Download to read offline





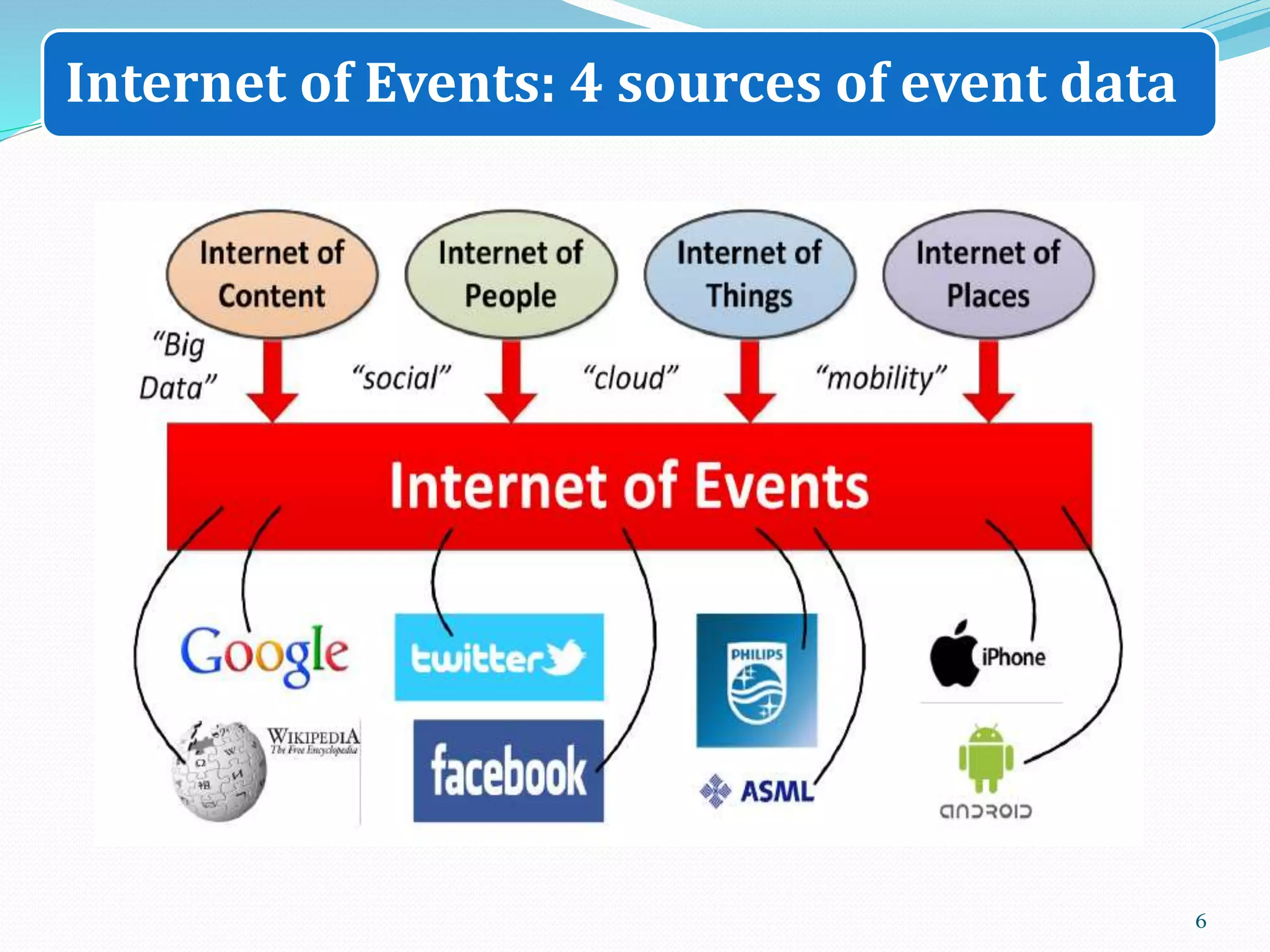




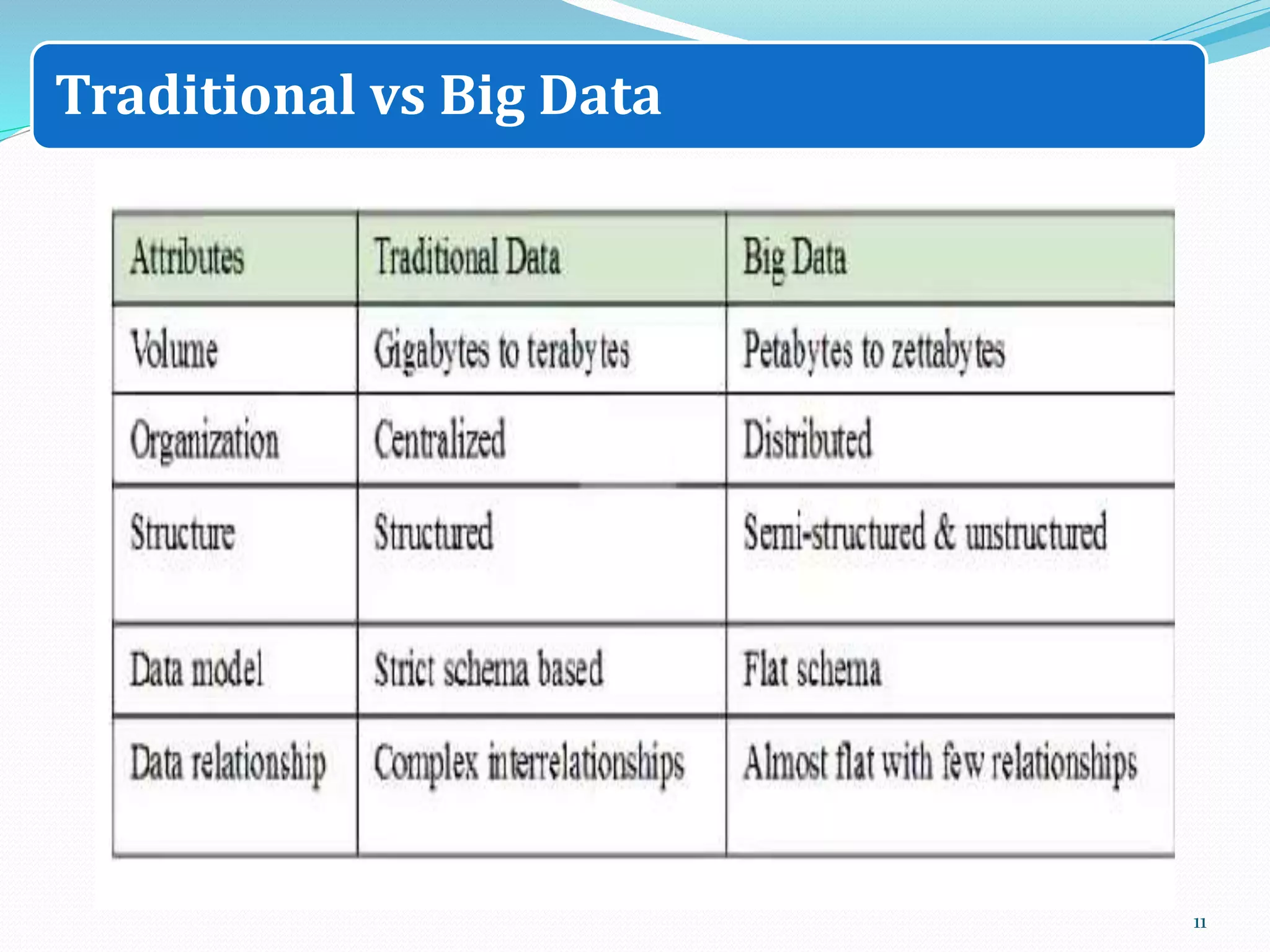



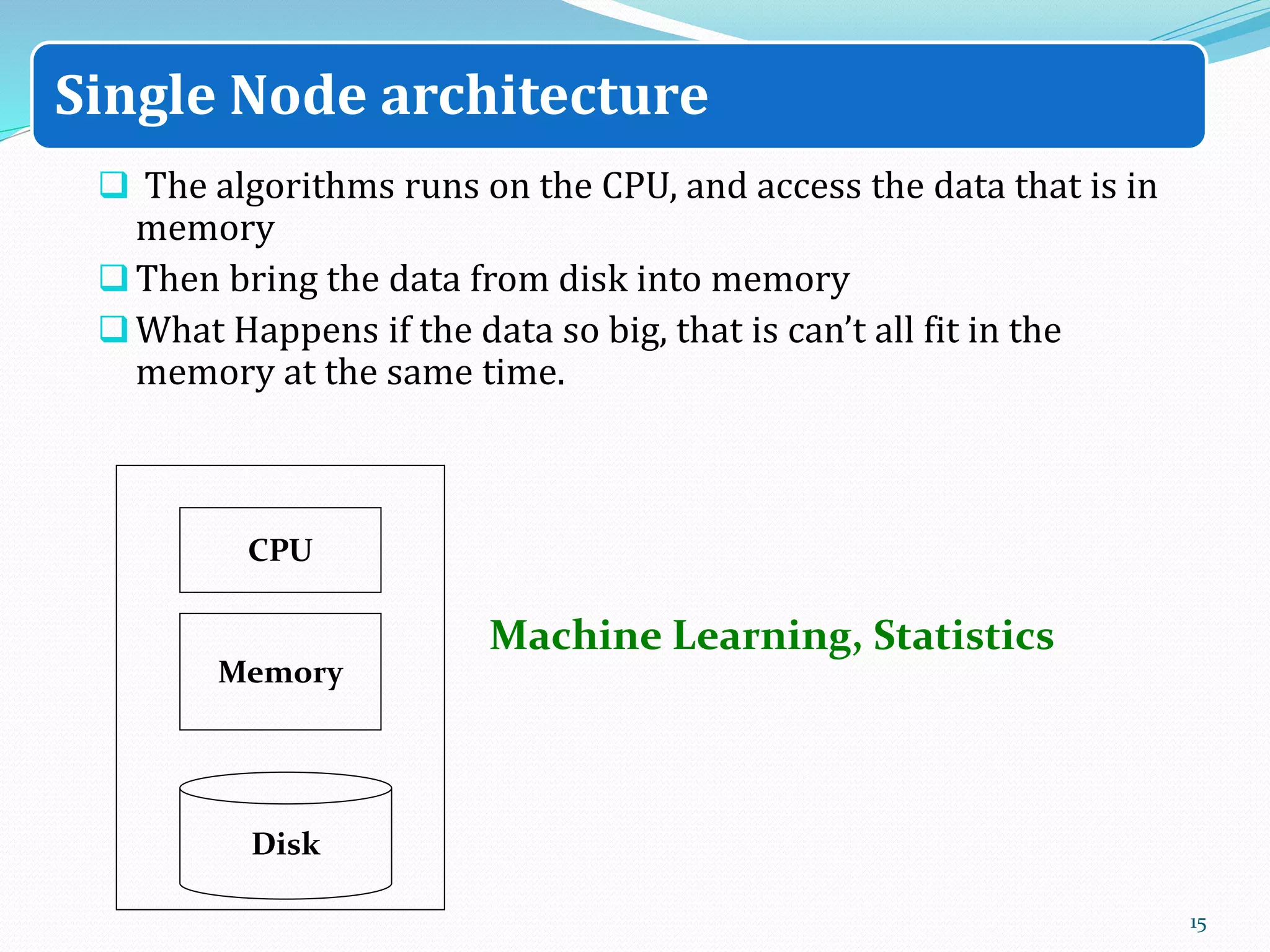

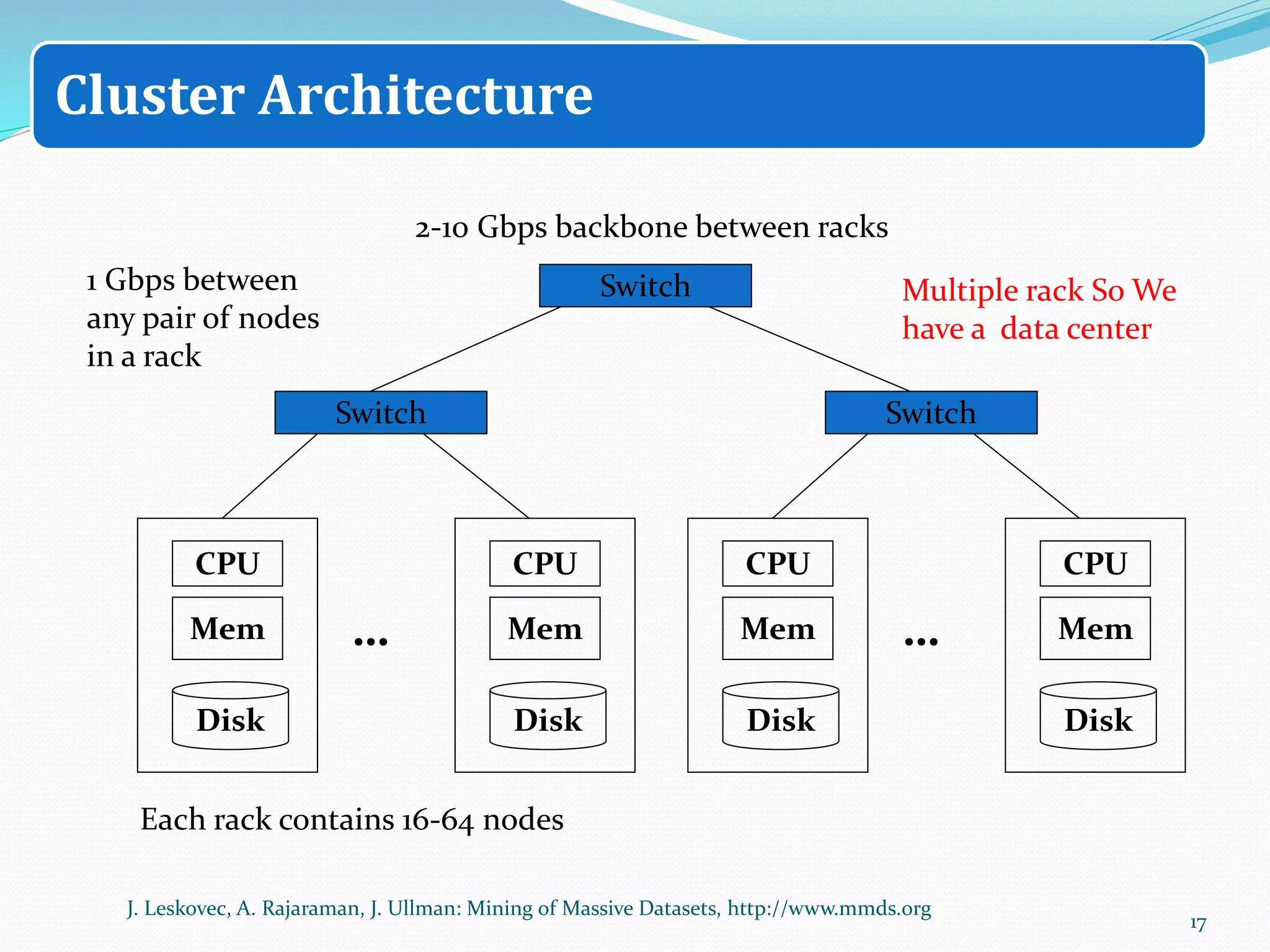





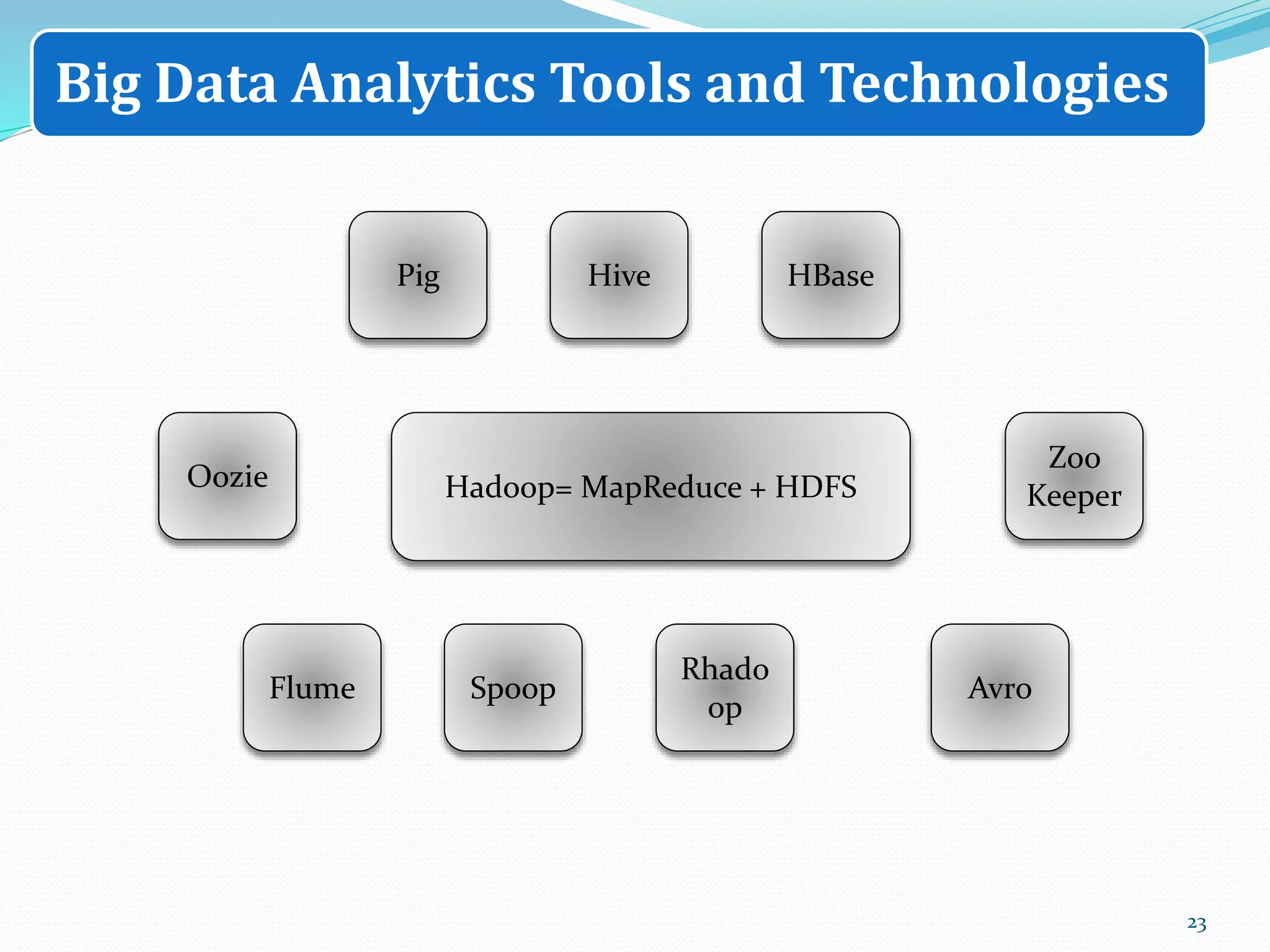


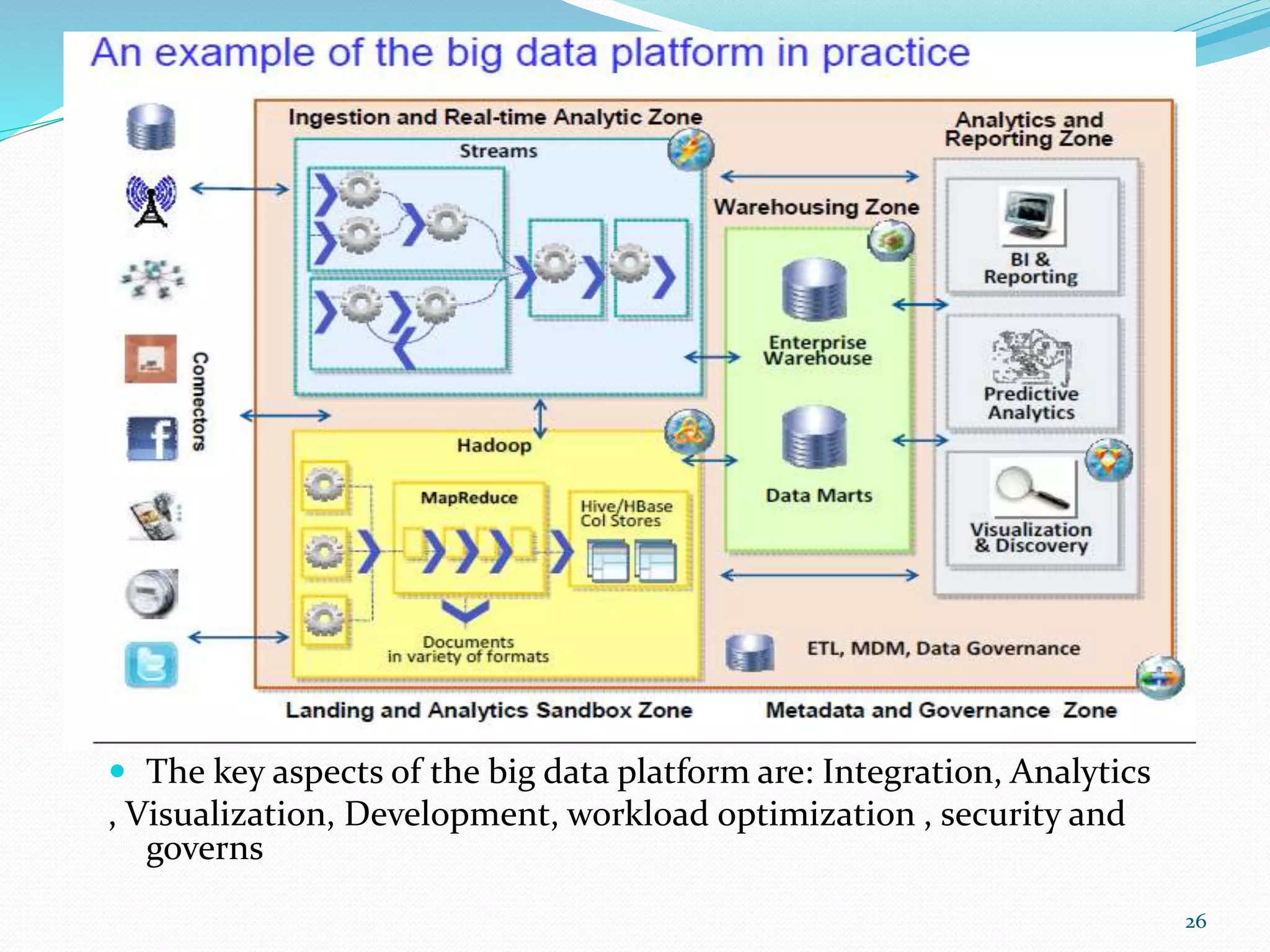



The document discusses big data sources, challenges, and analytics. It describes how big data is too large to be managed by traditional databases due to its volume, velocity, variety, and veracity. Big data comes from sources like web pages, social media, sensors, and financial transactions. Analyzing big data requires distributed computing across clusters of servers to store and process the data in parallel. Frameworks like MapReduce and Hadoop were developed to perform big data analytics across clusters and address challenges of node failures, network bottlenecks, and distributed programming.




















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













