Download to read offline




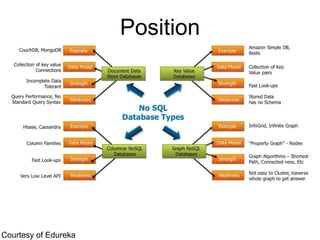



































The document discusses the strengths and weaknesses of MongoDB, particularly in terms of integration capabilities and management tools needed for large clusters. It highlights the need for complementing MongoDB with solutions like Treasure Data for data ingestion and analytics, emphasizing the trade-off between control and ease of use. Use-cases such as mobile ecommerce platform Wish.com illustrate how MongoDB and Treasure Data can be effectively utilized together.































































































