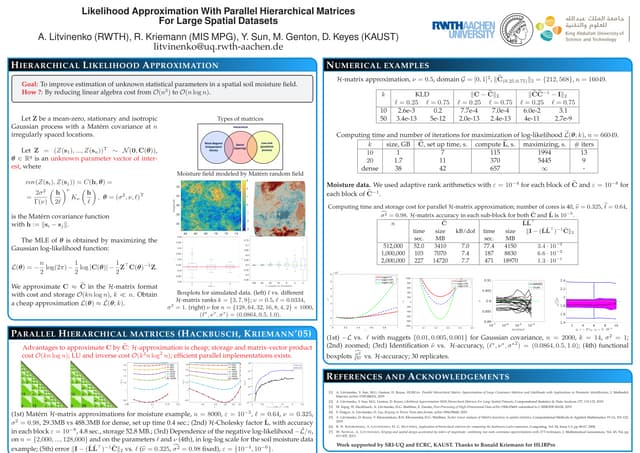
The document discusses the application of tensor train (TT) approximation for uncertainty quantification, aiming to significantly reduce computational time and storage costs. It explores various strategies for polynomial chaos expansion (PCE) and presents methods for computing stochastic Galerkin operators in TT format, achieving efficient data processing. Key outcomes include a proposed workflow for solving stochastic partial differential equations (SPDEs) and generating statistical measures in TT format.
![Center for Uncertainty
Quantification
Response Surface in Tensor Train
Format for Uncertainty Quantification
Alexander Litvinenko1
, S. Dolgov2
, B. Khoromskij2
, H. G. Matthies3
1
KAUST, 2
MPI for Mathematics in the Sciences, Leipzig, 3
TU Braunschweig
alexander.litvinenko@kaust.edu.sa
Center for Uncertainty
Quantification
Center for Uncertainty
Quantification
1. Motivation
• To reduce computational time from days to hours, to minutes.
• To reduce required storage cost from GB to MB or KB’s.
• UQ: Computational algorithms, run on supercomputers, can
simulate and resolve very complex phenomena. But how reli-
able are these predictions? Can we trust to these results?
Some parameters are unknown, lack of data, very few mea-
surements → uncertainty.
Abstract
• Applied Tensor Train (TT) approximation to stochas-
tic Galerkin matrix,
• Solved SPDE in TT,
• Compared 2 strategies of PCE: sparse and full poly-
nomial (multi-index) sets.
• Evaluated mean, variance, Sobol indicesin TT for-
mat.
Plan:
• Interpolate PCE coefficients in TT format via block
cross approximation method
• Approximate operator in TT format
• Solve discretized equation via alternating minimal
energy algorithm.
2. Take to home
1. Compute solution of SPDE in TT format.
2. Post-processing: the mean value, covariance, Sobol
indices, level sets in the TT data format.
3. TT becomes preferable for high polynomial order p.
4. The TT approach scales linearly with p.
3. Modell and discretisation
− div(κ(x, ω) u(x, ω)) = f(x, ω) in G × Ω, G ⊂ R2
,
u = 0 on ∂G,
(1)
where κ(x, ω) = eγ(x,ω)
.
Compute in TT format:
1. PCE of κ(x, ω)
2. Stochastic Galerkin matrix K
3. Solution of the linear system u = K−1
f
4. Statistics, Sobol indices, max element,level sets
We assume κ = φ(γ) -a smooth transformation of the
Gaussian random field γ(x, ω), e.g. φ(γ) = exp(γ).
Expanding φ :
φ(γ) =
∞
i=0
φihi(γ), (2)
where hi(z) is the i-th Hermite polynomial.
[see PhD of E. Zander 2013, or PhD of A. Keese, 2005]
Connection of cov. matrices for κ(x, ω) and γ(x, ω):
covκ(x, y) ≈
Q
i=0
i!φ2
i covi
γ(x, y). (3)
Solving for covγ(x, y) [E. Zander, 13], obtain:
γ(x, ω) =
∞
m=1
gm(x)θm(ω),
D
covγ(x, y)gm(y)dy = λmgm(x). (4)
KLE is the series
κ(x, ω) = µk(x) +
∞
i=1
λiki(x)ξi(ω), where
ξi(ω) are uncorrelated random variables and ki are basis func-
tions in L2(G).
3.1 TT compression of PCE coeffs
PCE of κ writes
κ(x, ω) ≈
α∈JM
κα(x)Hα(θ(ω)), Hα(θ) := hα1(θ1) · · · hαM (θM) (5)
JM,p = {0, 1, . . . , p1}⊗· · ·⊗{0, 1, . . . , pM}, where p = (p1, . . . , pM)
J
sp
M,p = {α = (α1, . . . , αM) : α ≥ 0, α1 + · · · + αM ≤ p} .
|JM,p| := (p + 1)M, |J
sp
M,p| :=
(p + M)!
p!M!
.
The Galerkin coefficients κα are evaluated as follows [Thm 3.10,
PhD of E. Zander 13],
κα(x) =
(α1 + · · · + αM)!
α1! · · · αM!
φα1+···+αM
M
m=1
gαm
m (x), (6)
where φ|α| := φα1+···+αM is the coefficient of the transform func-
tion in (2), and gαm
m (x) means the αm-th power of gm(x) in (4).
3.2 Complexity reduction
Complexity reduction in Eq. (6) can be achieved via KLE for
κ(x, ω):
κ(x, ω) = ¯κ(x) +
∞
=1
√
µ v (x)η (ω) (7)
Instead of using (6) directly, we compute (L N)
˜κα( ) =
(α1 + · · · + αM)!
α1! · · · αM!
φα1+···+αM
D
M
m=1
gαm
m (x)v (x)dx. (8)
Then we restore coefficients in (5):
κα(x) ≈ ¯κ(x) +
L
=1
v (x)˜κα( ). (9)
3.3 Construction of stochastic Galerkin operator
Given (7), assemble for i, j = 1, . . . , N, = 1, . . . , L:
K (i, j) =
D
v (x) ϕi(x) · ϕj(x)dx, (10)
Take ˜κα( ) and integrate over θ:
Kα,β( ) =
RM
Hα(θ)Hβ(θ)
γ∈JM,p
κγ( )Hγ(θ)dθ =
γ∈JM,p
∆α,β,γκγ( ),
(11)
where
∆α,β,γ = ∆α1,β1,γ1
· · · ∆αM,βM,γM
, (12)
∆αm,βm,γm
=
R
hαm(z)hβm
(z)hγm(z)dz, (13)
is the triple product of the Hermite polynomials.
3.4 Stochastic Galerkin operator
Putting together (9)-(11), obtain the discrete stochastic Galerkin
operator,
K = K0 ⊗ ∆0 +
L
=1
K ⊗
γ∈JM,p
∆γ˜κγ( ), (14)
K ∈ RN(p+1)M
×N(p+1)M
in case of full JM,p.
4. Tensor Train Format
Examples (Oseledets, Khoromskij,Tyrtyshnikov et al.):
f(x1, ..., xd) = w1(x1) + w2(x2) + ... + wd(xd)
= (w1(x1), 1)
1 0
w2(x2) 1
...
1 0
wd−1(xd−1) 1
1
wd(xd)
f = sin(x1 + x2 + ... + xd)
= (sin x1, cos x1)
cos x2 − sin x2
sin x2 cos x2
...
cos xd−1 − sin xd−1
sin xd−1 cos xd−1
cos xd
sin xd−1
4.1 Tensor Train decomposition
u(α1, . . . , αM) =
r1
s1=1
r2
s2=1
· · ·
rM−1
sM−1=1
u
(1)
s1
(α1)u
(2)
s1,s2
(α2) · · · u
(M)
sM−1
(αM),
= u(1)(α1)u(2)(α2) · · · u(M)(αM),
(15)
Each TT core u(k) = [u
(k)
sk−1,sk
(αk)] is defined by rk−1nkrk num-
bers, where nk is number of grid points (e.g. nk = pk+1) in the αk
direction, and rk is the TT rank, O(Mnr2) entries, r = max{rk}.
4.2 Cross Interpolation in high-dim. case
Calculation of (8) in tensor formats needs:
• given a procedure to compute each element of tensor ˜κα1,...,αM .
• build a TT approximation ˜κα ≈ κ(1)(α1) · · · κ(M)(αM) using a
feasible amount of elements (i.e. much less than (p + 1)M).
Initial expansion (9) becomes:
˜κα( ) =
s1,...,sM−1
κ
(1)
,s1
(α1) · · · κ
(M)
sM−1
(αM). (16)
PCE Eq. (5) writes as the following TT format,
κα(x) =
,s1,...,sM−1
κ
(0)
(x)κ
(1)
,s1
(α1) · · · κ
(M)
sM−1
(αM), (17)
4.3 Stochastic Galerkin matrix in TT format
Given (17), we split the whole sum over γ in (14):
γ∈JM,p
∆γ ˜κγ( ) =
s1,...,sM−1
p
γ1=0
∆γ1κ
(1)
,s1
(γ1)
⊗ · · · ⊗
p
γM=0
∆γM
κ(M)
sM−1
(γM)
.
Introduce
K(0)
(i, j) := K
(0)
(i, j)
L
=0
= K0(i, j) K1(i, j) · · · KL(i, j) , i, j = 1, . . . , N,
K
(m)
sm−1,sm := p
γm=0 ∆γmκ
(m)
sm−1,sm(γm) for m = 1, . . . , M,
then the TT representation writes
K =
,s1,...,sM−1
K
(0)
⊗ K
(1)
,s1
⊗ · · · ⊗ K(M)
sM−1
∈ R(N·#JM,p)×(N·#JM,p)
, (18)
5. Numerics
Sparse TT
p M 10 20 30 10 20 30
1 0.29 0.3 0.3 3.6 68 617
2 0.30 0.4 0.4 6.3 138 1373
3 0.33 0.5 1 9 229 2423
4 0.45 1.8 6 11 322 3533
5 1.13 7.7 47 14 430 4937
CPU times (sec.) to assembly coefficient κ
Sparse TT
p M 10 20 30 10 20 30
1 0.1 0.2 0.3 0.11 0.21 0.38
2 0.1 2.1 26 0.11 0.22 0.54
3 2.2 735 — 0.12 0.27 0.84
4 82 — — 0.12 0.28 1.08
5 3444 — — 0.2 0.35 1.18
CPU times (sec.) of the operator K assembly
Sparse TT
p M 10 20 30 10 20 30
1 0.2 1.2 0.5 1.1 9 51
2 0.3 2.1 3.2 1.7 27 173
3 0.8 14 — 2.7 56 392
4 5.8 — — 7.2 143 1497
5 61.6 — — 45 866 5363
CPU times (sec.) of the solution.
Sparse TT
p M 10 20 30 10 20 30
1 9.5e-2 8.9e-2 9.7e-2 4.2e-2 2.8e-2 2.6e-2
2 3.5e-3 2.7e-3 3.3e-3 1e-4 1.3e-4 2.1e-4
3 1.7e-4 2.8e-4 — 4.5e-5 1.3e-4 2.1e-4
4 8.6e-5 — — 6.3e-5 1.3e-4 1.1e-4
Errors in the solution covariance matrices
| covu − covu | =
i,j(covu − covu)2
i,j
i,j(covu)2
i,j
.
The reference covariance matrix covu ∈ RN×N
is computed in the TT format
with p = 5.
Acknowledgements
A. Litvinenko is a member of the KAUST SRI UQ Center.
References
1. S Dolgov, BN Khoromskij, A Litvinenko, HG Matthies, Computation of the
Response Surface in the Tensor Train data format, arXiv:1406.2816, 2014
2. M Espig, W Hackbusch, A Litvinenko, HG Matthies, E Zander, Efficient
analysis of high dimensional data in tensor formats, Sparse Grids and Appli-
cations, 31-56, 2013
3. M Espig, W Hackbusch, A Litvinenko, HG Matthies, P W¨ahnert, Efficient
low-rank approximation of the stochastic Galerkin matrix in tensor formats
Computers & Mathematics with Applications, 2012](https://image.slidesharecdn.com/12litvinenko-170311122150/85/Response-Surface-in-Tensor-Train-format-for-Uncertainty-Quantification-1-320.jpg)
![Center for Uncertainty
Quantification
Response Surface in Tensor Train
Format for Uncertainty Quantification
Alexander Litvinenko1
, S. Dolgov2
, B. Khoromskij2
, H. G. Matthies3
1
KAUST, 2
MPI for Mathematics in the Sciences, Leipzig, 3
TU Braunschweig
alexander.litvinenko@kaust.edu.sa
Center for Uncertainty
Quantification
Center for Uncertainty
Quantification
1. Motivation
• To reduce computational time from days to hours, to minutes.
• To reduce required storage cost from GB to MB or KB’s.
• UQ: Computational algorithms, run on supercomputers, can
simulate and resolve very complex phenomena. But how reli-
able are these predictions? Can we trust to these results?
Some parameters are unknown, lack of data, very few mea-
surements → uncertainty.
Abstract
• Applied Tensor Train (TT) approximation to stochas-
tic Galerkin matrix,
• Solved SPDE in TT,
• Compared 2 strategies of PCE: sparse and full poly-
nomial (multi-index) sets.
• Evaluated mean, variance, Sobol indicesin TT for-
mat.
Plan:
• Interpolate PCE coefficients in TT format via block
cross approximation method
• Approximate operator in TT format
• Solve discretized equation via alternating minimal
energy algorithm.
2. Take to home
1. Compute solution of SPDE in TT format.
2. Post-processing: the mean value, covariance, Sobol
indices, level sets in the TT data format.
3. TT becomes preferable for high polynomial order p.
4. The TT approach scales linearly with p.
3. Modell and discretisation
− div(κ(x, ω) u(x, ω)) = f(x, ω) in G × Ω, G ⊂ R2
,
u = 0 on ∂G,
(1)
where κ(x, ω) = eγ(x,ω)
.
Compute in TT format:
1. PCE of κ(x, ω)
2. Stochastic Galerkin matrix K
3. Solution of the linear system u = K−1
f
4. Statistics, Sobol indices, max element,level sets
We assume κ = φ(γ) -a smooth transformation of the
Gaussian random field γ(x, ω), e.g. φ(γ) = exp(γ).
Expanding φ :
φ(γ) =
∞
i=0
φihi(γ), (2)
where hi(z) is the i-th Hermite polynomial.
[see PhD of E. Zander 2013, or PhD of A. Keese, 2005]
Connection of cov. matrices for κ(x, ω) and γ(x, ω):
covκ(x, y) ≈
Q
i=0
i!φ2
i covi
γ(x, y). (3)
Solving for covγ(x, y) [E. Zander, 13], obtain:
γ(x, ω) =
∞
m=1
gm(x)θm(ω),
D
covγ(x, y)gm(y)dy = λmgm(x). (4)
KLE is the series
κ(x, ω) = µk(x) +
∞
i=1
λiki(x)ξi(ω), where
ξi(ω) are uncorrelated random variables and ki are basis func-
tions in L2(G).
3.1 TT compression of PCE coeffs
PCE of κ writes
κ(x, ω) ≈
α∈JM
κα(x)Hα(θ(ω)), Hα(θ) := hα1(θ1) · · · hαM (θM) (5)
JM,p = {0, 1, . . . , p1}⊗· · ·⊗{0, 1, . . . , pM}, where p = (p1, . . . , pM)
J
sp
M,p = {α = (α1, . . . , αM) : α ≥ 0, α1 + · · · + αM ≤ p} .
|JM,p| := (p + 1)M, |J
sp
M,p| :=
(p + M)!
p!M!
.
The Galerkin coefficients κα are evaluated as follows [Thm 3.10,
PhD of E. Zander 13],
κα(x) =
(α1 + · · · + αM)!
α1! · · · αM!
φα1+···+αM
M
m=1
gαm
m (x), (6)
where φ|α| := φα1+···+αM is the coefficient of the transform func-
tion in (2), and gαm
m (x) means the αm-th power of gm(x) in (4).
3.2 Complexity reduction
Complexity reduction in Eq. (6) can be achieved via KLE for
κ(x, ω):
κ(x, ω) = ¯κ(x) +
∞
=1
√
µ v (x)η (ω) (7)
Instead of using (6) directly, we compute (L N)
˜κα( ) =
(α1 + · · · + αM)!
α1! · · · αM!
φα1+···+αM
D
M
m=1
gαm
m (x)v (x)dx. (8)
Then we restore coefficients in (5):
κα(x) ≈ ¯κ(x) +
L
=1
v (x)˜κα( ). (9)
3.3 Construction of stochastic Galerkin operator
Given (7), assemble for i, j = 1, . . . , N, = 1, . . . , L:
K (i, j) =
D
v (x) ϕi(x) · ϕj(x)dx, (10)
Take ˜κα( ) and integrate over θ:
Kα,β( ) =
RM
Hα(θ)Hβ(θ)
γ∈JM,p
κγ( )Hγ(θ)dθ =
γ∈JM,p
∆α,β,γκγ( ),
(11)
where
∆α,β,γ = ∆α1,β1,γ1
· · · ∆αM,βM,γM
, (12)
∆αm,βm,γm
=
R
hαm(z)hβm
(z)hγm(z)dz, (13)
is the triple product of the Hermite polynomials.
3.4 Stochastic Galerkin operator
Putting together (9)-(11), obtain the discrete stochastic Galerkin
operator,
K = K0 ⊗ ∆0 +
L
=1
K ⊗
γ∈JM,p
∆γ˜κγ( ), (14)
K ∈ RN(p+1)M
×N(p+1)M
in case of full JM,p.
4. Tensor Train Format
Examples (Oseledets, Khoromskij,Tyrtyshnikov et al.):
f(x1, ..., xd) = w1(x1) + w2(x2) + ... + wd(xd)
= (w1(x1), 1)
1 0
w2(x2) 1
...
1 0
wd−1(xd−1) 1
1
wd(xd)
f = sin(x1 + x2 + ... + xd)
= (sin x1, cos x1)
cos x2 − sin x2
sin x2 cos x2
...
cos xd−1 − sin xd−1
sin xd−1 cos xd−1
cos xd
sin xd−1
4.1 Tensor Train decomposition
u(α1, . . . , αM) =
r1
s1=1
r2
s2=1
· · ·
rM−1
sM−1=1
u
(1)
s1
(α1)u
(2)
s1,s2
(α2) · · · u
(M)
sM−1
(αM),
= u(1)(α1)u(2)(α2) · · · u(M)(αM),
(15)
Each TT core u(k) = [u
(k)
sk−1,sk
(αk)] is defined by rk−1nkrk num-
bers, where nk is number of grid points (e.g. nk = pk+1) in the αk
direction, and rk is the TT rank, O(Mnr2) entries, r = max{rk}.
4.2 Cross Interpolation in high-dim. case
Calculation of (8) in tensor formats needs:
• given a procedure to compute each element of tensor ˜κα1,...,αM .
• build a TT approximation ˜κα ≈ κ(1)(α1) · · · κ(M)(αM) using a
feasible amount of elements (i.e. much less than (p + 1)M).
Initial expansion (9) becomes:
˜κα( ) =
s1,...,sM−1
κ
(1)
,s1
(α1) · · · κ
(M)
sM−1
(αM). (16)
PCE Eq. (5) writes as the following TT format,
κα(x) =
,s1,...,sM−1
κ
(0)
(x)κ
(1)
,s1
(α1) · · · κ
(M)
sM−1
(αM), (17)
4.3 Stochastic Galerkin matrix in TT format
Given (17), we split the whole sum over γ in (14):
γ∈JM,p
∆γ ˜κγ( ) =
s1,...,sM−1
p
γ1=0
∆γ1κ
(1)
,s1
(γ1)
⊗ · · · ⊗
p
γM=0
∆γM
κ(M)
sM−1
(γM)
.
Introduce
K(0)
(i, j) := K
(0)
(i, j)
L
=0
= K0(i, j) K1(i, j) · · · KL(i, j) , i, j = 1, . . . , N,
K
(m)
sm−1,sm := p
γm=0 ∆γmκ
(m)
sm−1,sm(γm) for m = 1, . . . , M,
then the TT representation writes
K =
,s1,...,sM−1
K
(0)
⊗ K
(1)
,s1
⊗ · · · ⊗ K(M)
sM−1
∈ R(N·#JM,p)×(N·#JM,p)
, (18)
5. Numerics
Sparse TT
p M 10 20 30 10 20 30
1 0.29 0.3 0.3 3.6 68 617
2 0.30 0.4 0.4 6.3 138 1373
3 0.33 0.5 1 9 229 2423
4 0.45 1.8 6 11 322 3533
5 1.13 7.7 47 14 430 4937
CPU times (sec.) to assembly coefficient κ
Sparse TT
p M 10 20 30 10 20 30
1 0.1 0.2 0.3 0.11 0.21 0.38
2 0.1 2.1 26 0.11 0.22 0.54
3 2.2 735 — 0.12 0.27 0.84
4 82 — — 0.12 0.28 1.08
5 3444 — — 0.2 0.35 1.18
CPU times (sec.) of the operator K assembly
Sparse TT
p M 10 20 30 10 20 30
1 0.2 1.2 0.5 1.1 9 51
2 0.3 2.1 3.2 1.7 27 173
3 0.8 14 — 2.7 56 392
4 5.8 — — 7.2 143 1497
5 61.6 — — 45 866 5363
CPU times (sec.) of the solution.
Sparse TT
p M 10 20 30 10 20 30
1 9.5e-2 8.9e-2 9.7e-2 4.2e-2 2.8e-2 2.6e-2
2 3.5e-3 2.7e-3 3.3e-3 1e-4 1.3e-4 2.1e-4
3 1.7e-4 2.8e-4 — 4.5e-5 1.3e-4 2.1e-4
4 8.6e-5 — — 6.3e-5 1.3e-4 1.1e-4
Errors in the solution covariance matrices
| covu − covu | =
i,j(covu − covu)2
i,j
i,j(covu)2
i,j
.
The reference covariance matrix covu ∈ RN×N
is computed in the TT format
with p = 5.
Acknowledgements
A. Litvinenko is a member of the KAUST SRI UQ Center.
References
1. S Dolgov, BN Khoromskij, A Litvinenko, HG Matthies, Computation of the
Response Surface in the Tensor Train data format, arXiv:1406.2816, 2014
2. M Espig, W Hackbusch, A Litvinenko, HG Matthies, E Zander, Efficient
analysis of high dimensional data in tensor formats, Sparse Grids and Appli-
cations, 31-56, 2013
3. M Espig, W Hackbusch, A Litvinenko, HG Matthies, P W¨ahnert, Efficient
low-rank approximation of the stochastic Galerkin matrix in tensor formats
Computers & Mathematics with Applications, 2012](https://image.slidesharecdn.com/12litvinenko-170311122150/75/Response-Surface-in-Tensor-Train-format-for-Uncertainty-Quantification-1-2048.jpg)