Download as PDF, PPTX


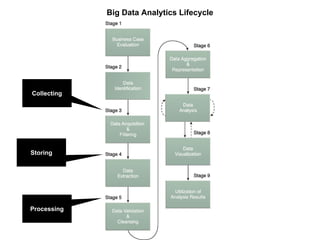
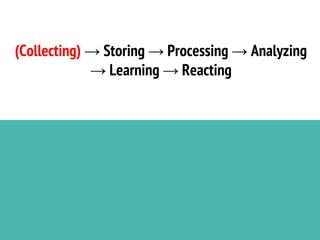
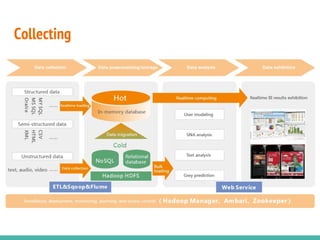

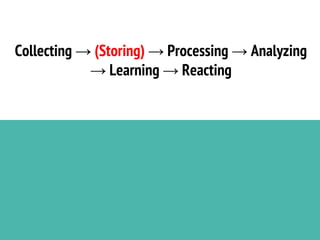

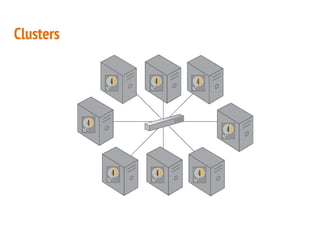
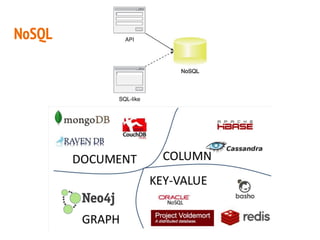
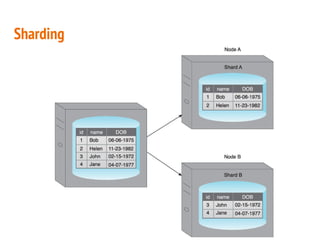
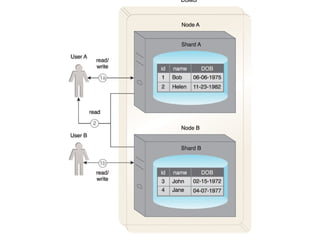
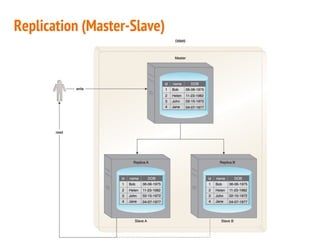
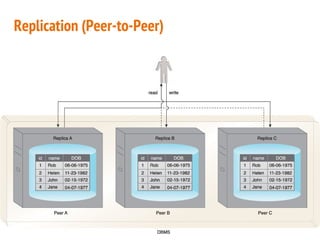
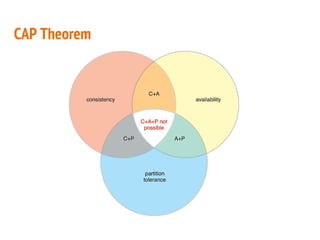
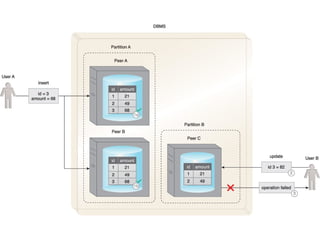
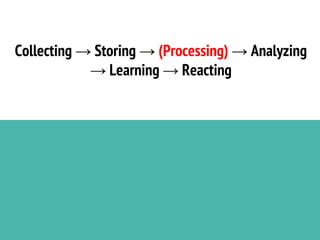

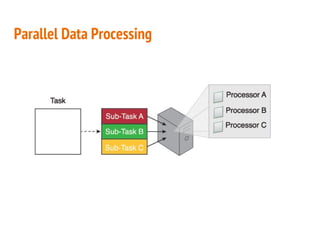
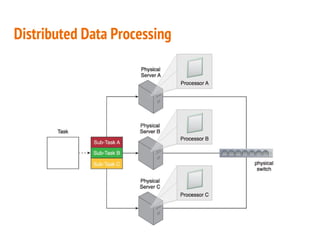
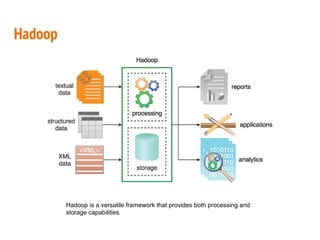
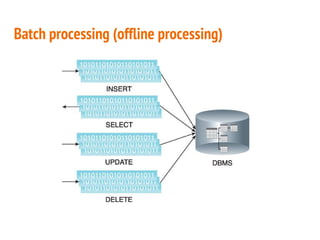
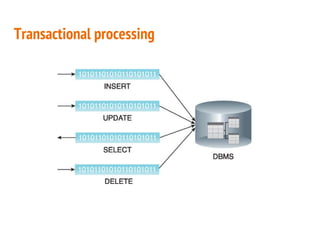
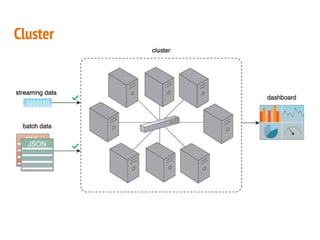
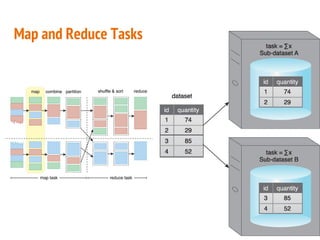
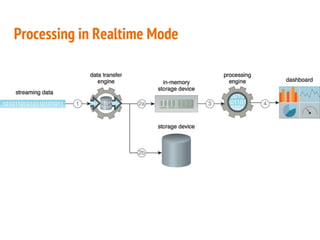




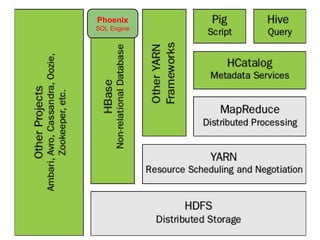

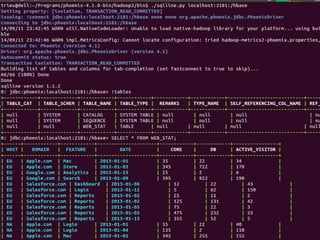
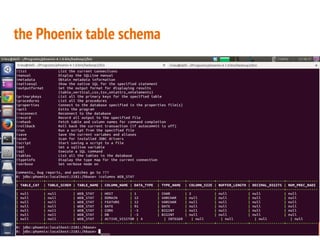
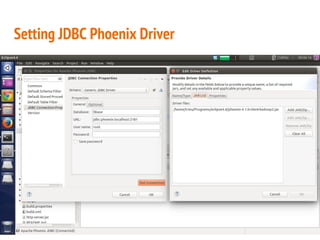
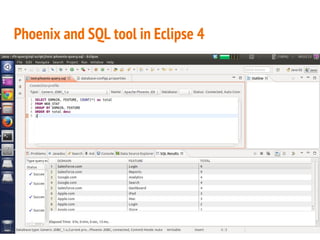
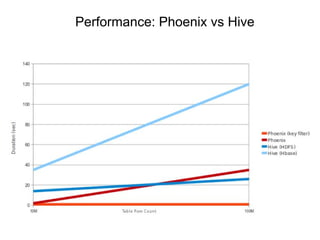


This document discusses the process of collecting, storing, processing and analyzing big data. It covers the key concepts and technologies for collecting data using tools like Apache Sqoop and Kafka, storing data using clusters, file systems, NoSQL databases and concepts like sharding and replication. It also discusses processing data using parallel and distributed processing with Hadoop, and analyzing data using Apache Phoenix which provides a SQL interface to query HBase databases.







































































![[Notes] Customer 360 Analytics with LEO CDP](https://cdn.slidesharecdn.com/ss_thumbnails/notescustomer360analyticswithleocdp-220126053232-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)








