Download as PDF, PPTX















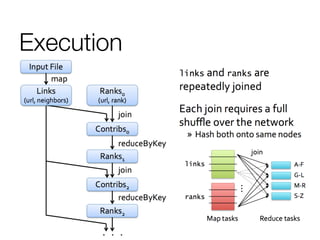

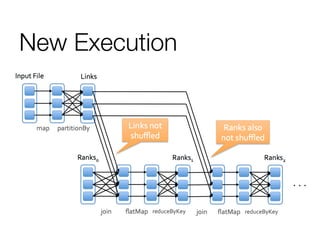

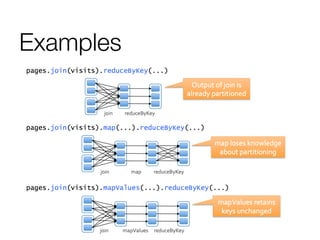

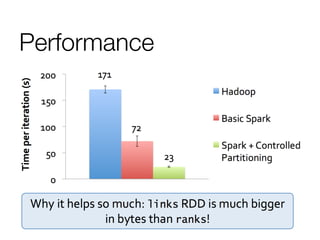



This document discusses distributed optimization techniques in Spark. It provides examples of convex and spectral optimization problems and describes how gradient descent and PageRank algorithms can be optimized in a distributed setting. Specifically, it explains how caching neighbor lists in RAM and controlling RDD partitioning can avoid repeated network communication, improving performance of algorithms like PageRank that involve repeated joins or matrix multiplications.











































































