Download to read offline




![Just like a standard java
SortedMap, but…
● AccumuloSortedMap returns a copy of the map value.
You must put() to save modifications.
● To use sorted map features, the SerDe used must
serialize bytes in same sort order as java Objects.
The default FixedPointSerde is suitable for most
common keys types (strings, primitives, byte[], etc).
More about SerDes later…
● Supports sizes greater than MAX_INT. See
sizeAsLong().
● Can be set to read-only. Derived map methods, which
stack scan iterators, always return read-only maps.](https://image.slidesharecdn.com/introducingaccumulocollections-161012212121/75/Accumulo-Summit-2016-Introducing-Accumulo-Collections-A-Practical-Accumulo-Interface-5-2048.jpg)















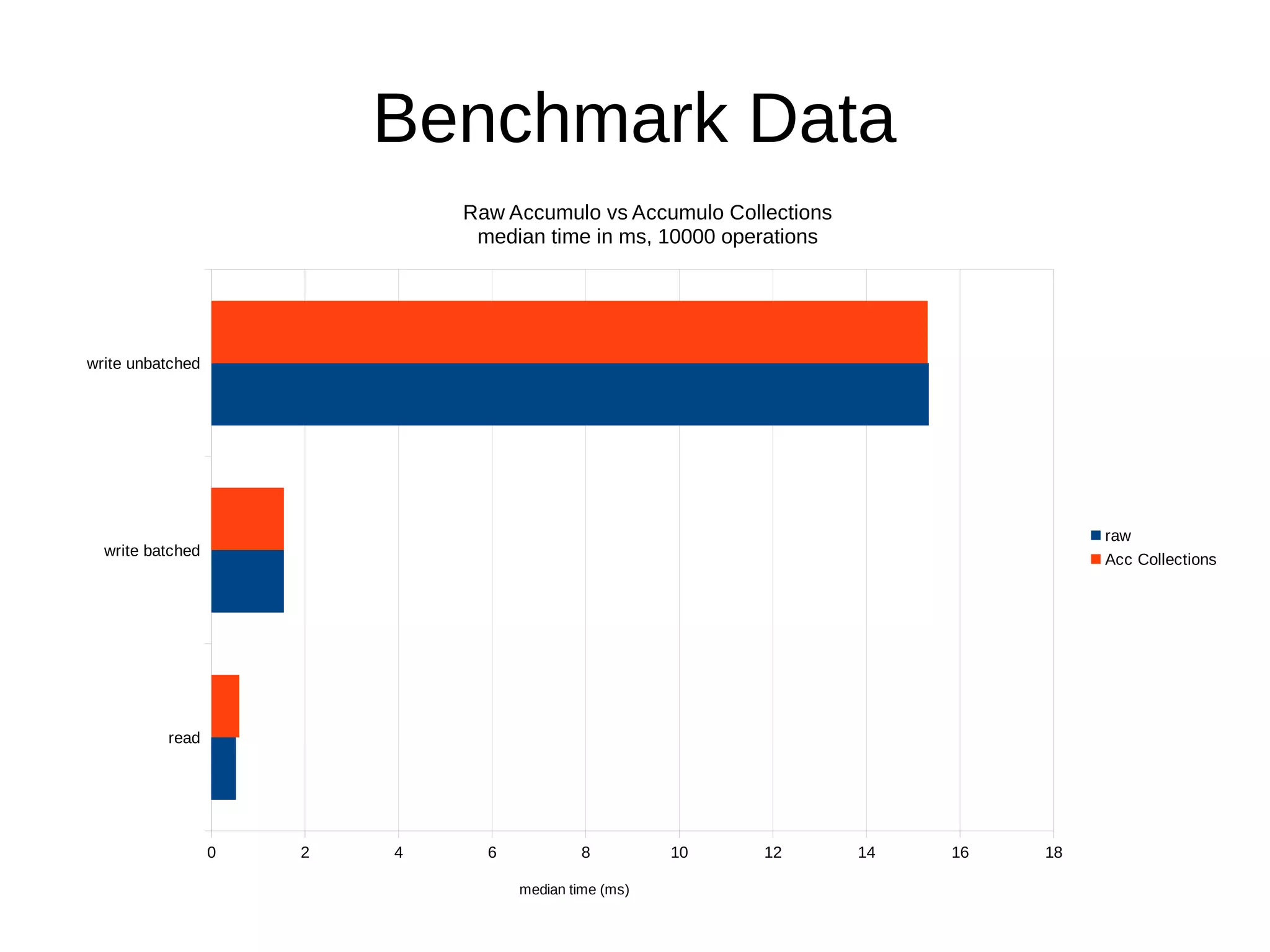


The document introduces Accumulo Collections, a practical API for Accumulo that simplifies the use of NoSQL in Java applications by providing a sorted map interface with additional features like object serialization, foreign key support, and server-side computation. It discusses various functionalities such as statistical aggregation, timestamp management, and custom transformations, all designed to facilitate efficient data manipulation within Accumulo. The author provides examples and performance benchmarks, emphasizing that Accumulo Collections adds minimal overhead compared to raw Accumulo operations.



















































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
