Downloaded 27 times





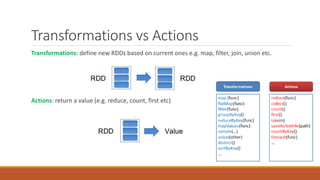
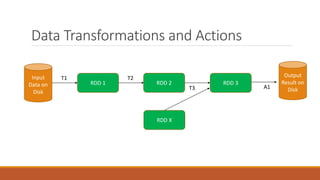


This document discusses Apache Spark, an open-source cluster computing framework, and provides an overview of key Spark concepts including Resilient Distributed Datasets (RDDs), transformations vs actions, and programming models compared to MapReduce. It recommends learning Spark through code examples and provides a link to develop Spark apps on Windows.










































































