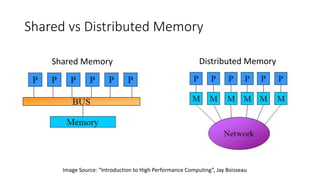
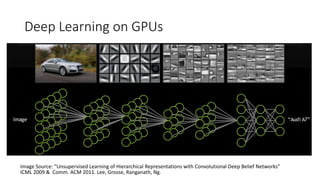
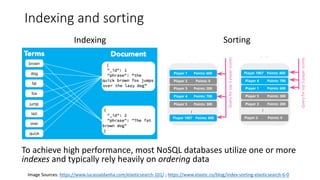
The document discusses various big data infrastructures, including distributed relational databases, NoSQL databases, ETL systems, and both high throughput and high performance computing. It defines 'big data' and the importance of choosing appropriate systems based on functionality and cost. Key examples and uses for each infrastructure type are provided to illustrate their applications across industries and research.














![MapReduce
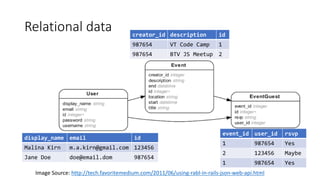
display_name id
Malina Kirn 123456
Jane Doe 987654
Jane Doe 135791
Map
display_name id first_name
Malina Kirn 123456 Malina
Jane Doe 987654 Jane
Jane Doe 135791 Jane
data['first_name'] =
data['display_name'].map(x->x.split()[0])
display_name id
Malina Kirn 123456
Jane Doe 987654
Jane Doe 135791
Reduce
display_name count
Malina Kirn 1
Jane Doe 2
data.groupby('display_name').count()](https://image.slidesharecdn.com/2018-09-15vtcodecamp-kirn-surveyofbigdatainfrastructures-181220172954/85/Survey-of-Big-Data-Infrastructures-18-320.jpg)