Download as PDF, PPTX














![SANSA [1] is a processing data flow engine that provides data
distribution, and fault tolerance for distributed computation over
large-scale RDF datasets
SANSA includes several libraries:
- Read / Write RDF / OWL library
- Querying library
- Inference library
- ML library
SANSA
19
BigDataEurope
Inference
Knowledge Distribution &
Representation
DeployCoreAPIs&Libraries
Local Cluster
Standalone Resource manager
Querying
Machine Learning](https://image.slidesharecdn.com/efficientdistributedin-memoryprocessingofrdfdatasets-phdviva-201003202124/85/Efficient-Distributed-In-Memory-Processing-of-RDF-Datasets-PhD-Viva-19-320.jpg)

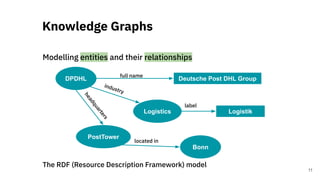
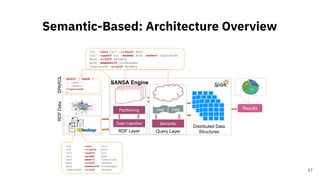
![Large-Scale RDF Dataset
Statistics
A Scalable Distributed Approach for
Computation of RDF Dataset Statistics [2]
21](https://image.slidesharecdn.com/efficientdistributedin-memoryprocessingofrdfdatasets-phdviva-201003202124/85/Efficient-Distributed-In-Memory-Processing-of-RDF-Datasets-PhD-Viva-21-320.jpg)


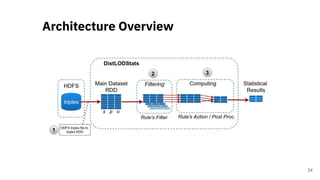

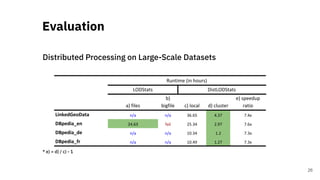
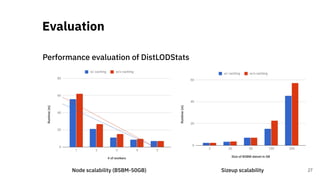

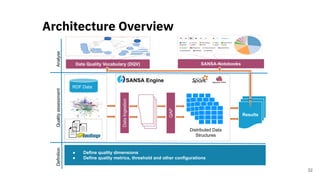
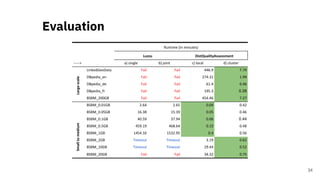
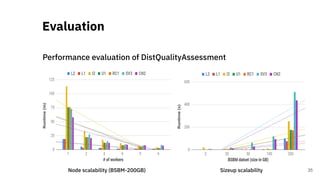
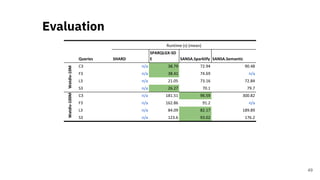
![Quality Assessment of RDF
Datasets at Scale
A Scalable Framework for Quality Assessment of
RDF Datasets [3]
29](https://image.slidesharecdn.com/efficientdistributedin-memoryprocessingofrdfdatasets-phdviva-201003202124/85/Efficient-Distributed-In-Memory-Processing-of-RDF-Datasets-PhD-Viva-29-320.jpg)




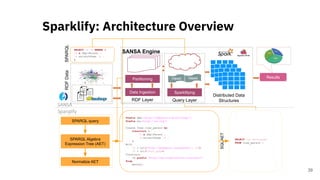
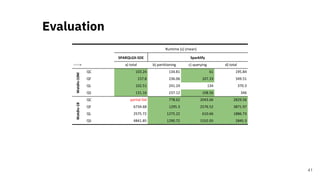
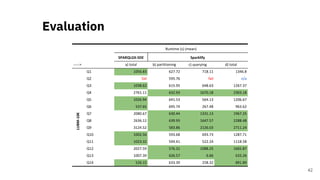
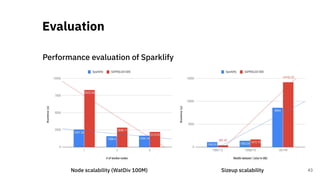
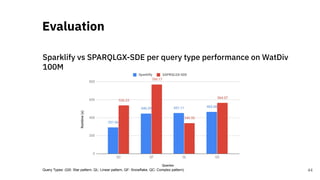
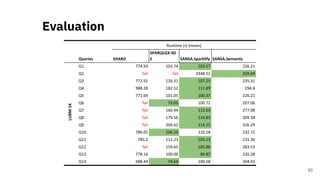
![Scalable RDF Querying
Sparklify: A Scalable Software Component for
Efficient evaluation of SPARQL queries over
distributed RDF datasets* [4]
37* A joint work with Claus Stadler, a PhD student at the University of Leipzig.](https://image.slidesharecdn.com/efficientdistributedin-memoryprocessingofrdfdatasets-phdviva-201003202124/85/Efficient-Distributed-In-Memory-Processing-of-RDF-Datasets-PhD-Viva-37-320.jpg)


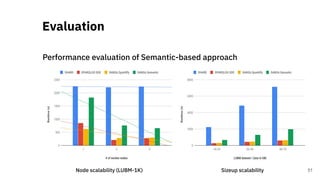
![Scalable RDF Querying
Towards A Scalable Semantic-based Distributed
Approach for SPARQL query evaluation [5]
45](https://image.slidesharecdn.com/efficientdistributedin-memoryprocessingofrdfdatasets-phdviva-201003202124/85/Efficient-Distributed-In-Memory-Processing-of-RDF-Datasets-PhD-Viva-45-320.jpg)














![[1]. Distributed Semantic Analytics using the SANSA Stack. Jens Lehmann; Gezim Sejdiu; Lorenz Bühmann; Patrick
Westphal; Claus Stadler; Ivan Ermilov; Simon Bin; Nilesh Chakraborty; Muhammad Saleem; Axel-Cyrille Ngomo Ngonga;
and Hajira Jabeen. In Proceedings of 16th International Semantic Web Conference - Resources Track (ISWC'2017), 2017.
[2]. DistLODStats: Distributed Computation of RDF Dataset Statistics. Gezim Sejdiu; Ivan Ermilov; Jens Lehmann; and
Mohamed Nadjib-Mami. In Proceedings of 17th International Semantic Web Conference, 2018.
[3]. A Scalable Framework for Quality Assessment of RDF Datasets. Gezim Sejdiu; Anisa Rula; Jens Lehmann; and Hajira
Jabeen. In Proceedings of 18th International Semantic Web Conference, 2019.
[4]. Sparklify: A Scalable Software Component for Efficient evaluation of SPARQL queries over distributed RDF datasets.
Claus Stadler; Gezim Sejdiu; Damien Graux; and Jens Lehmann. In Proceedings of 18th International Semantic Web
Conference, 2019.
[5]. Towards A Scalable Semantic-based Distributed Approach for SPARQL query evaluation. Gezim Sejdiu; Damien
Graux; Imran Khan; Ioanna Lytra; Hajira Jabeen; and Jens Lehmann. In 15th International Conference on Semantic
Systems (SEMANTiCS), 2019.
References
67](https://image.slidesharecdn.com/efficientdistributedin-memoryprocessingofrdfdatasets-phdviva-201003202124/85/Efficient-Distributed-In-Memory-Processing-of-RDF-Datasets-PhD-Viva-67-320.jpg)



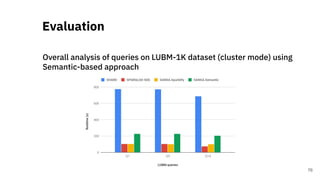

This document discusses efficient distributed processing of large-scale RDF datasets, focusing on the challenges and methodologies for querying, quality assessment, and statistical computation. It presents the 'SANSA' framework, which provides robust tools for handling RDF data distribution, quality metrics, and SPARQL query evaluation. The research highlights innovative approaches to enhance data analytics in the context of big data, backed by experimental results demonstrating significant performance improvements.



































































