Downloaded 39 times


















![24
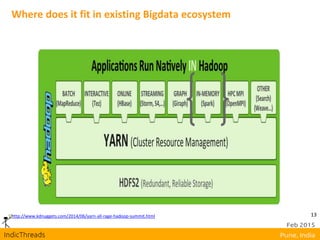
RDD operations
Transformations
map(f : T ⇒ U) : RDD[T] ⇒ RDD[U]
filter(f : T ⇒ Bool) : RDD[T] ⇒ RDD[T]
flatMap(f : T ⇒ Seq[U]) : RDD[T] ⇒ RDD[U]
sample(fraction : Float) : RDD[T] ⇒ RDD[T] (Deterministic sampling)
union() : (RDD[T],RDD[T]) ⇒ RDD[T]
join() : (RDD[(K, V)],RDD[(K, W)]) ⇒ RDD[(K, (V, W))]
groupByKey() : RDD[(K, V)] ⇒ RDD[(K, Seq[V])]
reduceByKey(f : (V,V) ⇒ V) : RDD[(K, V)] ⇒ RDD[(K, V)]
partitionBy(p : Partitioner[K]) : RDD[(K, V)] ⇒ RDD[(K, V)]](https://image.slidesharecdn.com/mapreduceapachesparkindicthreadsunmeshrahul-150304010847-conversion-gate01/85/Scrap-Your-MapReduce-Apache-Spark-24-320.jpg)
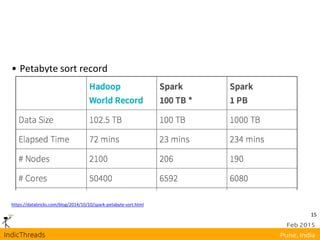
![25
Actions
count() : RDD[T] ⇒ Long
collect() : RDD[T] ⇒ Seq[T]
reduce(f : (T,T) ⇒ T) : RDD[T] ⇒ T
lookup(k : K) : RDD[(K, V)] ⇒ Seq[V] (On hash/range partitioned
RDDs)
save(path : String) : Outputs RDD to a storage system, e.g., HDFS](https://image.slidesharecdn.com/mapreduceapachesparkindicthreadsunmeshrahul-150304010847-conversion-gate01/85/Scrap-Your-MapReduce-Apache-Spark-25-320.jpg)
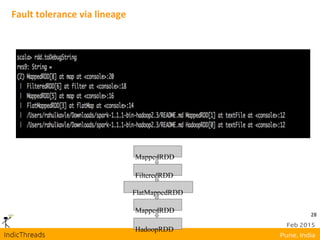







This document discusses the limitations of traditional MapReduce and highlights Apache Spark as an advanced cluster computing engine that addresses issues such as latency and complex workflows. It emphasizes Spark's advantages, including in-memory data caching, a user-friendly programming model, and improved performance due to reduced I/O operations. Additionally, it covers key concepts like Resilient Distributed Datasets (RDDs) and their operations, showcasing Spark's functionality and ease of testing.


































































































