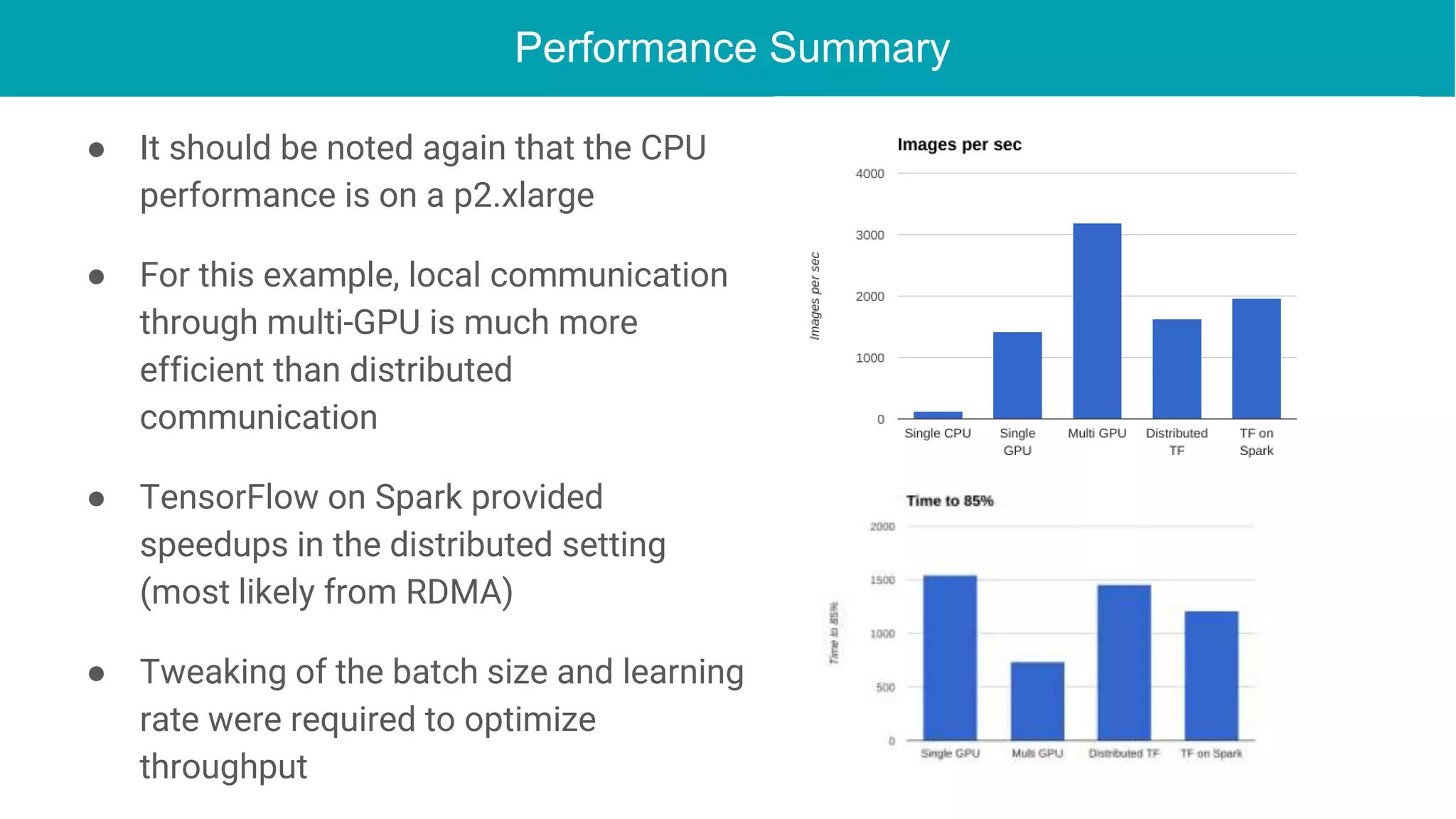









This document discusses the integration of deep learning frameworks with Apache Spark and GPU clusters, emphasizing their importance for data science and AI. It reviews various frameworks such as TensorFlow, Caffe, and Deeplearning4j, detailing their functionalities and performance in different configurations, including single server and distributed settings. The document also outlines practical considerations for optimizing performance based on hardware and network setup, as well as future research directions in the field.



































































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)











![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)





