This document discusses the computation of f-divergences and distances for high-dimensional probability density functions (PDFs) using techniques from stochastic analysis, such as Karhunen-Loève and polynomial chaos expansions. It highlights methods for calculating Kullback-Leibler divergence and other entropy measures when PDFs are either unknown or do not exist. Additionally, it presents various algorithms, tensor representations, and numerical examples to demonstrate the computational efficiency and effectiveness of the approaches presented.





![Connection of pcf and pdf
The probability characteristic function (pcf ) ϕξ could be
defined:
ϕξ(t) := E(exp(ihξ|ti)) :=
Z
Rd
pξ(y)exp(ihy|ti) dy =: F [d]
(pξ)(t),
where t = (t1,t2,...,td) ∈ Rd is the dual variable to y ∈ Rd,
hy|ti =
Pd
j=1 yjtj is the canonical inner product on Rd, and F [d]
is the probabilist’s d-dimensional Fourier transform.
pξ(y) =
1
(2π)d
Z
Rd
exp(−iht|yi)ϕξ(t)dt = F [−d]
(ϕξ)(y). (3)
6 / 30](https://image.slidesharecdn.com/litvinenkosiamlowranktensorapproximationofprobabilitydensityandcharacteristicfunctions-220512190031-da508682/85/Computing-f-Divergences-and-Distances-of-High-Dimensional-Probability-Density-Functions-7-320.jpg)
![Discrete low-rank representation of pcf
We try to find an approximation
ϕξ(t) ≈ e
ϕξ(t) =
R
X
`=1
d
O
ν=1
ϕ`,ν(tν), (4)
where the ϕ`,ν(tν) are one-dimensional functions.
Then we can get
pξ(y) ≈ e
pξ(y) = F [−d]
(ϕξ)y =
R
X
`=1
d
O
ν=1
F −1
1 (ϕ`,ν)(yν),
where F −1
1 is the one-dimensional inverse Fourier transform.
7 / 30](https://image.slidesharecdn.com/litvinenkosiamlowranktensorapproximationofprobabilitydensityandcharacteristicfunctions-220512190031-da508682/85/Computing-f-Divergences-and-Distances-of-High-Dimensional-Probability-Density-Functions-8-320.jpg)
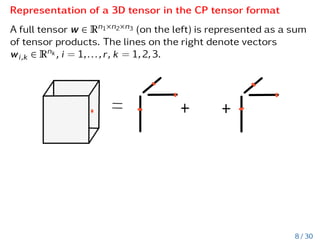


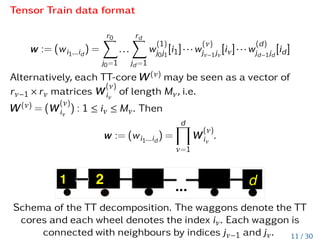


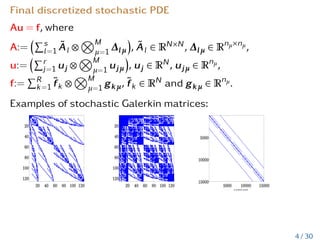
![Tensor Train data format
w := (wi1...id
) =
r0
X
j0=1
...
rd
X
jd=1
w
(1)
j0j1
[i1]···w
(ν)
jν−1jν
[iν]···w
(d)
jd−1jd
[id]
Alternatively, each TT-core W(ν)
may be seen as a vector of
rν−1 × rν matrices W
(ν)
iν
of length Mν, i.e.
W(ν)
= (W
(ν)
iν
) : 1 ≤ iν ≤ Mν. Then
w := (wi1...id
) =
d
Y
ν=1
W
(ν)
iν
.
Schema of the TT decomposition. The waggons denote the TT
cores and each wheel denotes the index iν. Each waggon is
connected with neighbours by indices jν−1 and jν. 11 / 30](https://image.slidesharecdn.com/litvinenkosiamlowranktensorapproximationofprobabilitydensityandcharacteristicfunctions-220512190031-da508682/85/Computing-f-Divergences-and-Distances-of-High-Dimensional-Probability-Density-Functions-15-320.jpg)






![List of some typical divergences and distances
Divergence D•(pkq)
KLD
Z
(log(p(x)/q(x)))p(x) dx
Hellinger dist.
1
2
Z q
p(x) −
q
q(x)
2
dx
Bregman div.
Z
[(φ(p(x)) − φ(q(x))) − (p(x) − q(x))φ0
(q(x))] dx
Bhattacharyya −log
Z q
(p(x)q(x)) dx
!
List of some typical divergences and distances.
13 / 30](https://image.slidesharecdn.com/litvinenkosiamlowranktensorapproximationofprobabilitydensityandcharacteristicfunctions-220512190031-da508682/85/Computing-f-Divergences-and-Distances-of-High-Dimensional-Probability-Density-Functions-22-320.jpg)