







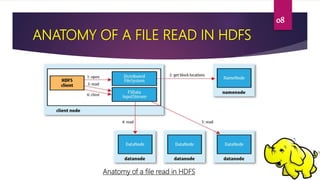
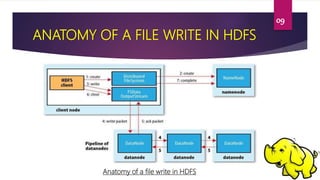


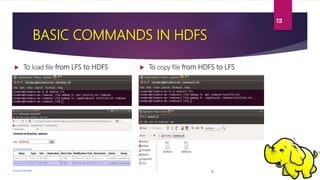






This document provides an overview of Hadoop Distributed File System (HDFS). It describes HDFS as the storage component of Hadoop that stores large datasets across commodity hardware. The key components of HDFS are the NameNode, which manages the file system metadata, and DataNodes, which store the actual data blocks. Files written to HDFS are broken into blocks and replicated across DataNodes for reliability. The document outlines the read and write processes in HDFS and provides examples of basic HDFS commands.



































































