






![Questions? Thank you. http://www.webarchive.org.uk [email_address] @relephantdata](https://image.slidesharecdn.com/bcsuse-13219877736911-phpapp02-111122125159-phpapp02/85/Analytics-and-Access-to-the-UK-web-archive-20-320.jpg)

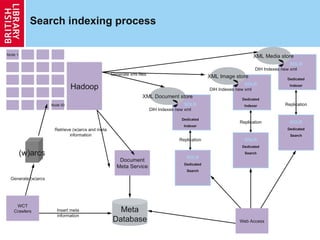
The document summarizes the background, purpose, and methods of the UK Web Archive. It discusses how the archive collects, stores, and provides access to snapshots of UK websites over time to preserve digital cultural heritage. It also describes challenges of scale due to the immense size of web content and techniques like full-text search and data analytics that are used to facilitate discovery of information within the archive.















































