Download to read offline




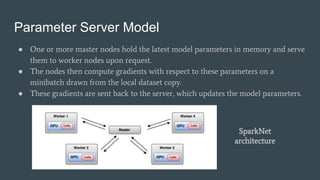


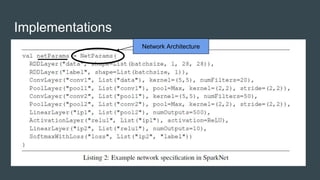
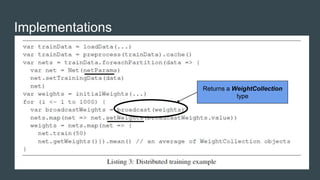


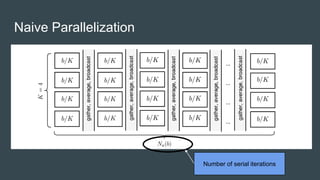

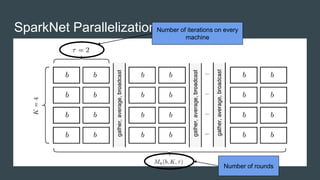

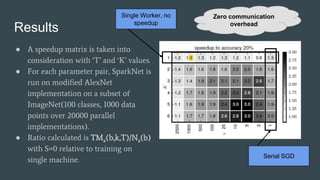
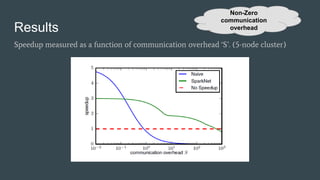
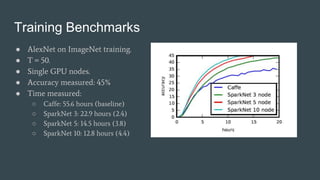
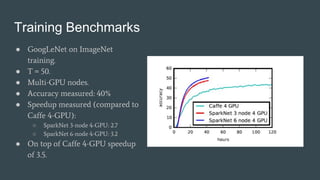


SparkNet is a scalable framework for training deep networks on Apache Spark and Caffe, allowing asynchronous, distributed processing with minimal hardware needs. It utilizes a parameter server model for efficient gradient computation across worker nodes while addressing the challenges of conventional parallelization. Training benchmarks demonstrate significant speedup over baseline methods like Caffe, achieving better training times and maintaining competitive accuracy.


































































