Download to read offline



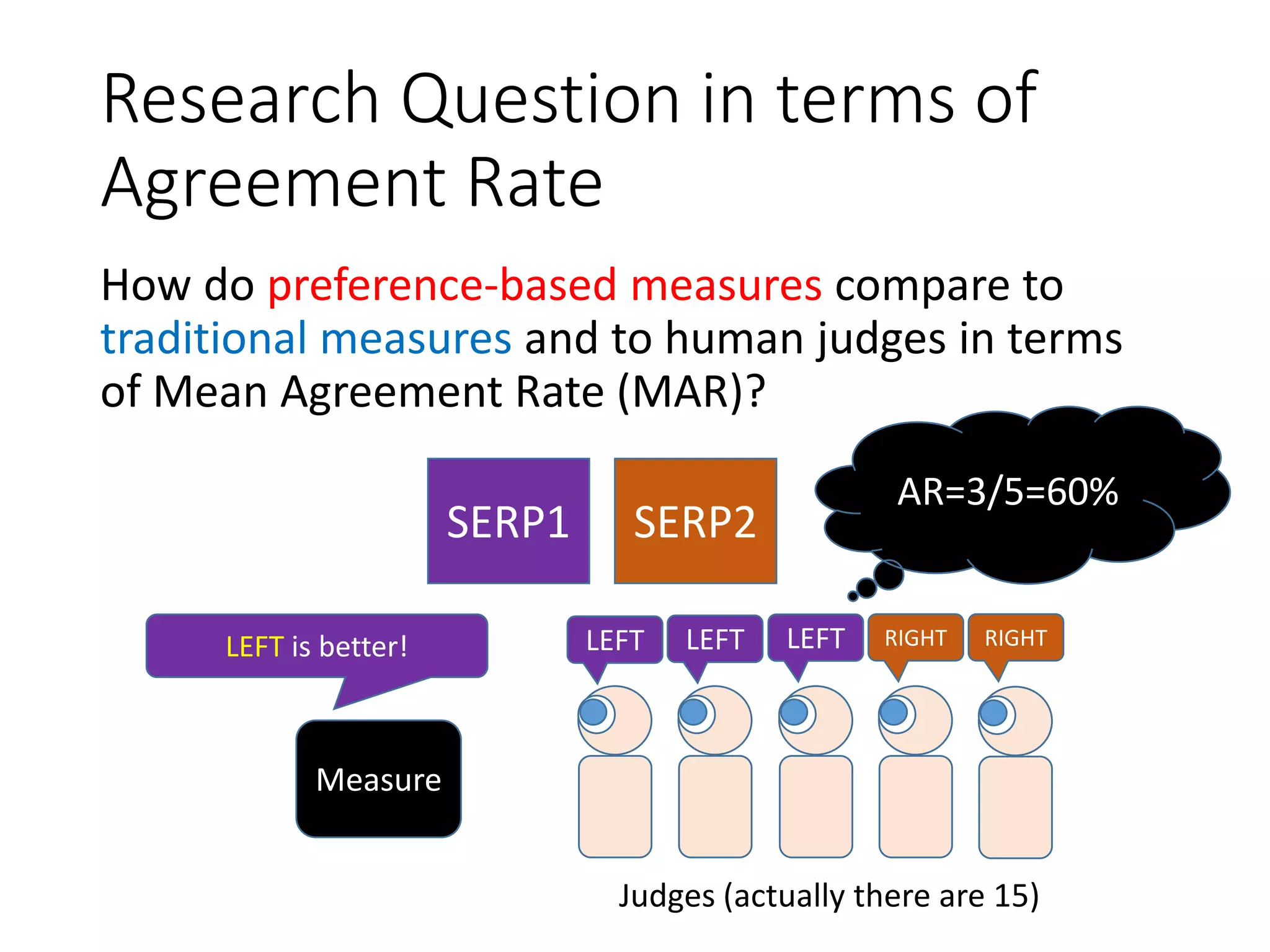
![Some say we should move from absolute
graded relevance assessments to pairwise
preference assessments because...
• It is difficult to pre-define relevance grades.
• Assessor burden increases with #grades.
• Preferences can be used directly for learning-to-
rank.
Assessment cost with preferences is quadratic, but
some have explored methods to reduce it.
See [Carterette+08ECIR] etc.
See [Bashir+13SIGIR,Hui/Berberich17ICTIR,
Radinsky/Ailon11WSDM] etc.](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-4-2048.jpg)
![Few studies on preference-based
evaluation measures
[Frei/Schauble91IPM] Set retrieval measures, not
ranked retrieval ones; their measures do not provide
an absolute score to a SERP.
[Carterette/Bennett08SIGIR] wpref (nDCG-like),
appref (Average Precision-like) etc.
But do preference-based measures actually align
with users’ SERP preferences? Measures are used
as surrogates of user satisfaction etc. so we should
check that they do!](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-5-2048.jpg)

![NTCIR-9 INTENT Japanese subtask
[Sakai/Song13IRJ]
100 topics
Qrels
(diversity)
15 runs
Diversified search topics
(with intent probabilities)
Not available in TREC diversity topics
intentwise graded
relevance (L0-L4)
Target corpus:
clueweb09-JA](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-8-2048.jpg)
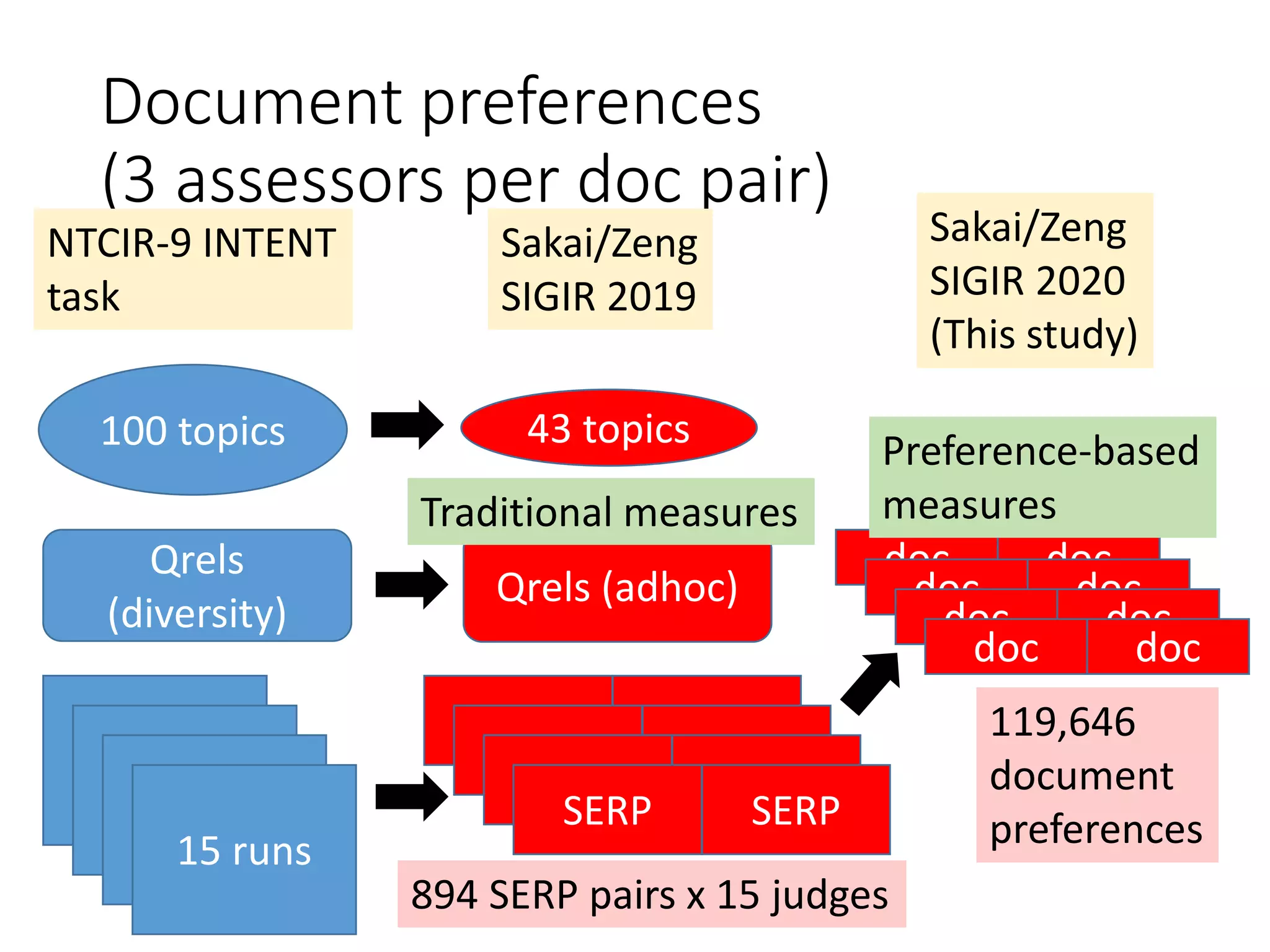
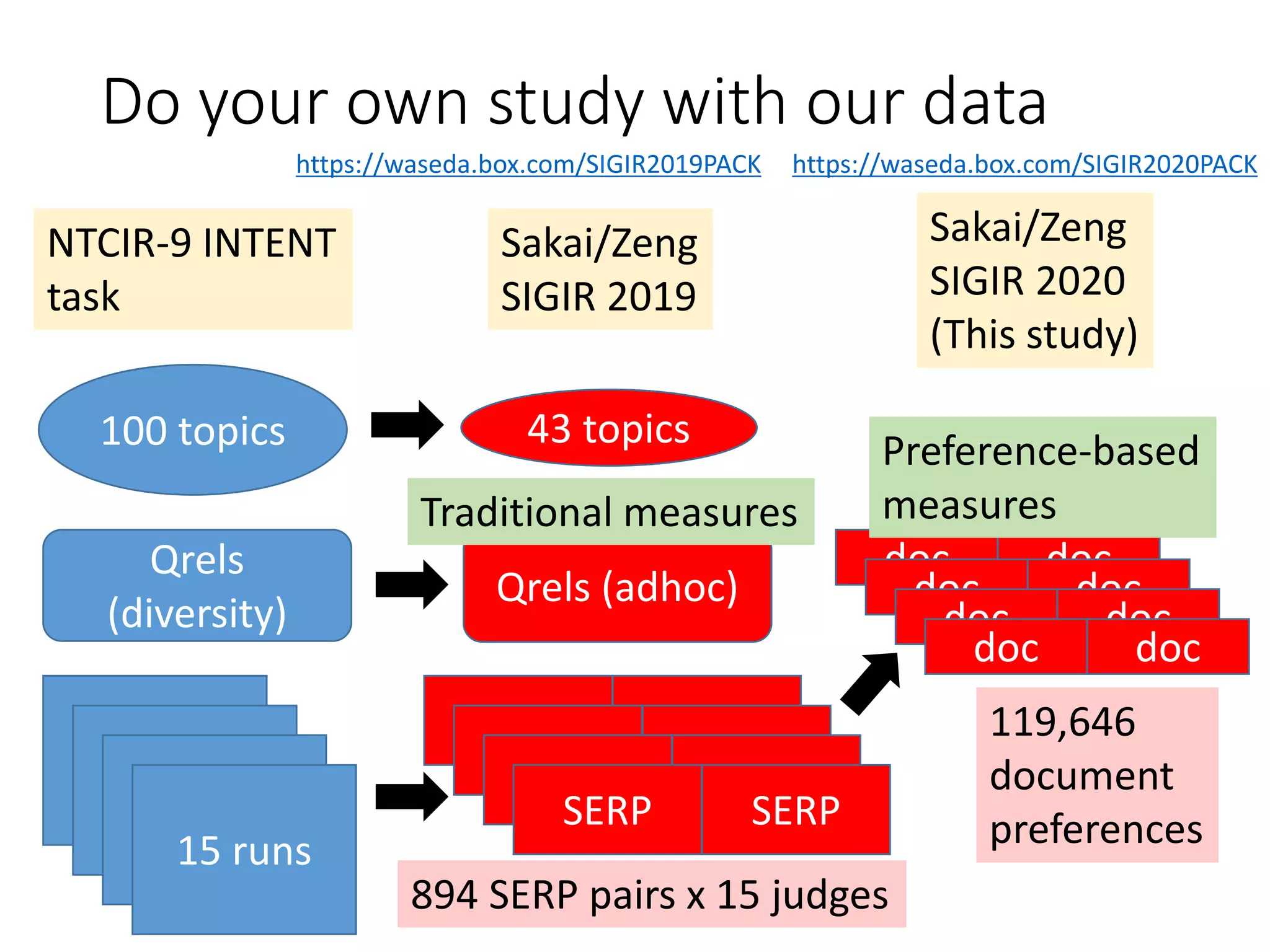
![SERP preferences from
[Sakai/Zeng19SIGIR]
NTCIR-9 INTENT
task
43 topics100 topics
Qrels
(diversity)
15 runs
SERP SERP
SERP SERP
SERP SERP
SERP SERP
Qrels (adhoc)
894 SERP pairs x 15 judges
9+ judges agreed as to
which SERP is more
relevant
Topicwise graded relevance
(L0-L4) derived
relevance and diversity
preferences collected but
we (SIGIR2020) use the
SERP relevance
preferences](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-9-2048.jpg)

![Traditional measures based on
absolute graded relevance
• nDCG [Jarvelin/Kekalainen02TOIS]
• Normalised Cumulative Utility
[Sakai/Robertson08EVIA]
[Sakai/Zeng19SIGIR]
Abandoning
probability
SERP utility
at
abandoned
rank](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-12-2048.jpg)
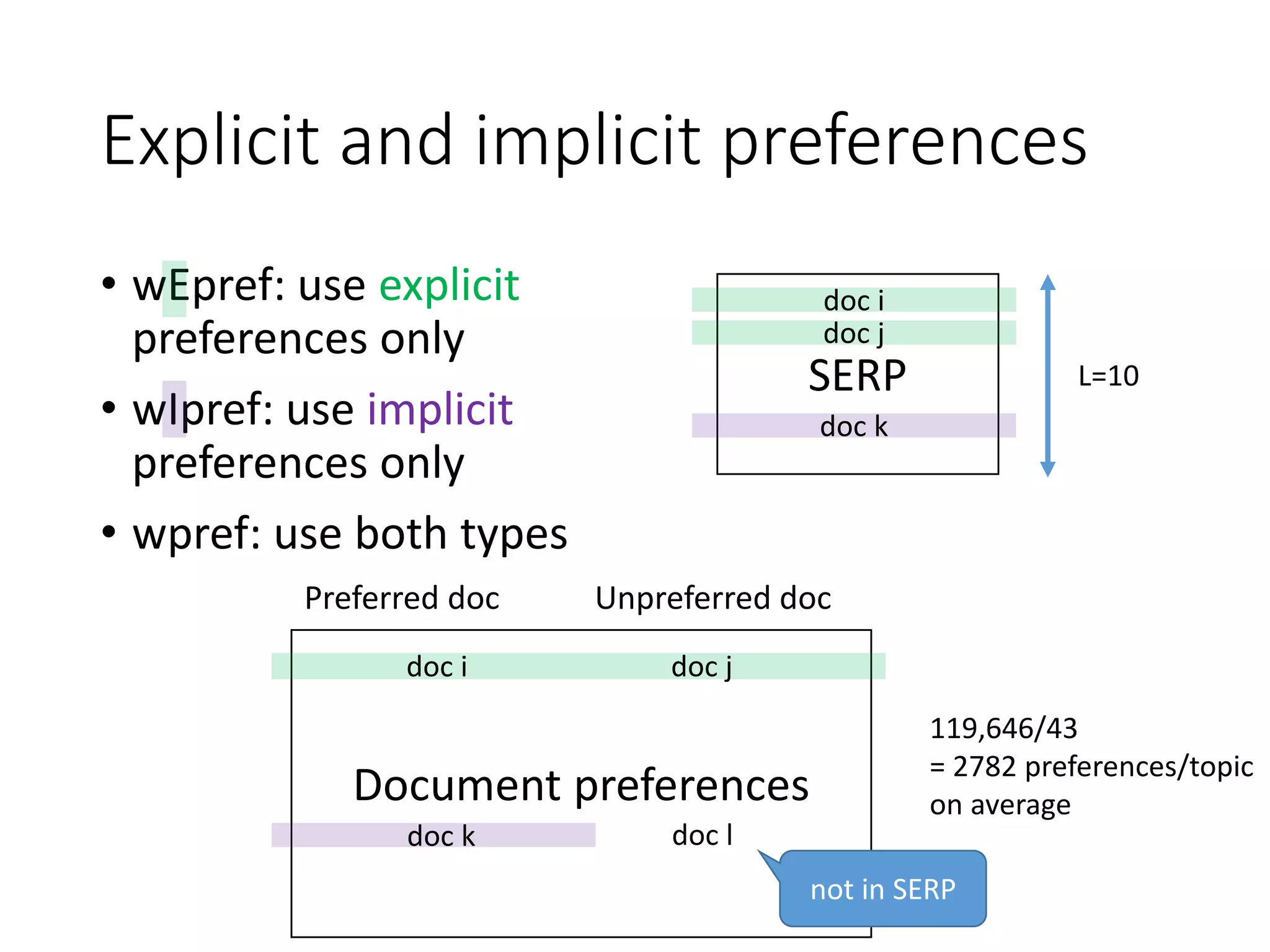
![Preference based measures:
Pref-measures
Variants of [Carterette+08ECIR]
[Carterette/Bennett08SIGIR]
discount based on↓ binary relevance graded relevance
rank of preferred doc i wpref1 wpref4
rank of unpreferred doc j wpref2 wpref5
average ranks of i and j wpref3 wpref6
Utilise preference redundancies
More measures
discussed in paper
SERP
doc i
doc j](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-13-2048.jpg)
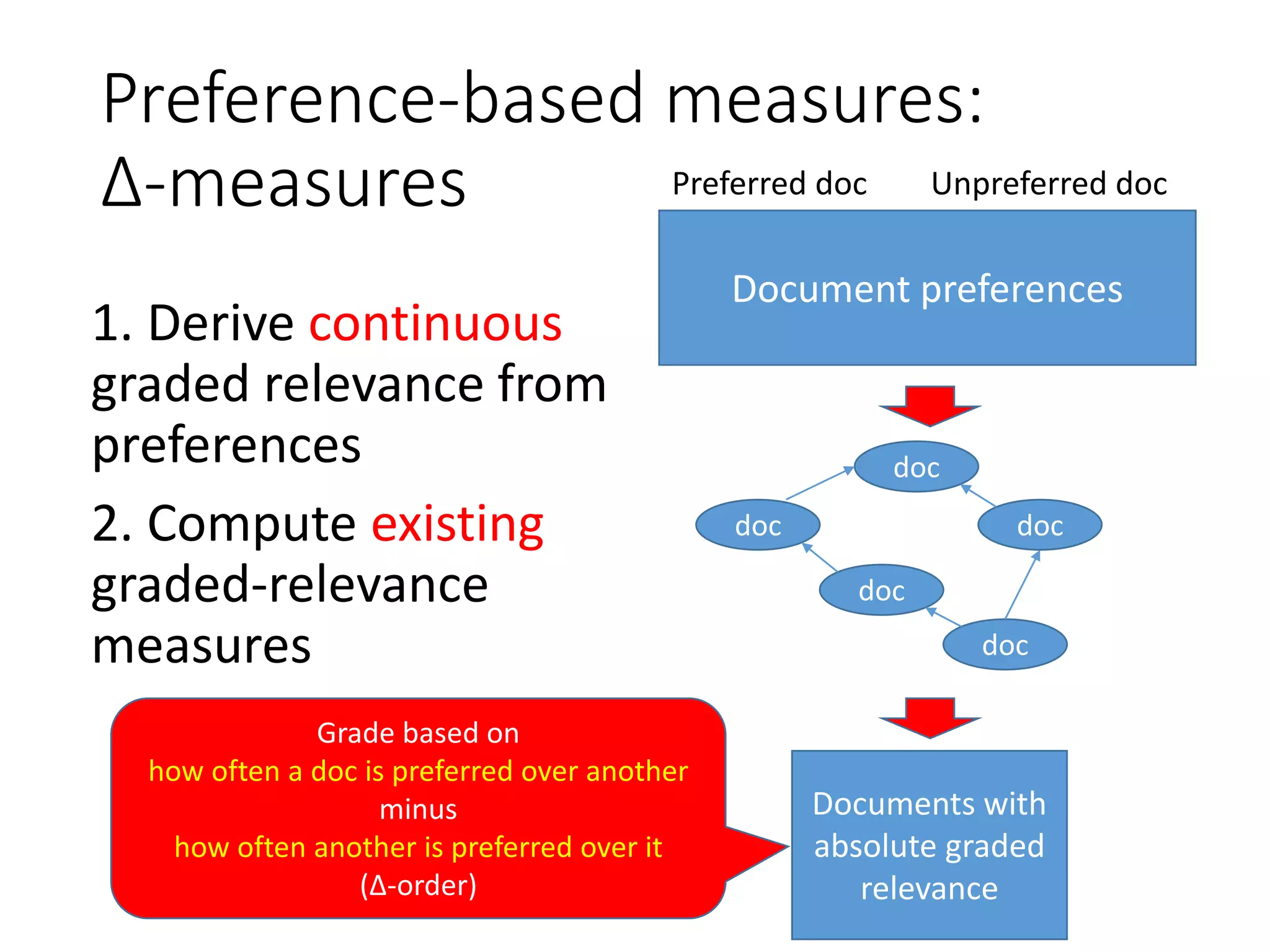

![FYI This presentation uses an evaluation
method that’s different from the paper
In our paper...
1. We decide on a single
gold SERP preference by
majority voting (all 15
agreed? only 9 agreed?
Information lost)
2. Compute one Kendall’s
tau value with
#concordant and
#discordant preferences
(with 95%CIs)
In this presentation...
1. We compute the MAR
over the SERP pairs
(n=894) for each
measure and each
“human” measure
2. Discuss statistical
significance based on
paired Tukey HSD test
[Sakai18book]
The measure agrees with what
proportion of users on average?
Familywise error
rate: 5%](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-17-2048.jpg)
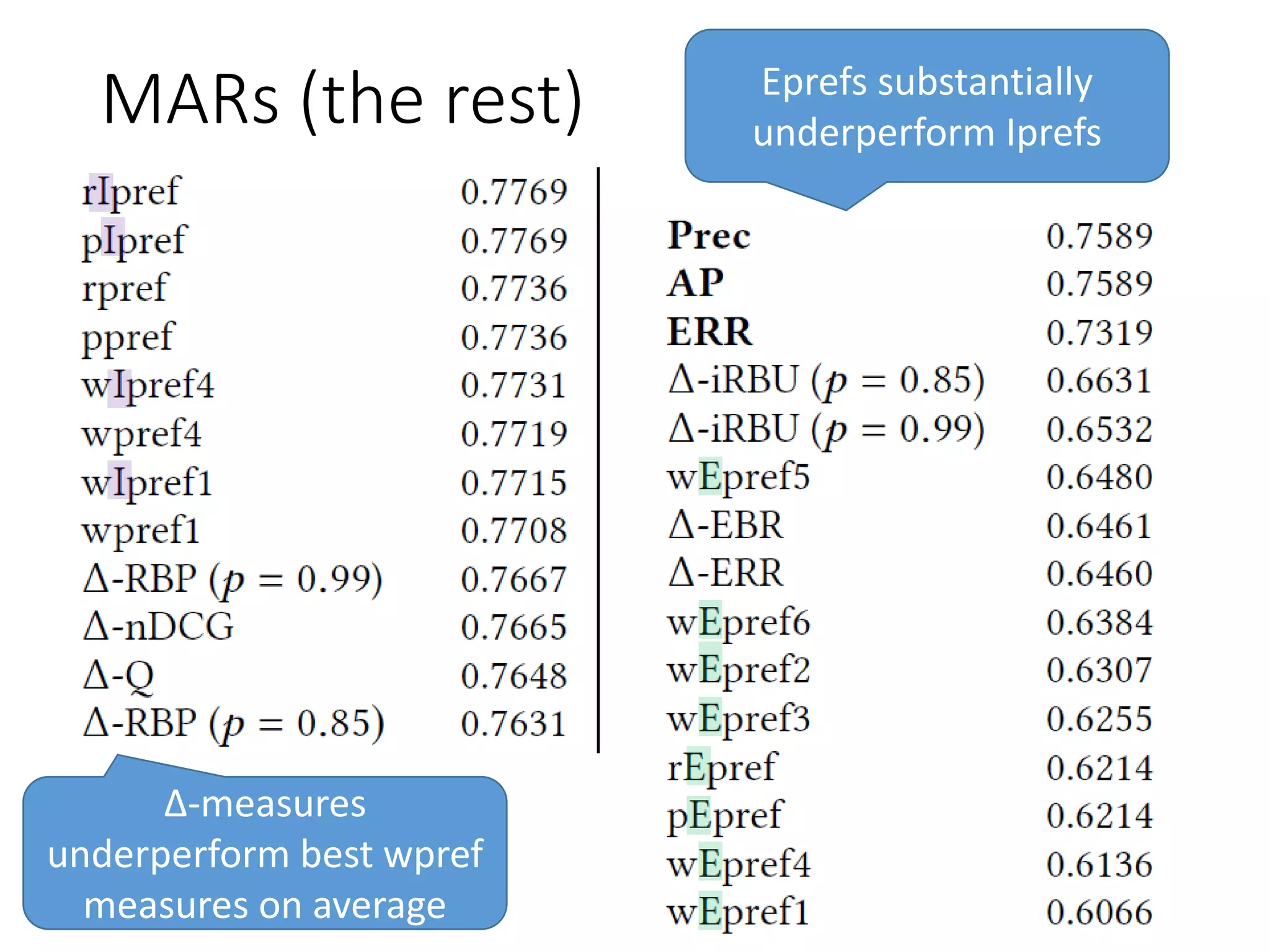



![Discussion (2)
• iRBU from [Sakai/Zeng19SIGIR] (stolen from the
diversity measure RBU [Amigo+18SIGIR] ) performs
surprisingly well – encoding graded relevance only
in the abandonment probability distribution (and
not in the utility function) seems to work...
Ignores document relevance in top r](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-23-2048.jpg)


![References (selected)
[Amigo+18SIGIR] https://doi.org/10.1145/3209978.3210024
[Bashir+13SIGIR] https://doi.org/10.1145/2484028.2484170
[Carterette+08ECIR] http://www.cs.cmu.edu/~pbennett/papers/HereOrThere-ECIR-
2008.pdf
[Carterette/Bennett08SIGIR] https://doi.org/10.1145/1390334.1390451
[Frei/Schauble91IPM] https://doi.org/10.1016/0306-4573(91)90046-O
[Hui/Berberich17ICTIR] https://doi.org/10.1145/3121050.3121095
[Jarvelin/Kekalainen02TOIS] https://doi.org/10.1145/582415.582418
[Radinsky/Ailon11WSDM] https://doi.org/10.1145/1935826.1935850
[Sakai18book] https://link.springer.com/book/10.1007/978-981-13-1199-4
[Sakai/Robertson08EVIA]
http://research.nii.ac.jp/ntcir/workshop/OnlineProceedings7/pdf/EVIA2008/07-
EVIA2008-SakaiT.pdf
[Sakai/Song13IRJ] https://link.springer.com/article/10.1007/s10791-012-9208-x
[Sakai/Zeng19SIGIR] https://doi.org/10.1145/3331184.3331215](https://image.slidesharecdn.com/sigir2020-200630070616/75/sigir2020-27-2048.jpg)

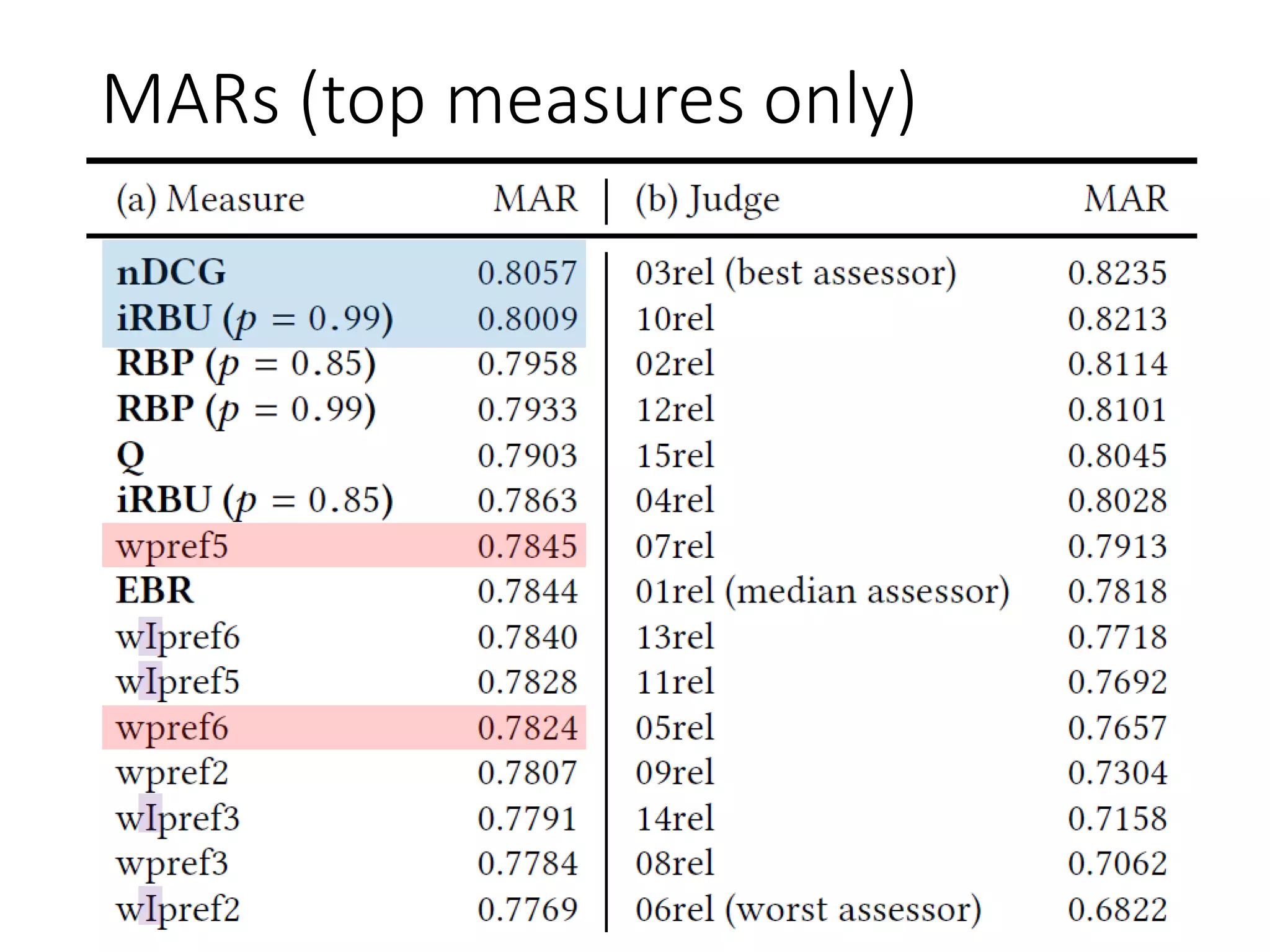
- The document evaluates how well traditional and document preference-based IR evaluation measures align with users' search results page (SERP) preferences. - The best document preference-based measures, wpref5 and wpref6, had a mean agreement rate of 78% with human judges, comparable to the median judge. However, they performed significantly worse than the best human judge, which had an 82% agreement rate. - The best overall measures were nDCG and iRBU, with a mean 80% agreement rate comparable to the best human judge. These measures performed as well as or better than most human judges.























































































