Download as PDF, PPTX











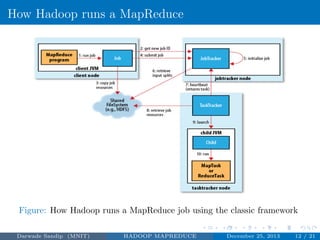



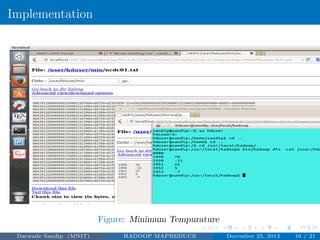
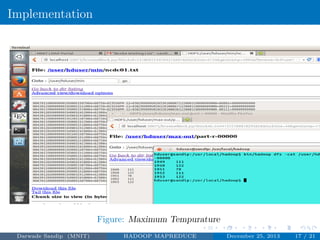
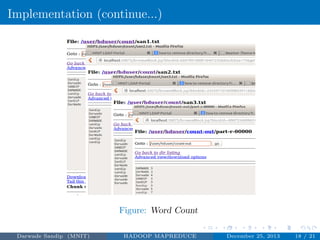



The document discusses Hadoop MapReduce. It describes Hadoop as a framework for distributed processing of large datasets across computer clusters. MapReduce is the programming model used in Hadoop for processing and generating large datasets in parallel. The two main components of Hadoop are HDFS for storage and MapReduce for processing. MapReduce involves two main phases - the map phase where input data is converted into intermediate outputs, and the reduce phase where the outputs are aggregated to form the final results.


































































