Downloaded 38 times










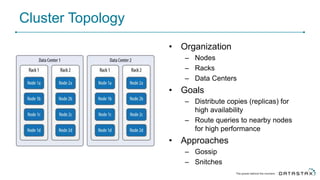
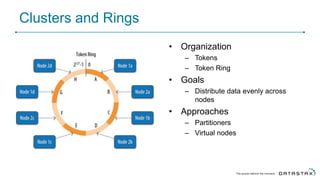
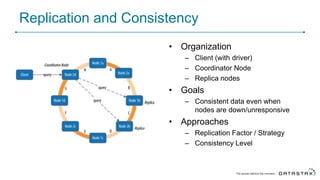





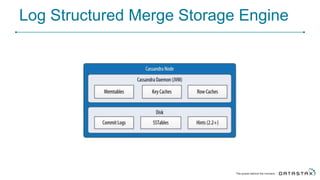

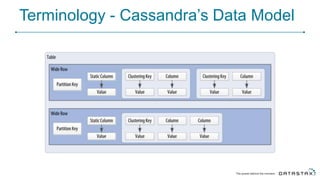
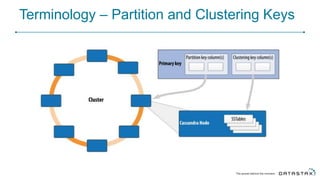
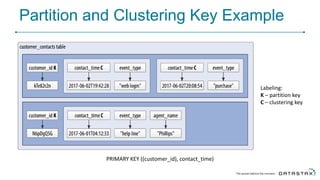



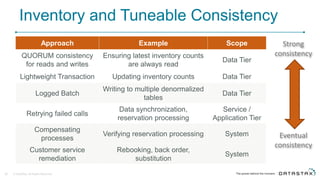
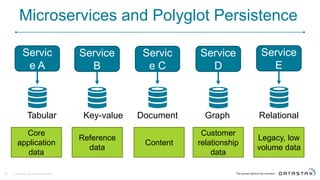





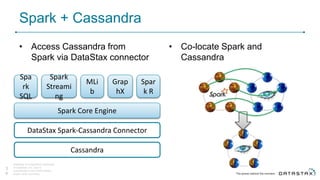
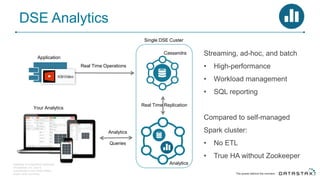




Cassandra is a distributed database that is especially well-suited for handling large volumes of writes and data across many servers. It provides high availability through replication and tunable consistency levels. The document discusses Cassandra's architecture including its use of a ring topology, log-structured storage, and data model using a partition key and clustering columns. It also explains how Cassandra can be used as part of a polyglot persistence strategy along with complementary technologies like Spark and DSE Analytics.






















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


















