Downloaded 40 times


![Great Hedge of India
• East India Company was one of
the industrial world’s first monopolies.
• They assembled a thorny hedge
(not a wall!) spanning India.
• You paid customs duty to bring salt
over the wall (sorry, hedge).
In 2019, not all graphics cards are allowed to be used
in a Data Center. Monoplies are not good for deep learning!
3
[Image from Wikipedia]](https://image.slidesharecdn.com/052001jimdowlingajitmathews-190513185157/85/ROCm-and-Distributed-Deep-Learning-on-Spark-and-TensorFlow-3-320.jpg)









![Hopsworks Hides ML Complexity
14#UnifiedAnalytics #SparkAISummit
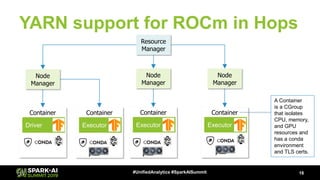
MODEL TRAINING
Feature
Store
HopsML API
[Diagram adapted from “technical debt of machine learning”]
https://www.logicalclocks.com/feature-store/ https://hopsworks.readthedocs.io/en/latest/hopsml/hopsML.html#](https://image.slidesharecdn.com/052001jimdowlingajitmathews-190513185157/85/ROCm-and-Distributed-Deep-Learning-on-Spark-and-TensorFlow-14-320.jpg)

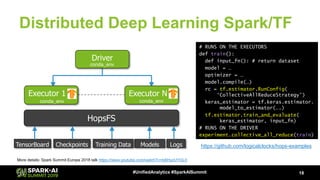
![Distributed Deep Learning Spark/TF
17#UnifiedAnalytics #SparkAISummit
Executor 1 Executor N
Driver
HopsFS
TensorBoard ModelsCheckpoints Training Data Logs
conda_env
conda_env conda_env
# RUNS ON THE EXECUTORS
def train(lr, dropout):
def input_fn(): # return dataset
optimizer = …
model = …
model.add(Conv2D(…))
model.compile(…)
model.fit(…)
model.evaluate(…)
# RUNS ON THE DRIVER
Hparams= {‘lr’:[0.001, 0.0001],
‘dropout’: [0.25, 0.5, 0.75]}
experiment.grid_search(train,HParams)
More details: Spark Summit Europe 2018 talk https://www.youtube.com/watch?v=tx6HyoUYGL0
https://github.com/logicalclocks/hops-examples](https://image.slidesharecdn.com/052001jimdowlingajitmathews-190513185157/85/ROCm-and-Distributed-Deep-Learning-on-Spark-and-TensorFlow-17-320.jpg)
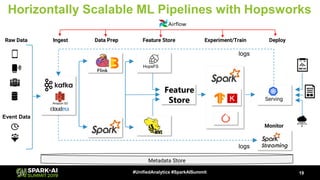
![Pipelines from Jupyter Notebooks
20#UnifiedAnalytics #SparkAISummit
Convert .ipynb to .py
Jobs Service
Run .py or .jar
Schedule using
REST API or UI
materialize certs, ENV variables
View Old Notebooks, Experiments and Visualizations
Experiments &
Tensorboard
PySpark Kernel
.ipynb (HDFS contents)
[logs, results]
Livy Server
HopsYARNHopsFS
Interactive
materialize certs, ENV variables](https://image.slidesharecdn.com/052001jimdowlingajitmathews-190513185157/85/ROCm-and-Distributed-Deep-Learning-on-Spark-and-TensorFlow-20-320.jpg)





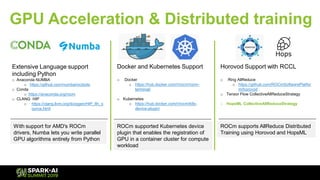
The document discusses innovations in machine learning and distributed deep learning, highlighting various technologies like AMD ROCm, Docker, and Kubernetes. It provides performance benchmarks for NVIDIA and AMD graphics cards and outlines the support for machine learning frameworks and libraries. Furthermore, it emphasizes the significance of open-source solutions for machine learning, data management, and integration within cloud services.




































































![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)

