Downloaded 74 times









![Example: Github data from past year
3.5 GB Table
SELECT type, count(*) as num FROM [publicdata:samples.github_timeline]
group by type order by num desc;
Query complete (1.1s elapsed, 75.0 MB processed)
Event Type num
PushEvent 2,686,723
CreateEvent 964,830
WatchEvent 581,029
IssueCommentEvent 507,724
GistEvent 366,643
IssuesEvent 305,479
ForkEvent 180,712
PullRequestEvent 173,204
FollowEvent 156,427
GollumEvent 104,808
Cost $0.0026
or 5 for a penny](https://image.slidesharecdn.com/howbigquerybrokemyheart-130522164709-phpapp02/85/How-BigQuery-broke-my-heart-9-320.jpg)



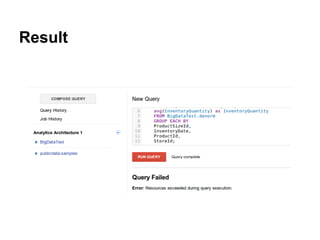

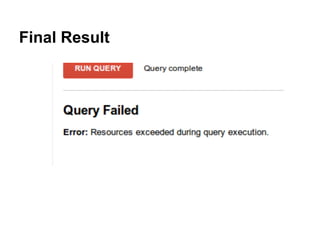




The document discusses Gabe Hamilton's experience evaluating BigQuery as a replacement for SQL Server in reporting and business intelligence, highlighting its cost-effectiveness and speed advantages. While BigQuery initially impressed with low query costs and performance metrics, Hamilton faced challenges like limitations on joins and query grouping that complicated usage. Ultimately, the experience was mixed, revealing both promise and hurdles in the transition to BigQuery.










































![[Webinar] Getting Started with BigQuery: Basics, Its Appilcations & Use Cases](https://cdn.slidesharecdn.com/ss_thumbnails/webinargettingstartedwithbigquery-171116122740-thumbnail.jpg?width=640&height=640&fit=bounds)



![[LondonSEO 2020] BigQuery & SQL for SEOs](https://cdn.slidesharecdn.com/ss_thumbnails/abuali-londonseomeetup-200115205008-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
