




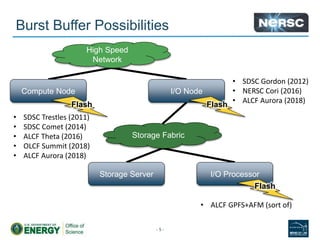
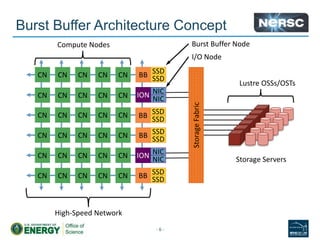
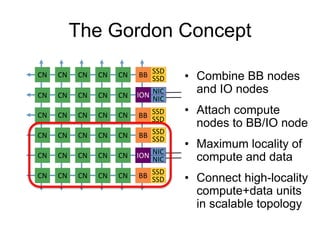
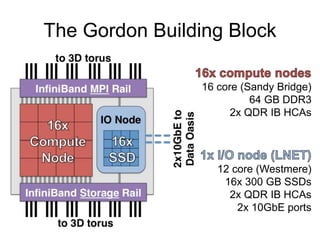




![Proto-burst buffer: Staging
### Step 1. Distribute input data to all nodes (if necessary)
for node in $(/usr/bin/uniq $PBS_NODEFILE)
do
echo "$(/bin/date) :: Copying input data to node $node"
if [ $PARALLEL_COPY -ne 0 ]; then
scp $INPUT_FILES $node:$LOCAL_SCRATCH/
else
scp $INPUT_FILES $node:$LOCAL_SCRATCH/ &
fi
done
wait
### Step 2. Run desired code
mpirun_rsh -np 32 ./lmp_gordon < inputs.txt
### Step 3. Flush contents of each node's SSD back to workdir
nn=0
for node in $(/usr/bin/uniq $PBS_NODEFILE)
do
echo "$(/bin/date) :: Copying output data from node $node"
command="cd $LOCAL_SCRATCH && tar cvf $PBS_O_WORKDIR/node$nn-output.tar *"
if [ $PARALLEL_COPY -ne 0 ]; then
ssh $node "$command" &
else
ssh $node "$command"
fi
let "nn++"
done
wait
https://github.com/sdsc/sdsc-user/blob/master/jobscripts/gordon/mpi-on-ssds.qsub](https://image.slidesharecdn.com/gordonburstbufferdataseminar-170312184802/85/The-Proto-Burst-Buffer-Experience-with-the-flash-based-file-system-on-SDSC-s-Gordon-13-320.jpg)
![Proto-burst buffer: Staging
### Step 1. Distribute input data to all nodes (if necessary)
for node in $(/usr/bin/uniq $PBS_NODEFILE)
do
echo "$(/bin/date) :: Copying input data to node $node"
if [ $PARALLEL_COPY -ne 0 ]; then
scp $INPUT_FILES $node:$LOCAL_SCRATCH/
else
scp $INPUT_FILES $node:$LOCAL_SCRATCH/ &
fi
done
wait
### Step 2. Run desired code
mpirun_rsh -np 32 ./lmp_gordon < inputs.txt
### Step 3. Flush contents of each node's SSD back to workdir
nn=0
for node in $(/usr/bin/uniq $PBS_NODEFILE)
do
echo "$(/bin/date) :: Copying output data from node $node"
command="cd $LOCAL_SCRATCH && tar cvf $PBS_O_WORKDIR/node$nn-output.tar *"
if [ $PARALLEL_COPY -ne 0 ]; then
ssh $node "$command" &
else
ssh $node "$command"
fi
let "nn++"
done
wait
https://github.com/sdsc/sdsc-user/blob/master/jobscripts/gordon/mpi-on-ssds.qsub
Asking users to turn one-line
job script into 60(!) SLOC](https://image.slidesharecdn.com/gordonburstbufferdataseminar-170312184802/85/The-Proto-Burst-Buffer-Experience-with-the-flash-based-file-system-on-SDSC-s-Gordon-14-320.jpg)









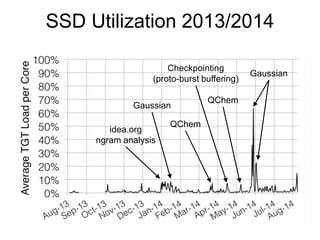
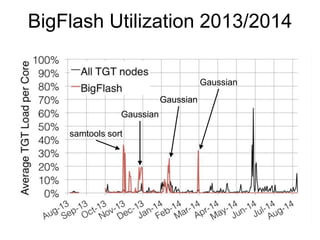
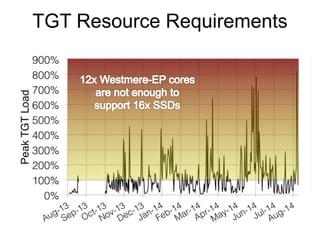



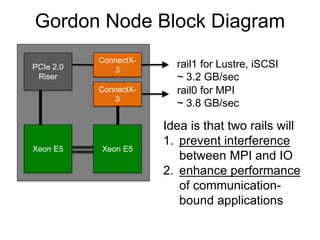
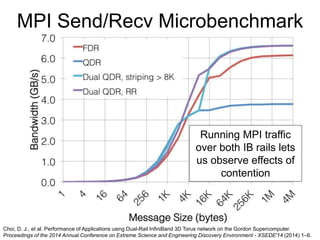
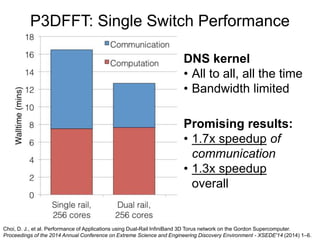
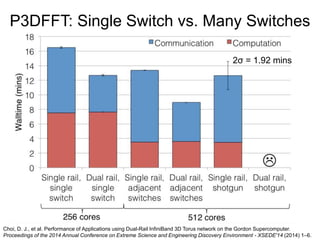
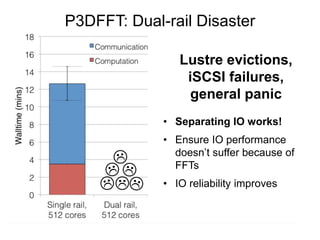


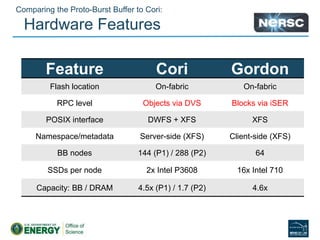




Glenn K. Lockwood's document summarizes his professional background and experience with data-intensive computing systems. It then discusses the Gordon supercomputer deployed at SDSC in 2012, which was one of the world's first systems to use flash storage. The document analyzes Gordon's architecture using burst buffers and SSDs, experiences using the flash file system, and lessons learned. It also compares Gordon's proto-burst buffer approach to the dedicated burst buffer nodes on the Cori supercomputer.






























































































