









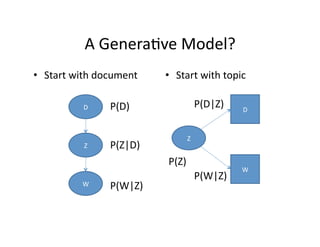

















The document provides an introduction to Probabilistic Latent Semantic Analysis (PLSA). It discusses how PLSA improves on previous Latent Semantic Analysis methods by incorporating a probabilistic framework. PLSA models documents as mixtures of topics and allows words to have multiple meanings. The parameters of the PLSA model, including the topic distributions and word-topic distributions, are estimated using an expectation-maximization algorithm to find the parameters that best explain the observed word-document co-occurrence data.












































































