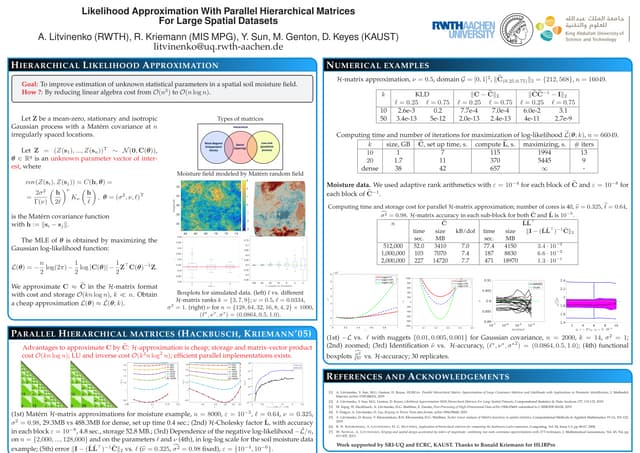
The document discusses data sparse approximation techniques related to the Karhunen-Loève expansion, focusing on numerical methods, eigenvalue problems, and the covariance structure of random fields. It explores applications such as solving stochastic partial differential equations and higher-order moments, employing methods like FFT, hierarchical matrices, and tensor approximations to achieve computational efficiency. The analysis includes examples of covariance functions and the associated computational complexity of different approximation techniques.



![Stochastic PDE
We consider
− div(κ(x, ω)∇u) = f(x, ω) in D,
u = 0 on ∂D,
with stochastic coefficients κ(x, ω), x ∈ D ⊆ Rd
and ω belongs to the
space of random events Ω.
[Babuˇska, Ghanem, Matthies, Schwab, Vandewalle, ...].
Methods and techniques:
1. Response surface
2. Monte-Carlo
3. Perturbation
4. Stochastic Galerkin](https://image.slidesharecdn.com/slides-161029080325/85/Slides-4-320.jpg)
![Examples of covariance functions [Novak,(IWS),04]
The random field requires to specify its spatial correl. structure
covf (x, y) = E[(f(x, ·) − µf (x))(f(y, ·) − µf (y))],
where E is the expectation and µf (x) := E[f(x, ·)].
Let h =
3
i=1 h2
i /ℓ2
i + d2 − d
2
, where hi := xi − yi , i = 1, 2, 3,
ℓi are cov. lengths and d a parameter.
Gaussian cov(h) = σ2
· exp(−h2
),
exponential cov(h) = σ2
· exp(−h),
spherical
cov(h) =
σ2
· 1 − 3
2
h
hr
− 1
2
h3
h3
r
for 0 ≤ h ≤ hr ,
0 for h > hr .](https://image.slidesharecdn.com/slides-161029080325/85/Slides-5-320.jpg)

![KLE
The spectral representation of the cov. function is
Cκ(x, y) = ∞
i=0 λi ki(x)ki (y), where λi and ki(x) are the eigenvalues
and eigenfunctions.
The Karhunen-Lo`eve expansion [Loeve, 1977] is the series
κ(x, ω) = µk (x) +
∞
i=1
λi ki (x)ξi (ω), where
ξi (ω) are uncorrelated random variables and ki are basis functions in
L2
(D).
Eigenpairs λi , ki are the solution of
Tki = λi ki, ki ∈ L2
(D), i ∈ N, where.
T : L2
(D) → L2
(D),
(Tu)(x) := D
covk (x, y)u(y)dy.](https://image.slidesharecdn.com/slides-161029080325/85/Slides-7-320.jpg)

![Computation of eigenpairs by FFT
If the cov. function depends on (x − y) then on a uniform tensor grid
the cov. matrix C is (block) Toeplitz.
Then C can be extended to the circulant one and the decomposition
C =
1
n
F H
ΛF (1)
may be computed like follows. Multiply (1) by F becomes
F C = ΛF ,
F C1 = ΛF1.
Since all entries of F1 are unity, obtain
λ = F C1.
F C1 may be computed very efficiently by FFT [Cooley, 1965] in
O(n log n) FLOPS.
C1 may be represented in a matrix or in a tensor format.](https://image.slidesharecdn.com/slides-161029080325/85/Slides-9-320.jpg)


![Examples of H-matrix approximates of
cov(x, y) = e−2|x−y|
[Hackbusch et al. 99]
25 20
20 20
20 16
20 16
20 20
16 16
20 16
16 16
4 4
20 4 32
4 4
16 4 32
4 20
4 4
4 16
4 4
32 32
20 20
20 20 32
32 32
4 3
4 4 32
20 4
16 4 32
32 4
32 32
4 32
32 32
32 4
32 32
4 4
4 4
20 16
4 4
32 32
4 32
32 32
32 32
4 32
32 32
4 32
20 20
20 20 32
32 32
32 32
32 32
32 32
32 32
32 32
32 32
4 4
4 4
20 4 32
32 32 4
4 4
32 4
32 32 4
4 4
32 32
4 32 4
4 4
32 32
32 32 4
4
4 20
4 4 32
32 32
4 4
4
32 4
32 32
4 4
4
32 32
4 32
4 4
4
32 32
32 32
4 4
20 20
20 20 32
32 32
4 4
20 4 32
32 32
4 20
4 4 32
32 32
20 20
20 20 32
32 32
32 4
32 32
32 4
32 32
32 4
32 32
32 4
32 32
32 32
4 32
32 32
4 32
32 32
4 32
32 32
4 32
32 32
32 32
32 32
32 32
32 32
32 32
32 32
32 32
4 4
4 4 44 4
20 4 32
32 32
32 4
32 32
4 32
32 32
32 4
32 32
4 4
4 4
4 4
4 4 4
4 4
32 4
32 32 4
4 4
4 4
4 4
4 4 4
4
32 4
32 32
4 4
4 4
4 4
4 4
4 4 4
32 4
32 32
32 4
32 32
32 4
32 32
32 4
32 32
4 4
4 4
4 4
4 4
4 20
4 4 32
32 32
4 32
32 32
32 32
4 32
32 32
4 32
4
4 4
4 4
4 4
4 4
4 4
32 32
4 32 4
4
4 3
4 4
4 4
4 4
4
32 32
4 32
4 4
4
4 4
4 4
4 4
4 4
32 32
4 32
32 32
4 32
32 32
4 32
32 32
4 32
4
4 4
4 4
20 20
20 20 32
32 32
32 32
32 32
32 32
32 32
32 32
32 32
4 4
20 4 32
32 32
32 4
32 32
4 32
32 32
32 4
32 32
4 20
4 4 32
32 32
4 32
32 32
32 32
4 32
32 32
4 32
20 20
20 20 32
32 32
32 32
32 32
32 32
32 32
32 32
32 32
4 4
32 32
32 32 4
4 4
32 4
32 32 4
4 4
32 32
4 32 4
4 4
32 32
32 32 4
4
32 32
32 32
4 4
4
32 4
32 32
4 4
4
32 32
4 32
4 4
4
32 32
32 32
4 4
32 32
32 32
32 32
32 32
32 32
32 32
32 32
32 32
32 4
32 32
32 4
32 4
32 4
32 32
32 4
32 4
32 32
4 32
32 32
4 32
32 32
4 4
32 32
4 4
32 32
32 32
32 32
32 32
32 32
32 32
32 32
32 32
25 11
11 20 12
13
20 11
9 16
13
13
20 11
11 20 13
13 32
13
13
20 8
10 20 13
13 32 13
13
32 13
13 32
13
13
20 11
11 20 13
13 32 13
13
20 10
10 20 12
12 32
13
13
32 13
13 32 13
13
32 13
13 32
13
13
20 11
11 20 13
13 32 13
13
32 13
13 32
13
13
20 9
9 20 13
13 32 13
13
32 13
13 32
13
13
32 13
13 32 13
13
32 13
13 32
13
13
32 13
13 32 13
13
32 13
13 32
Figure: H-matrix approximations ∈ Rn×n
, n = 322
, with standard (left) and
weak (right) admissibility block partitionings. The biggest dense (dark) blocks
∈ Rn×n
, max. rank k = 4 left and k = 13 right.](https://image.slidesharecdn.com/slides-161029080325/85/Slides-12-320.jpg)
![H - Matrices
Comp. complexity is O(kn log n) and storage O(kn log n).
To assemble low-rank blocks use ACA [Bebendorf, Tyrtyshnikov].
Dependence of the computational time and storage requirements of
CH on the rank k, n = 322
.
k time (sec.) memory (MB) C−CH 2
C 2
2 0.04 2e + 6 3.5e − 5
6 0.1 4e + 6 1.4e − 5
9 0.14 5.4e + 6 1.4e − 5
12 0.17 6.8e + 6 3.1e − 7
17 0.23 9.3e + 6 6.3e − 8
The time for dense matrix C is 3.3 sec. and the storage 1.4e + 8 MB.](https://image.slidesharecdn.com/slides-161029080325/85/Slides-13-320.jpg)

![Exponential Singularvalue decay [see also Schwab et
al.]
0 100 200 300 400 500 600 700 800 900 1000
0
100
200
300
400
500
600
700
0 100 200 300 400 500 600 700 800 900 1000
0
1
2
3
4
5
6
7
8
9
10
x 10
4
0 100 200 300 400 500 600 700 800 900 1000
0
200
400
600
800
1000
1200
1400
1600
1800
0 100 200 300 400 500 600 700 800 900 1000
0
0.5
1
1.5
2
2.5
x 10
5
0 100 200 300 400 500 600 700 800 900 1000
0
50
100
150
0 100 200 300 400 500 600 700 800 900 1000
0
0.5
1
1.5
2
2.5
3
3.5
4
x 10
4](https://image.slidesharecdn.com/slides-161029080325/85/Slides-15-320.jpg)
![Sparse tensor decompositions of kernels
cov(x, y) = cov(x − y)
We want to approximate C ∈ RN×N
, N = nd
by
Cr =
r
k=1 V 1
k ⊗ ... ⊗ V d
k such that C − Cr ≤ ε.
The storage of C is O(N2
) = O(n2d
) and the storage of Cr is O(rdn2
).
To define V i
k use e.g. SVD.
Approximate all V i
k in the H-matrix format and become HKT format.
See basic arithmetics in [Hackbusch, Khoromskij, Tyrtyshnikov].
Assume f(x, y), x = (x1, x2), y = (y1, y2), then the equivalent approx.
problem is f(x1, x2; y1, y2) ≈
r
k=1 Φk (x1, y1)Ψk (x2, y2).](https://image.slidesharecdn.com/slides-161029080325/85/Slides-16-320.jpg)



![Application: higher order moments
Let operator K be deterministic and
Ku(θ) =
α∈J
Ku(α)
Hα(θ) = ˜f(θ) =
α∈J
f(α)
Hα(θ), with
u(α)
= [u
(α)
1 , ..., u
(α)
N ]T
. Projecting onto each Hα obtain
Ku(α)
= f(α)
.
The KLE of f(θ) is
f(θ) = f +
ℓ
λℓφℓ(θ)fl =
ℓ α
λℓφ
(α)
ℓ Hα(θ)fl
=
α
Hα(θ)f(α)
,
where f(α)
= ℓ
√
λℓφ
(α)
ℓ fl .](https://image.slidesharecdn.com/slides-161029080325/85/Slides-20-320.jpg)