Downloaded 14 times








![id label data
1 cat
2 cat
3 dog
Id label fn1 fn2
1 cat [1.5] [0.1, 2.1]
2 cat [1.7] [0.2, 1.0]
3 dog [11.9] [22.0, 2.0]
DataFrames: Our Primary Data Format
Training/test dataframe Feature dataframe
Distributed collection of data in named columns](https://image.slidesharecdn.com/mriduljaincaffeonsparkupdaterecentenhancementsandusecases-170621224944/85/CaffeOnSpark-Update-Recent-Enhancements-and-Use-Cases-13-320.jpg)
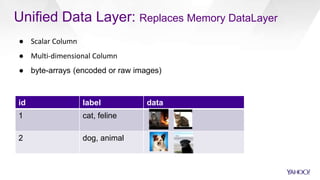



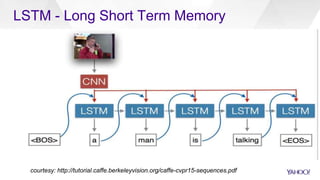
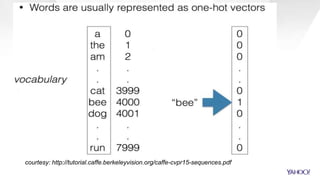



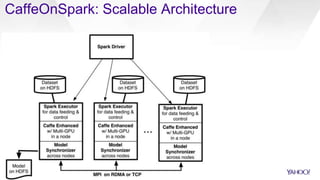

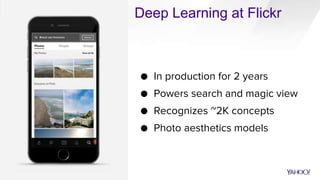
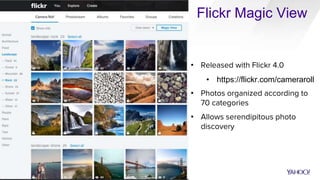
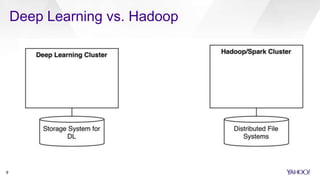
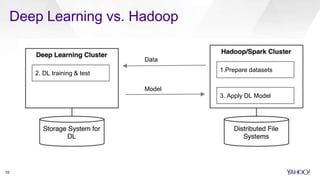
CaffeOnSpark is an open-sourced framework by Yahoo for scalable deep learning using Apache Spark, facilitating the deployment on public and private clouds. It supports advanced features such as LSTM training and validation, a unified data layer, and integration with TensorFlow. The tool has been effectively utilized at Yahoo for various applications including photo categorization and esports highlight reel generation.






















































































