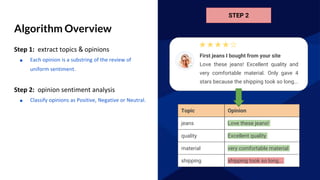
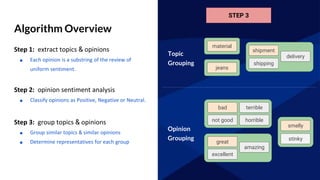
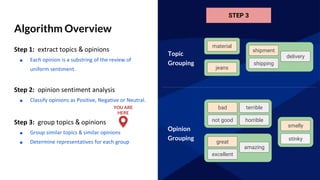
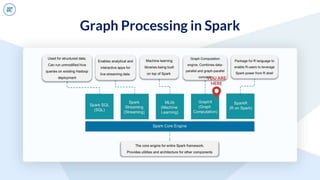
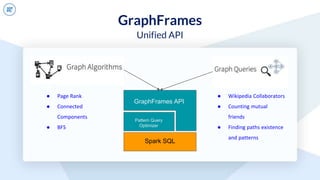
The document discusses GraphFrames, a library for graph processing in Spark. It allows for both graph algorithms and graph queries using a unified API. Some key points made:
- GraphFrames provides a unified API for graph algorithms (e.g. connected components, PageRank) and graph queries in Scala, Java, and Python.
- It uses Spark SQL's Catalyst optimizer to translate graph queries into relational operations on DataFrames for efficient execution.
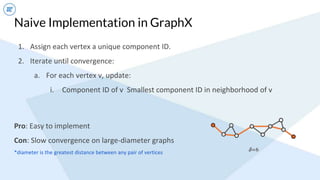
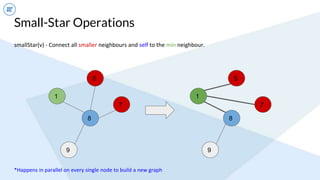
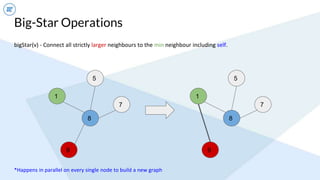
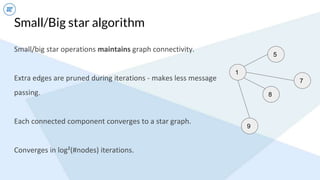
- An example algorithm discussed is connected components, where GraphFrames' implementation using small/big star operations converges faster than GraphX's naive approach on large graphs.
- Performance tests showed GraphFrames outperforms GraphX on connected components for graphs











![Query String Parsed Pattern
Logical Plan Optimized LP
DataFrame
Result
Graph
Algorithms
Materialized
Views
Relational plan
translations
View Selection Join Elimination and
Reordering
graph.find("(root)-[]->(layer1)").filter("root.is_root = true")
graph.find("(root)-[]->(layer1); (layer1)-[]->(layer2)").filter("root.is_root = true")
GraphFrames
Under The Hood
YOU ARE
HERE](https://image.slidesharecdn.com/graphprocessingatscaleusingsparkgraphframes-200124205449/85/Graph-processing-at-scale-using-spark-amp-graph-frames-22-320.jpg)
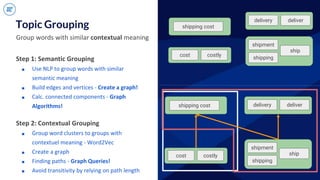
![Relational plan translations
● Edges and vertices are represented as
DataFrames
● Starts building the result DataFrame
● For each new vertex in the query we
generate a join
○ With the edges table - to get the src and
dst of the edge
○ With the vertices table - to get the
property of the vertex
graph.find("(v0)-[]->(v1); (v1)-[]->(v2)").filter(v2.attr = true)
a b
c
v0 v1 v2
a b
src dst
a b
b c
src = b
v0 v1 v2
a b c
id attr
a 1
b 2
c 3
id = c](https://image.slidesharecdn.com/graphprocessingatscaleusingsparkgraphframes-200124205449/85/Graph-processing-at-scale-using-spark-amp-graph-frames-23-320.jpg)