![Semantic Text Processing Powered by Wikipedia Maxim Grinev [email_address]](https://image.slidesharecdn.com/tech-overview-2009-flwr1-090902063837-phpapp01/85/Semantic-Text-Processing-Powered-by-Wikipedia-1-320.jpg)

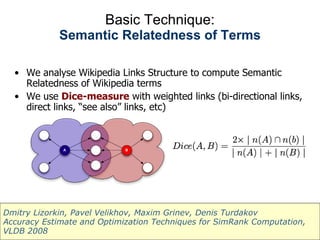


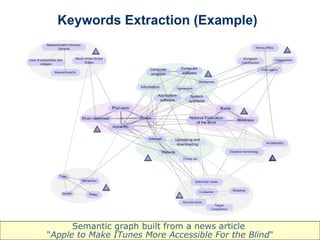









The document discusses using Wikipedia as a resource for semantic text processing and natural language processing techniques. It describes using Wikipedia's comprehensive coverage of terms, rich structure of links and categories, and ability to be continuously updated to power text analysis algorithms. These include word sense disambiguation, keyword extraction, topic inference, ontology management, semantic search, and improved recommendations. The techniques analyze Wikipedia's link structure and build semantic graphs of documents to discover related concepts and group keywords.





















































































