





![Lexical Semantics
• Adapted from Python Text Processing with NLTK 2.0 Cookbook (Perkins,
2010)
>>> from nltk.corpus import wordnet as wn
>>> word_synset = wn.synsets(’cookbook’)[0]
>>> word_synset.name
’cookbook.n.01’
>>> word_synset.definition
’a book of receipes and cooking directions’
5](https://image.slidesharecdn.com/bigdatapoolzasemprocessing-140223131635-phpapp02/85/Big-Data-Palooza-Talk-Aspects-of-Semantic-Processing-6-320.jpg)
![Lexical Semantics
• Antonymy:
>>> ga1 = wn.synset(’good.a.01’)
>>> ga1.definition
’having desirable or positive qualities especially those suitable
for a thing specified’
>>> bad = ga1.lemmas[0].antonyms()[0]
>>> bad.name
’bad’
>>> bad.synset.definition
’having undesirable or negative qualities’
6](https://image.slidesharecdn.com/bigdatapoolzasemprocessing-140223131635-phpapp02/85/Big-Data-Palooza-Talk-Aspects-of-Semantic-Processing-7-320.jpg)








![Cosine & Euclidean Similarity in Python
>>> import numpy as np
>>> from scipy.spatial import distance as dist
>>> cosm = np.array([1,0,1,0,0,0])
>>> astr = np.array([0,1,1,0,0,0])
>>> dist.cosine(cosm, astr)
1.0
>>> dist.euclidean(cosm, astr)
2.4494897427831779
15](https://image.slidesharecdn.com/bigdatapoolzasemprocessing-140223131635-phpapp02/85/Big-Data-Palooza-Talk-Aspects-of-Semantic-Processing-16-320.jpg)


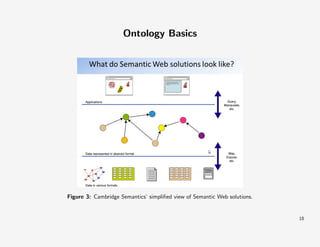










The document discusses semantic processing, including the definitions of semantics and pragmatics, and introduces lexical semantics and the WordNet database. It outlines methods for computing semantic similarity using vector space modeling and touches on the basics of ontology and text mining. The text further explores advantages and disadvantages of these semantic technologies and methodologies.



































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)