Downloaded 156 times


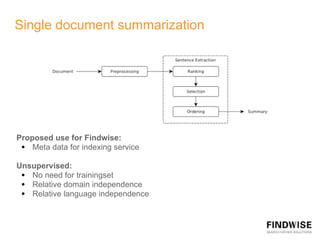

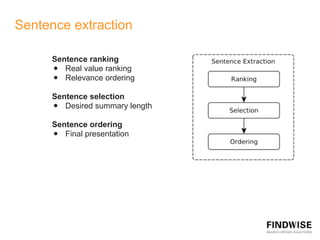
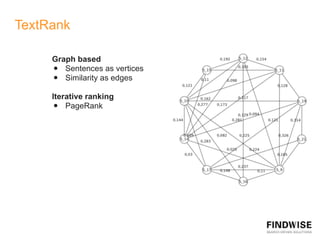

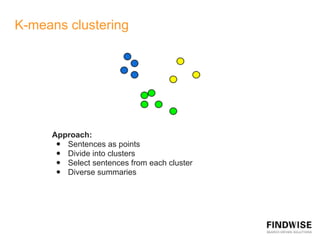
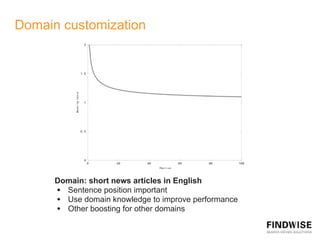
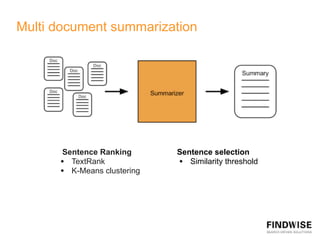
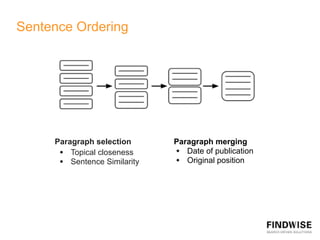

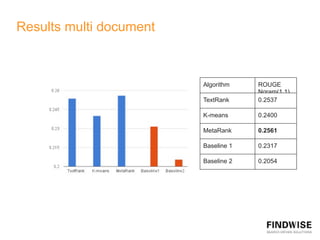
This document discusses automatic document summarization techniques. It presents an unsupervised approach using TextRank and K-means clustering to extract and rank sentences for inclusion in summaries. TextRank models sentences as vertices in a graph and ranks them based on their connections. K-means clusters sentences and selects representatives from each cluster. The techniques are domain independent and can generate single or multi-document summaries. Evaluation results show the TextRank approach achieves higher ROUGE scores than the K-means and baseline methods.























































































