Downloaded 154 times















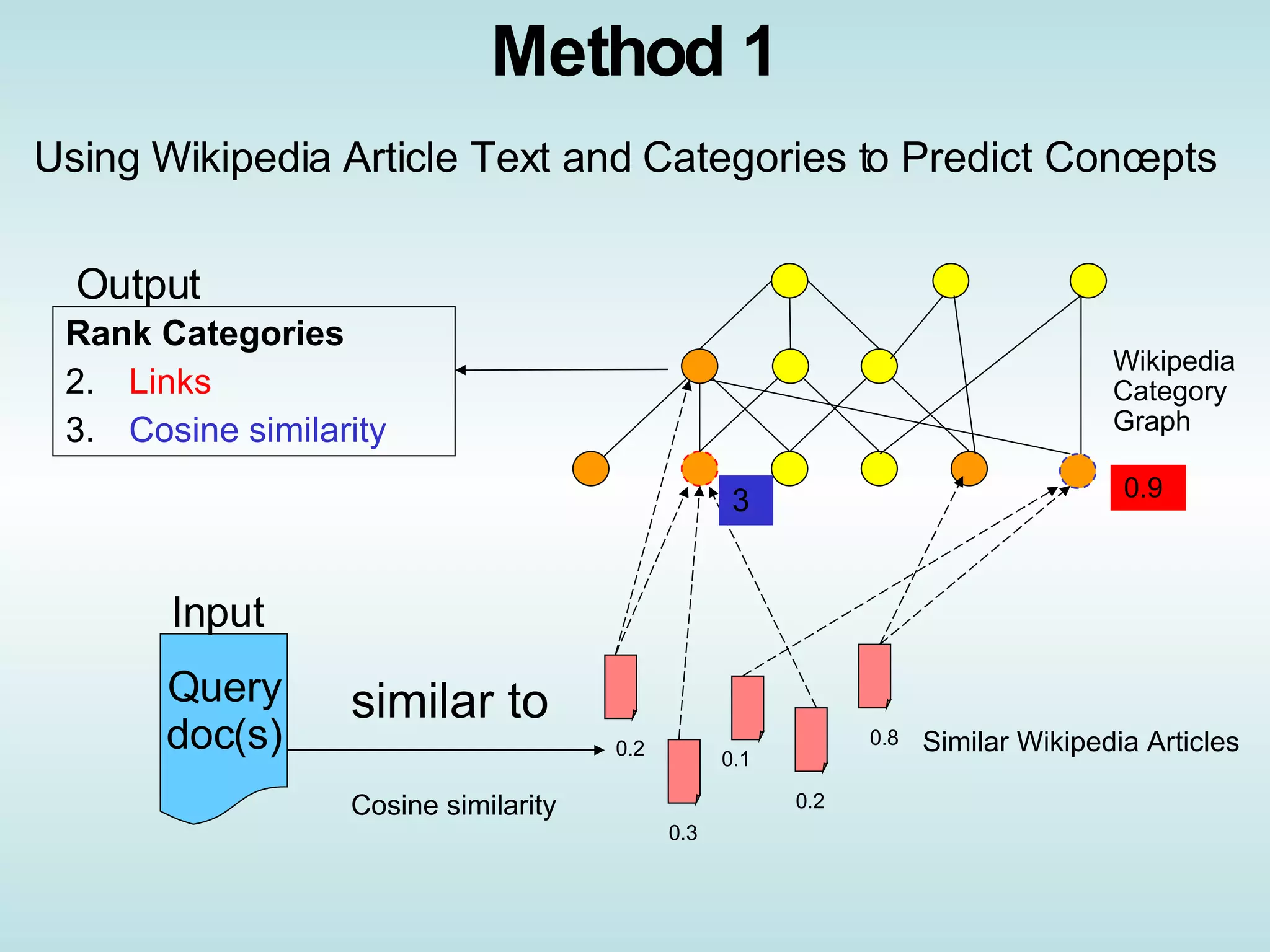


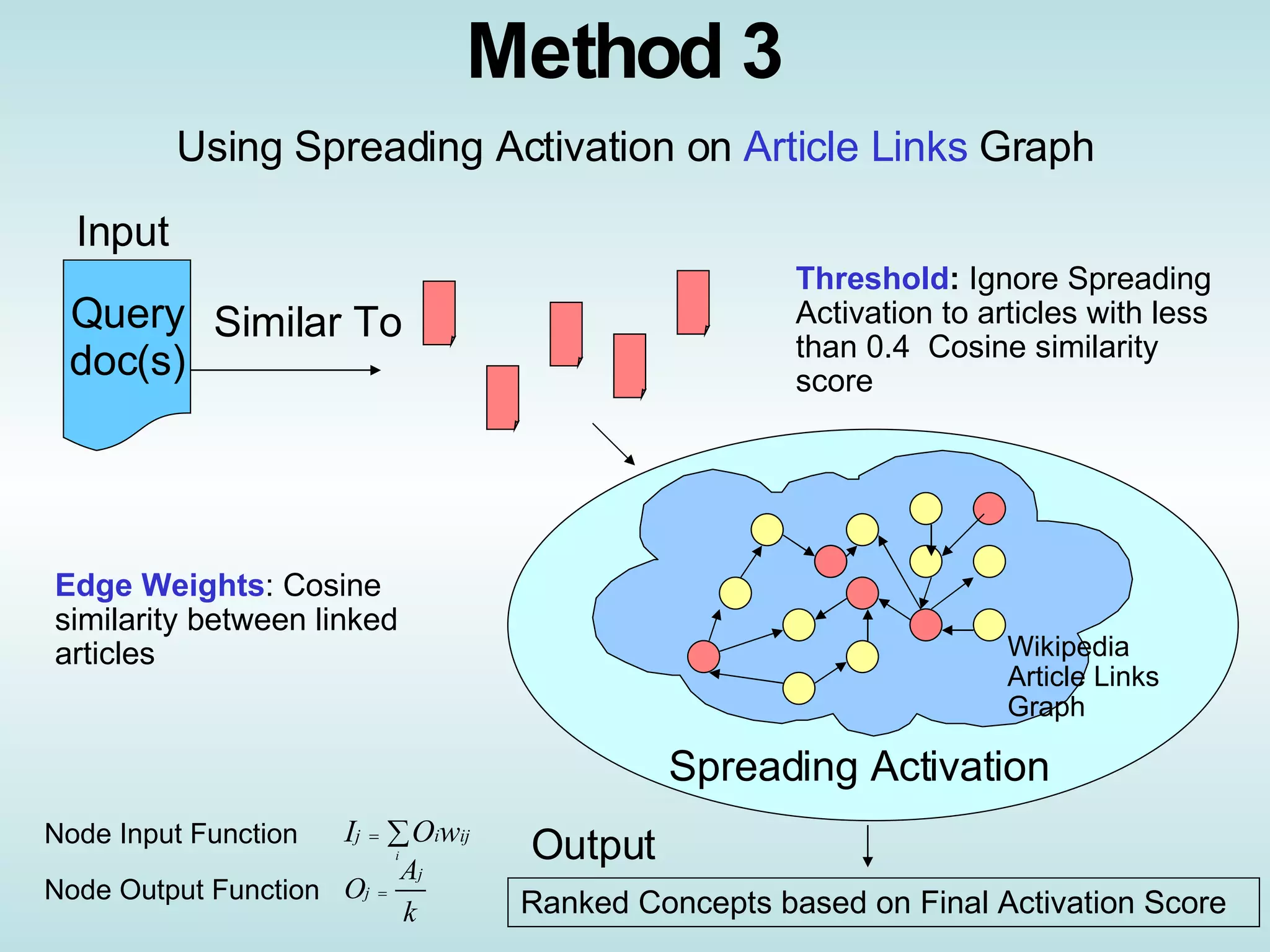




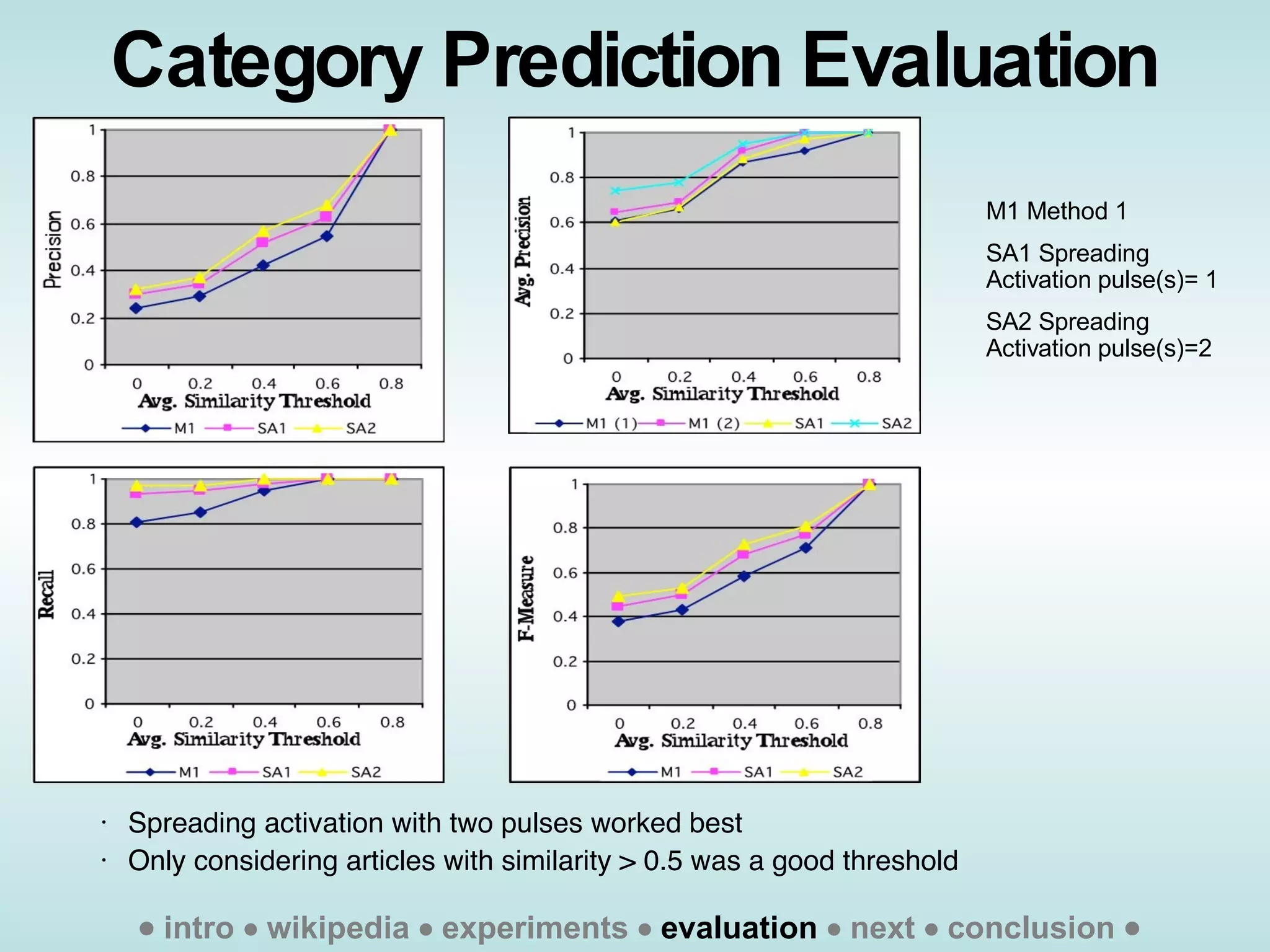










The document presents an approach called "Wikitology" that uses Wikipedia as an ontology for describing and summarizing documents. It outlines methods for mapping documents to Wikipedia articles and categories using similarity metrics and spreading activation across the Wikipedia link graph. The authors conducted experiments predicting concepts for single and multiple documents and evaluated accuracy by comparing to human judgments. They discuss applications like document expansion and future work improving the methods and exploiting the Wikipedia structure.



































































