Downloaded 118 times










![From the organizational behavior and management community “ [A] group of people who interact through interdependent tasks guided by common purpose [that] works across space, time, and organizational boundaries with links strengthened by webs of communication technologies ” — Lipnack & Stamps, 1997 Yes—but adding cyber-infrastructure: People computational agents & services Communication technologies IT infrastructure Collaboration based on rich data & computing capabilities](https://image.slidesharecdn.com/gridcomputingjuly2009-090725124312-phpapp02/85/Grid-Computing-July-2009-13-320.jpg)
![NSF Workshops on Building Effective Virtual Organizations [Search “BEVO 2008”]](https://image.slidesharecdn.com/gridcomputingjuly2009-090725124312-phpapp02/85/Grid-Computing-July-2009-14-320.jpg)
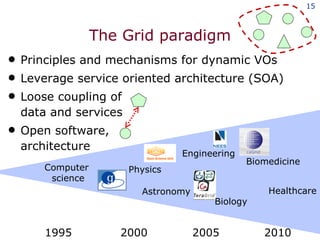

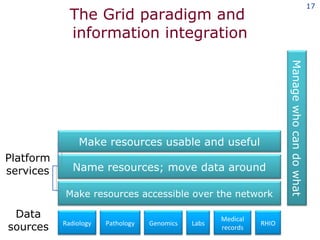
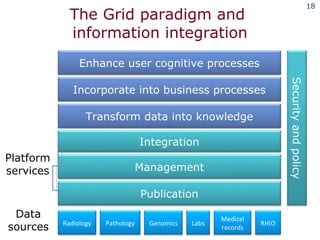
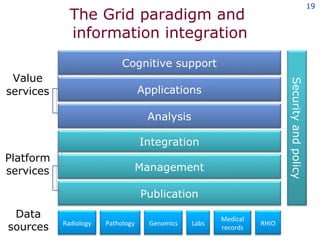
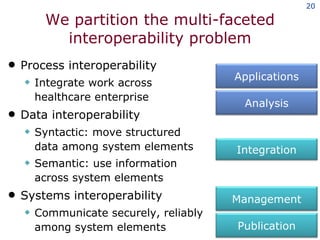

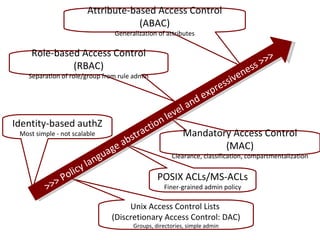
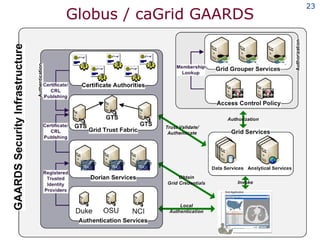
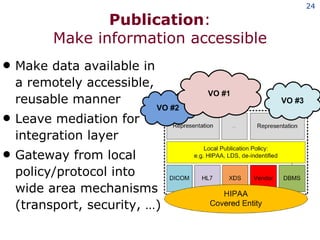
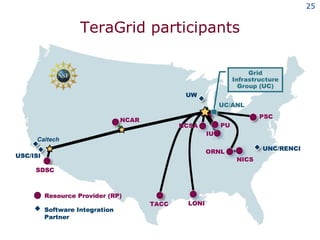
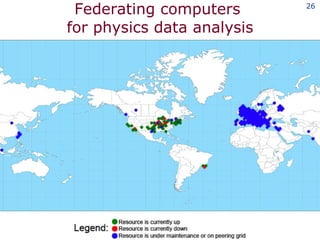
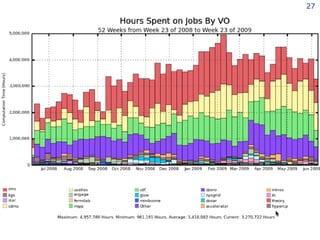
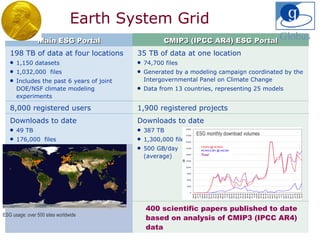
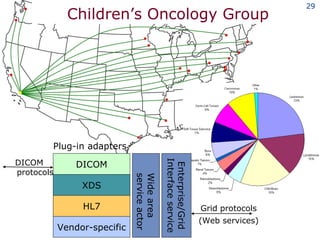
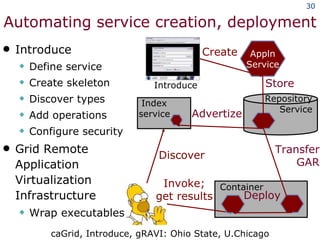
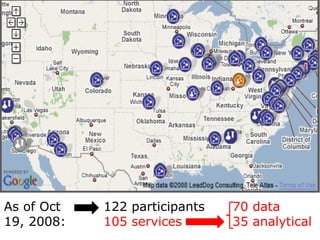
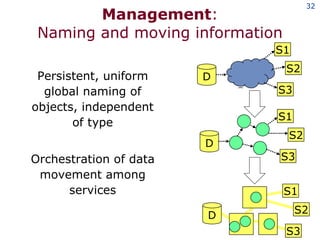

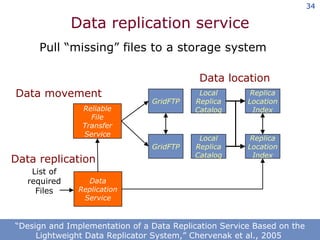

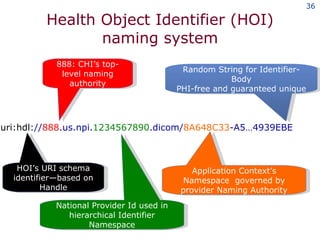
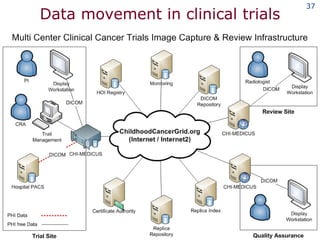
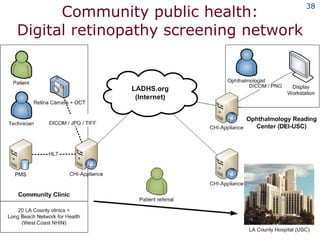
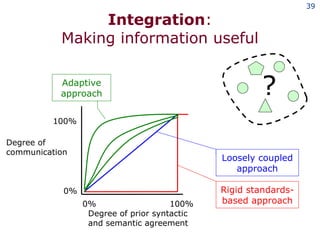
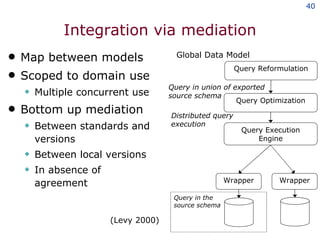
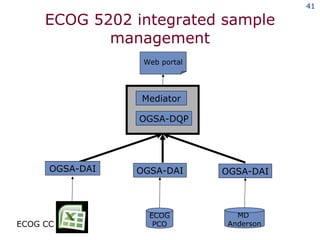

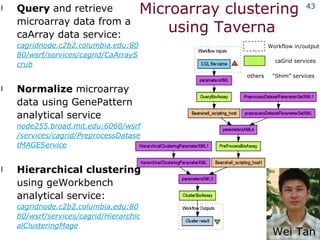
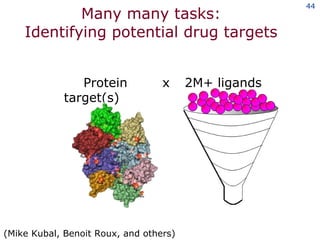
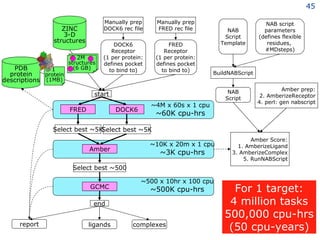
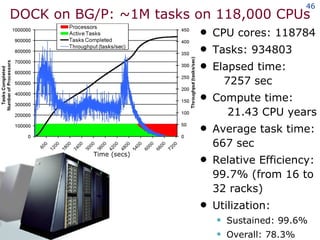
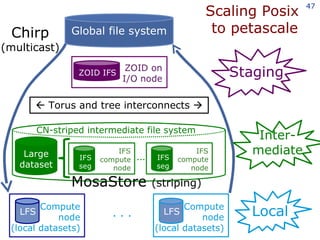
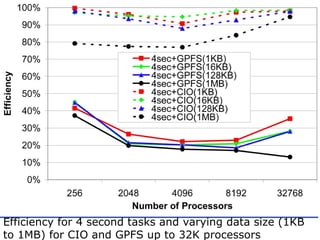
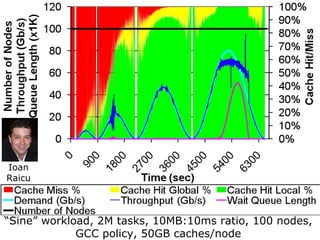
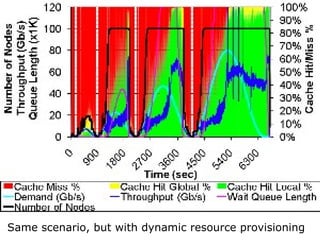
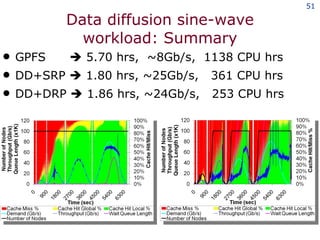

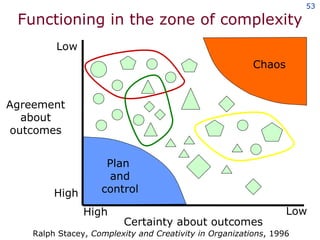
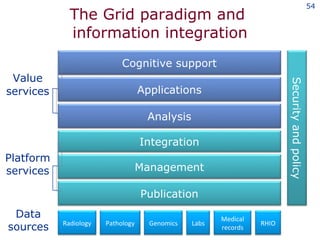

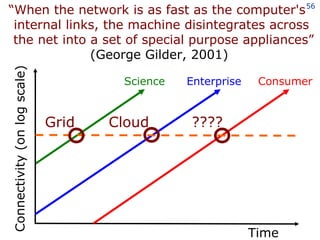


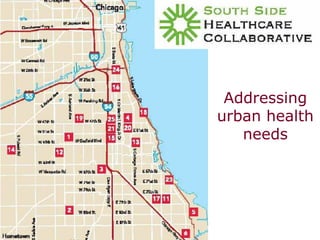
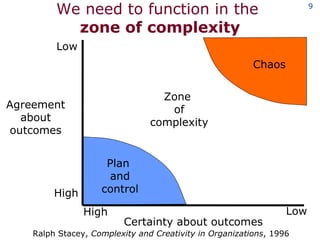
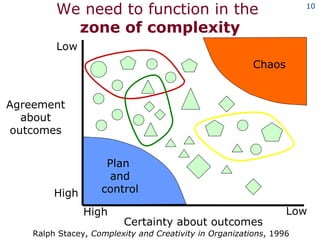
The document discusses the concept of grid computing as a means to facilitate collaboration across complex, adaptive systems in various fields, particularly healthcare. It emphasizes the importance of coordinated resource sharing among virtual organizations, which necessitates controlled access to data and computing resources. The author advocates for a model of virtual integration to improve the efficiency and effectiveness of fragmented healthcare systems.















































![Grid computing [2005]](https://cdn.slidesharecdn.com/ss_thumbnails/gridcomputing2005-120430023634-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![Grid computing by vaishali sahare [katkar]](https://cdn.slidesharecdn.com/ss_thumbnails/gridcomputingbyvaishalisaharekatkar-170320053224-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


