













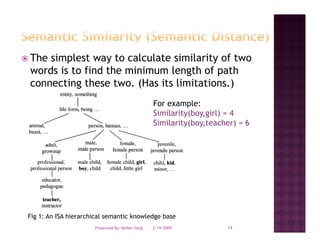







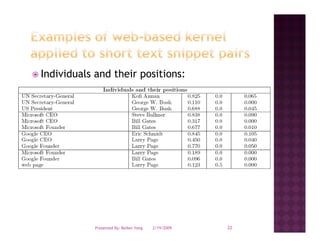
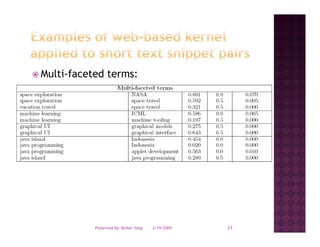





The document discusses semantic similarity and relatedness. It provides examples of how semantic similarity is used in applications like search engines, question answering systems, and making recommendations. It also summarizes several approaches for calculating semantic similarity between words, texts, or documents.









































































