Downloaded 17 times















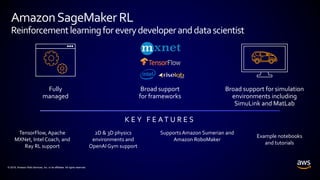
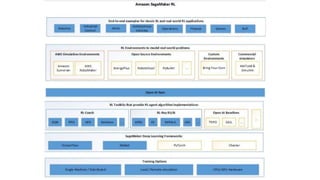





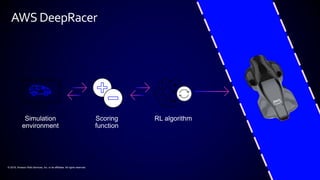




This document provides an introduction to reinforcement learning (RL). It defines RL as an algorithm that interacts with an environment to learn optimal decision-making policies through trial-and-error using rewards. Examples of RL applications include robotics, games, resource management. Amazon's SageMaker platform supports RL with various frameworks and environments. Amazon's DeepRacer product applies RL to autonomous racing using 1/18th scale cars.








































































