Downloaded 56 times































.asInstanceOf[BV[Double]])
val counts = Array.fill(k)(0L)
points.foreach { point =>
val (bestCenter, cost) = KMeans.findClosest(centers, point)
costAccum += cost
sums(bestCenter) += point.vector
counts(bestCenter) += 1
}
val contribs = for (j <- 0 until k) yield {
(j, (sums(j), counts(j)))
}
contribs.iterator
}.reduceByKey(mergeContribs).collectAsMap()](https://image.slidesharecdn.com/mlconftalk-140919100445-phpapp02/85/Sandy-Ryza-Software-Engineer-Cloudera-at-MLconf-ATL-33-320.jpg)


















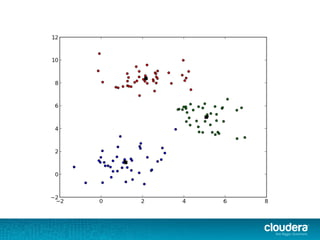
The document discusses clustering algorithms like K-means and how they can be implemented using Apache Spark. It describes how Spark allows these algorithms to be highly parallelized and run on large datasets. Specifically, it covers how K-means clustering works, its limitations in choosing initial cluster centers, and how K-means++ and K-means|| algorithms aim to address this by sampling points from the dataset to select better initial centers in a parallel manner that is scalable for big data.




















![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt1580-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































