Downloaded 15 times



















![12/01/17 23
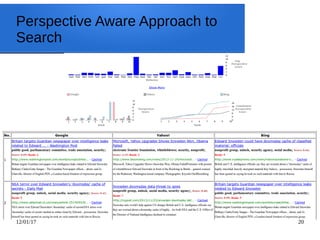
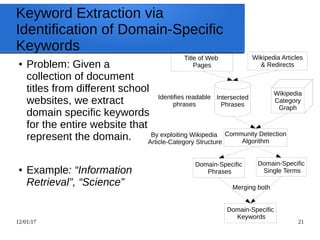
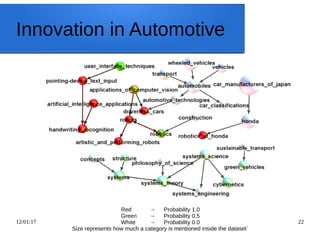
Python Snippet for the Usage of
the WikiMadeEasy API
● wiki_client = Wiki_client_service()
● print(wiki_client.process([`isTitle', `business', 0]))
● print(wiki_client.process([`isPerson', `albert einstein', 0]))
● print(wiki_client.process([`mentionInCategories', `data mining', 0]))
● print(wiki_client.process([`containsArticles', `business', 0]))
● print(wiki_client.process([`matchesCategories', `pakistan', 0]))
● print(wiki_client.process([`matchesArticles', `computer science', 0]))
● print(wiki_client.process([`getWikiOutlinks', `pagerank', 0]))
● print(wiki_client.process([`getWikiInlinks', `google', 0]))
● print(wiki_client.process([`getExtendedAbstract', `pakistan', 0]))
● print(wiki_client.process([`getSubCategory', `science', 0]))
● print(wiki_client.process([`getSuperCategory', `science', 0]))
● graph_dict = wiki_client.process([`getSubtoSuperCategoryGraph', [`information_science',
`sociology'], 2])](https://image.slidesharecdn.com/textminingwordembeddingswikipedia-170112154046/85/Text-mining-word-embeddings-wikipedia-23-320.jpg)


The document discusses the application of text mining and word embeddings, particularly using Wikipedia as a resource for enhancing the understanding and processing of textual data. It outlines challenges such as word ambiguity and the complexity of natural language, while also explaining techniques like phrase chunking and the use of Wikipedia's structured categories for improved semantic relatedness. Additionally, it introduces the perspective-aware approach to search engines and various algorithms for keyword extraction based on domain-specific requirements.







































![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)