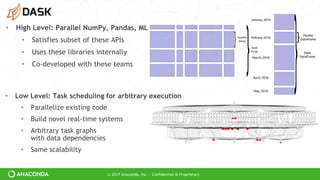
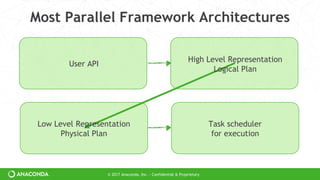
Dask is a Python library for parallel computing that allows users to scale existing Python code to larger datasets and clusters. It provides parallelized versions of NumPy, Pandas, and Scikit-Learn that have the same interfaces as the originals. Dask can be used to parallelize existing Python code with minimal changes, and it supports scaling computations from a single multicore machine to large clusters with thousands of nodes. Dask's task-scheduling approach allows it to be more flexible than other parallel frameworks and to support complex computations and real-time workloads.















![© 2017 Anaconda, Inc. - Confidential & Proprietary
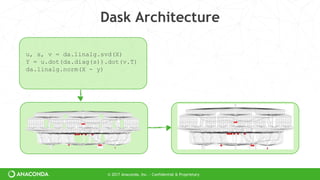
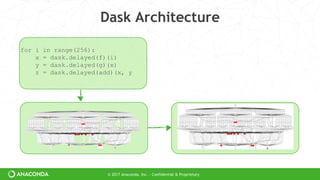
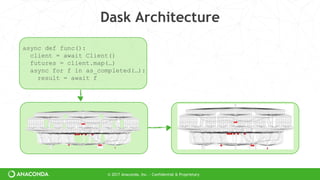
Dask Architecture
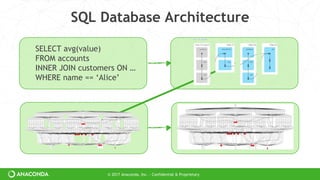
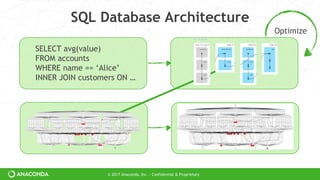
accts=dd.read_parquet(…)
accts=accts[accts.name == ‘Alice’]
df=dd.merge(accts, customers)
df.value.mean().compute()
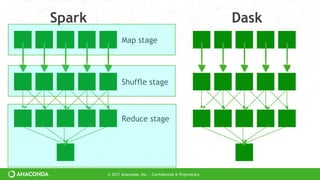
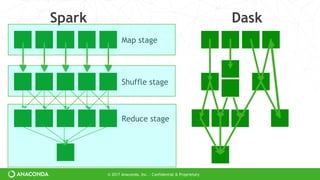
Dask doesn’t have a high-level abstraction
Dask can’t optimize
But Dask is general to many domains](https://image.slidesharecdn.com/strata-nyc-dask-2017-ppt-170927181810/85/Dask-Scaling-Python-22-320.jpg)



![© 2017 Anaconda, Inc. - Confidential & Proprietary
1. Scalable Pandas DataFrames
• Same API
import dask.dataframe as dd
df = dd.read_parquet(‘s3://bucket/accounts/2017')
df.groupby(df.name).value.mean().compute()
• Efficient Timeseries Operations
# Use the pandas index for efficient
operations
df.loc[‘2017-01-01’]
df.value.rolling(10).std()
df.value.resample(‘10m’).mean()
• Co-developed with Pandas
and by the Pandas developer community](https://image.slidesharecdn.com/strata-nyc-dask-2017-ppt-170927181810/85/Dask-Scaling-Python-32-320.jpg)