Download as PDF, PPTX









![13
Chime telescope
§ Solving one of most puzzling new mystery in
astronomy: Fast Radio Bursts (FRB)
Multi Pflops AMD FirePro S9300 x2 cluster
Three-Dimensional Mapping Of The Universe
“CHIME has a truly novel design. No moving parts!
[…] Moreover, it will have 2048 antennas and a
massive software correlator that allows it to ‘point’ in
different directions all in software.”
- Astrophysicist Victoria Kaspi, Gerhard Herzberg 2016 Prize Laureate
Image: Prof. Keith Vanderlinde, Dunlap Institute, University of Toronto.](https://image.slidesharecdn.com/amditstimetoroc-160420141806/75/AMD-It-s-Time-to-ROC-13-2048.jpg)

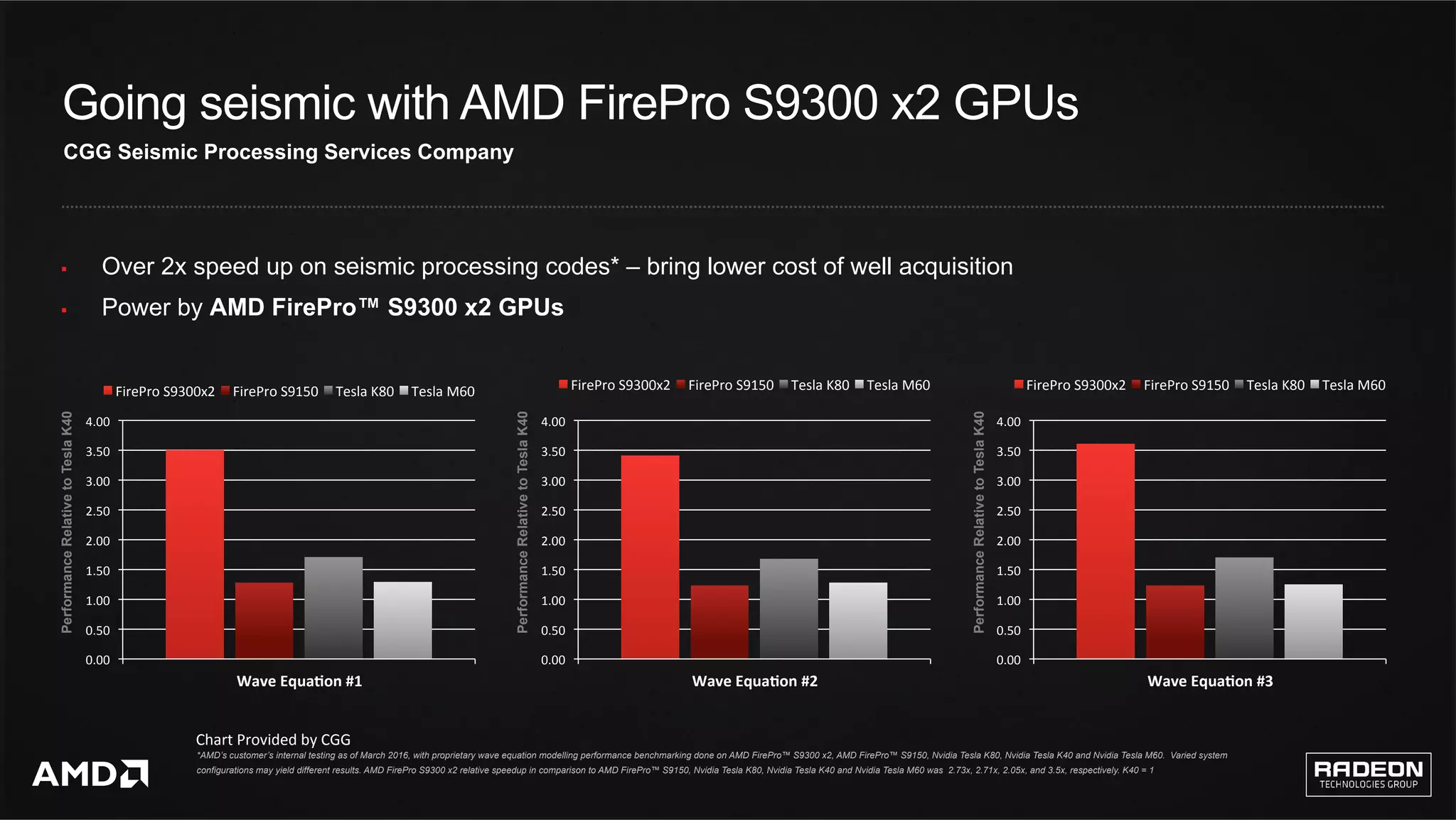

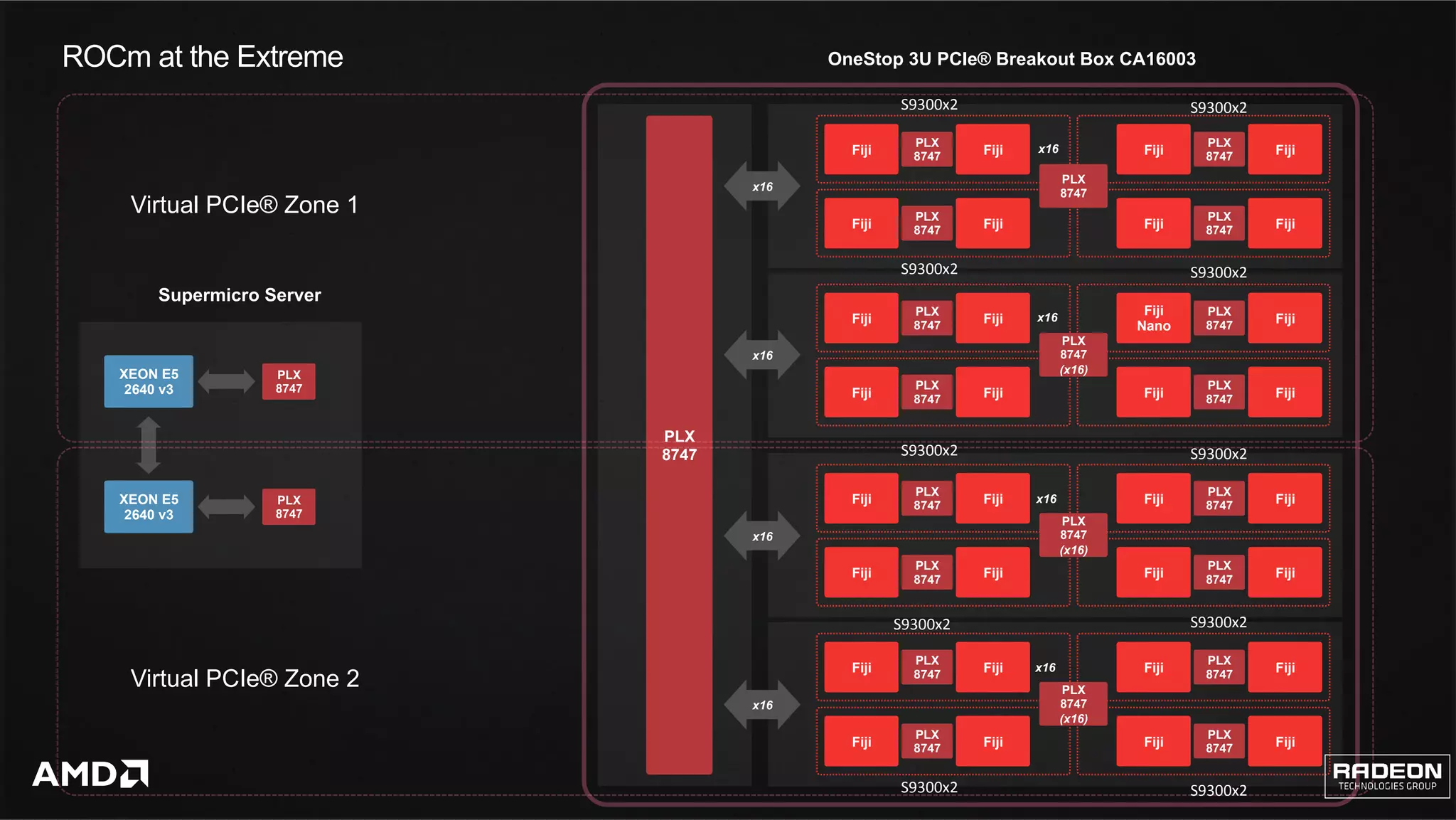



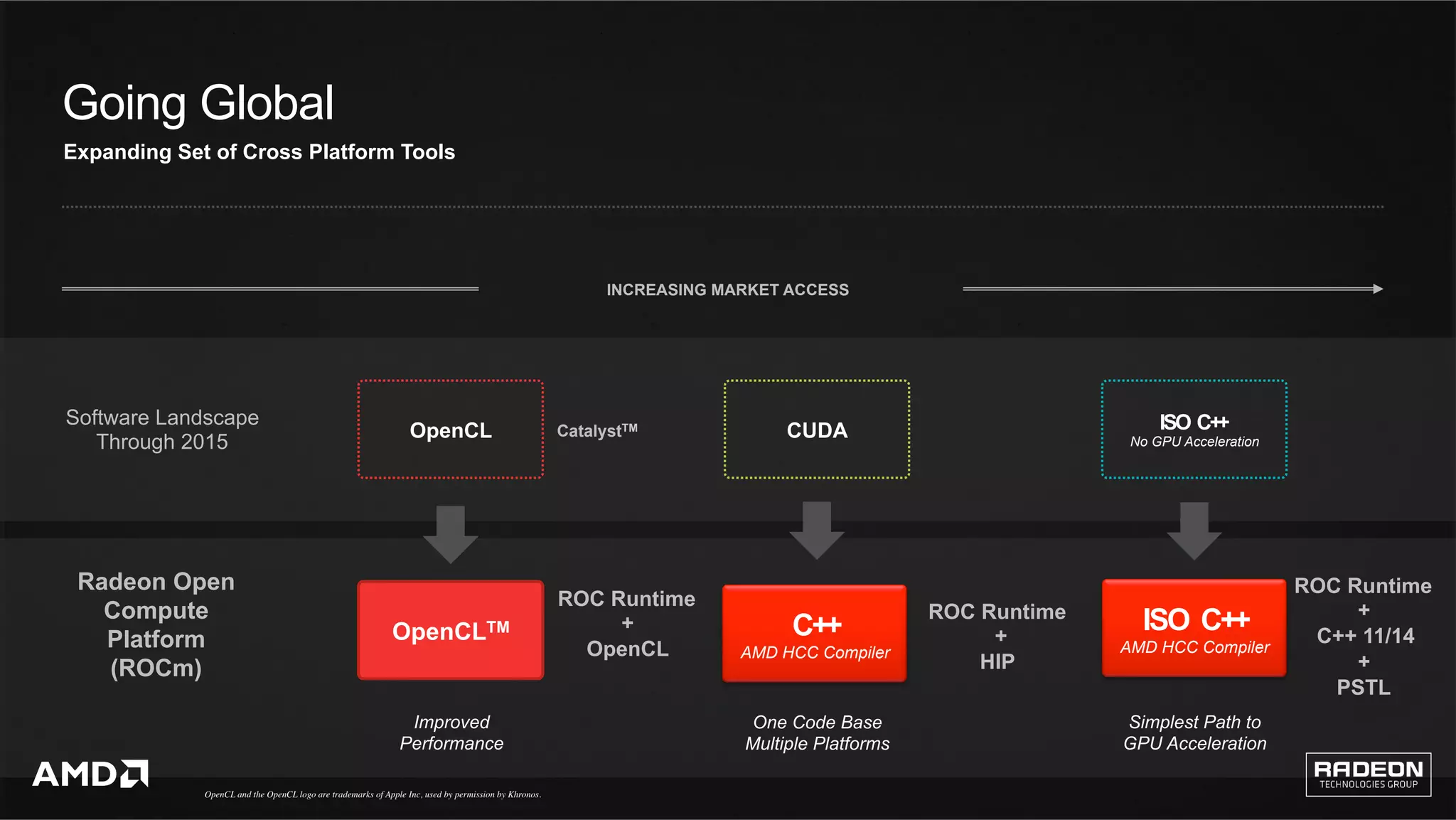
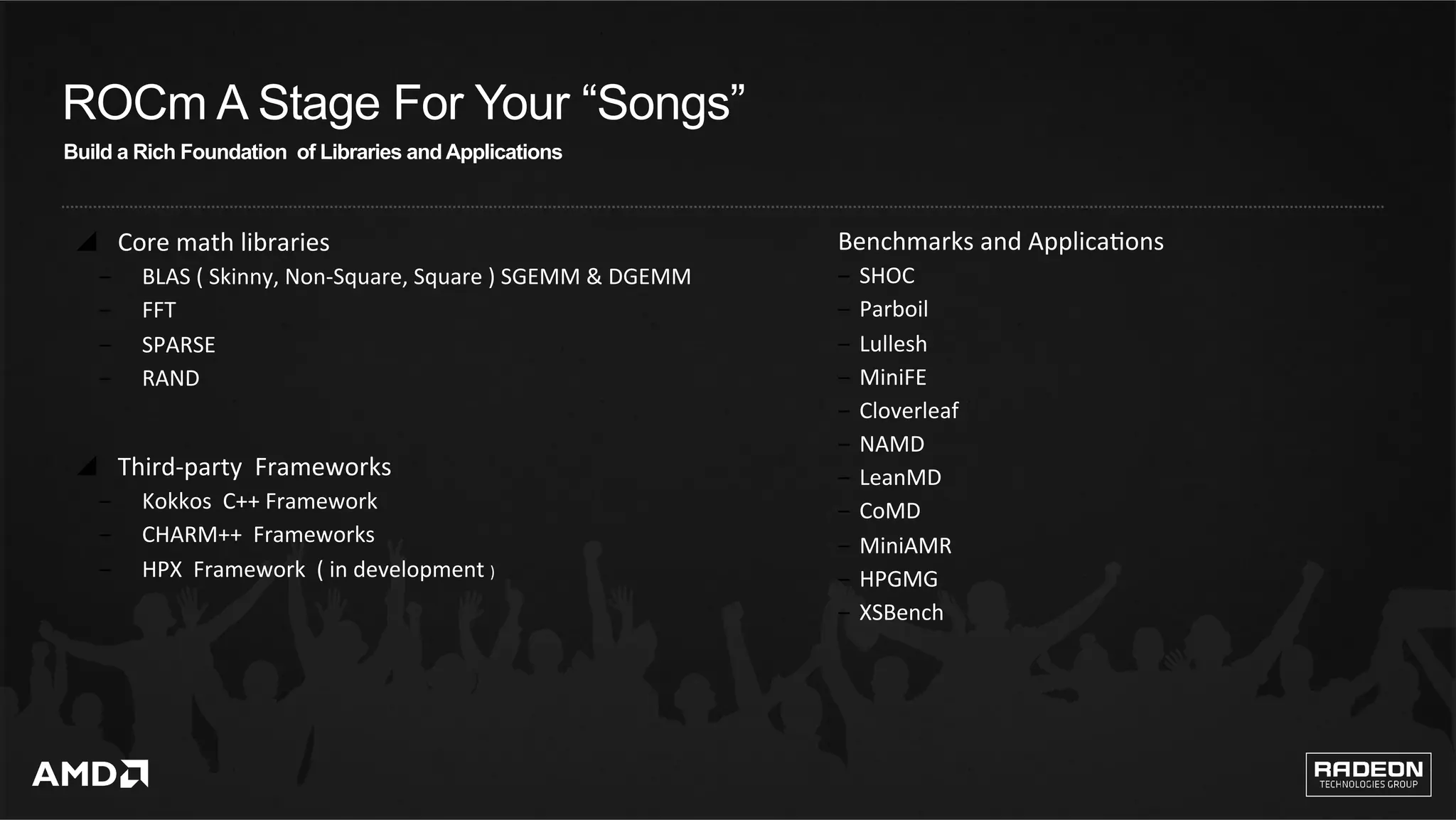
The Radeon Open Compute (ROCm) platform aims to support high-performance computing and ultrascale computing markets with a commitment to open-source development and enhanced computing capabilities. It features a new compilation model, enhanced multi-GPU memory management, and compatibility with existing code through the Heterogeneous Compute Interface for Portability (HIP). Additionally, ROCm focuses on supporting machine learning frameworks and provides tools for various applications across industries.























































































