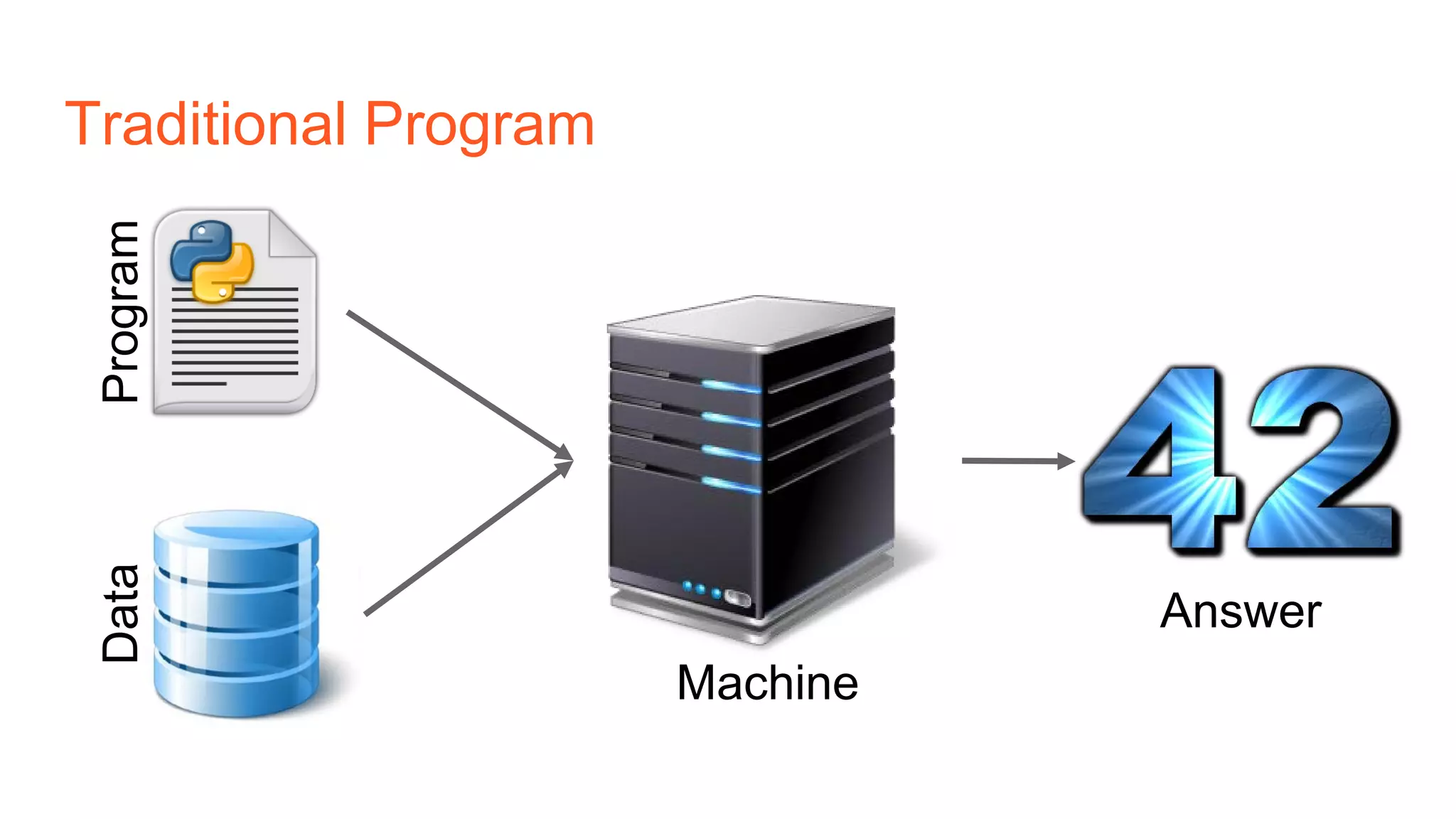
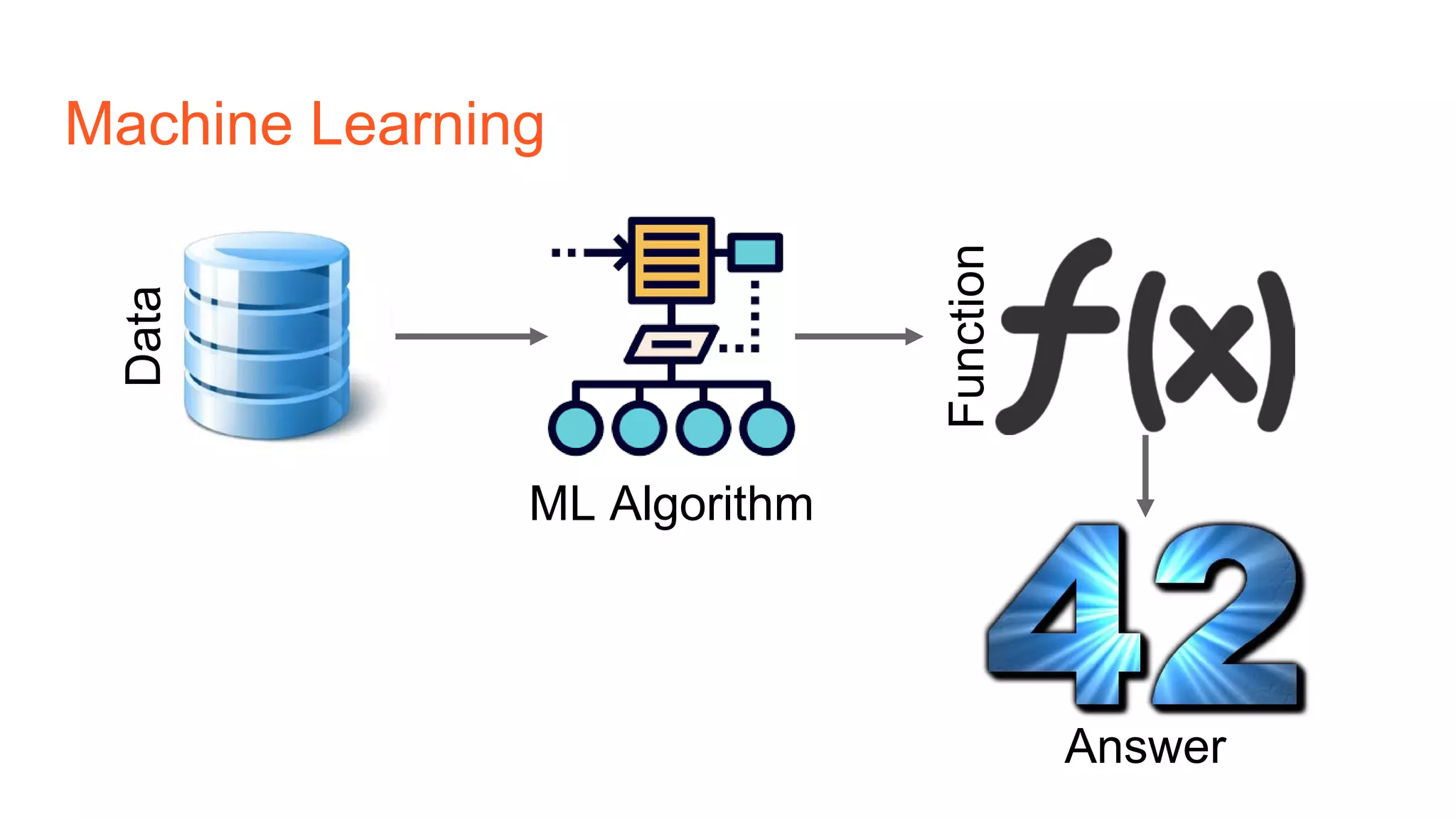
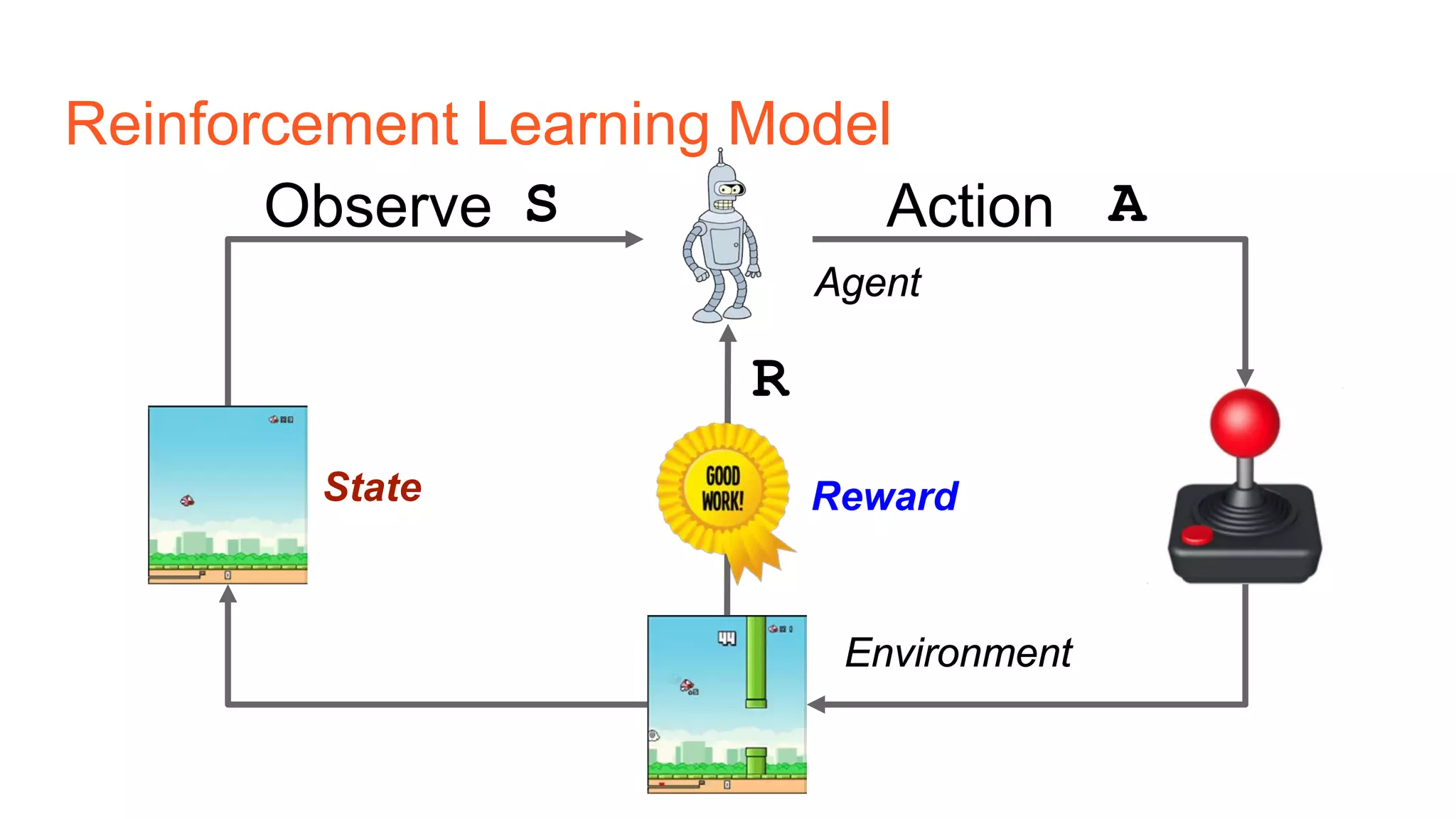
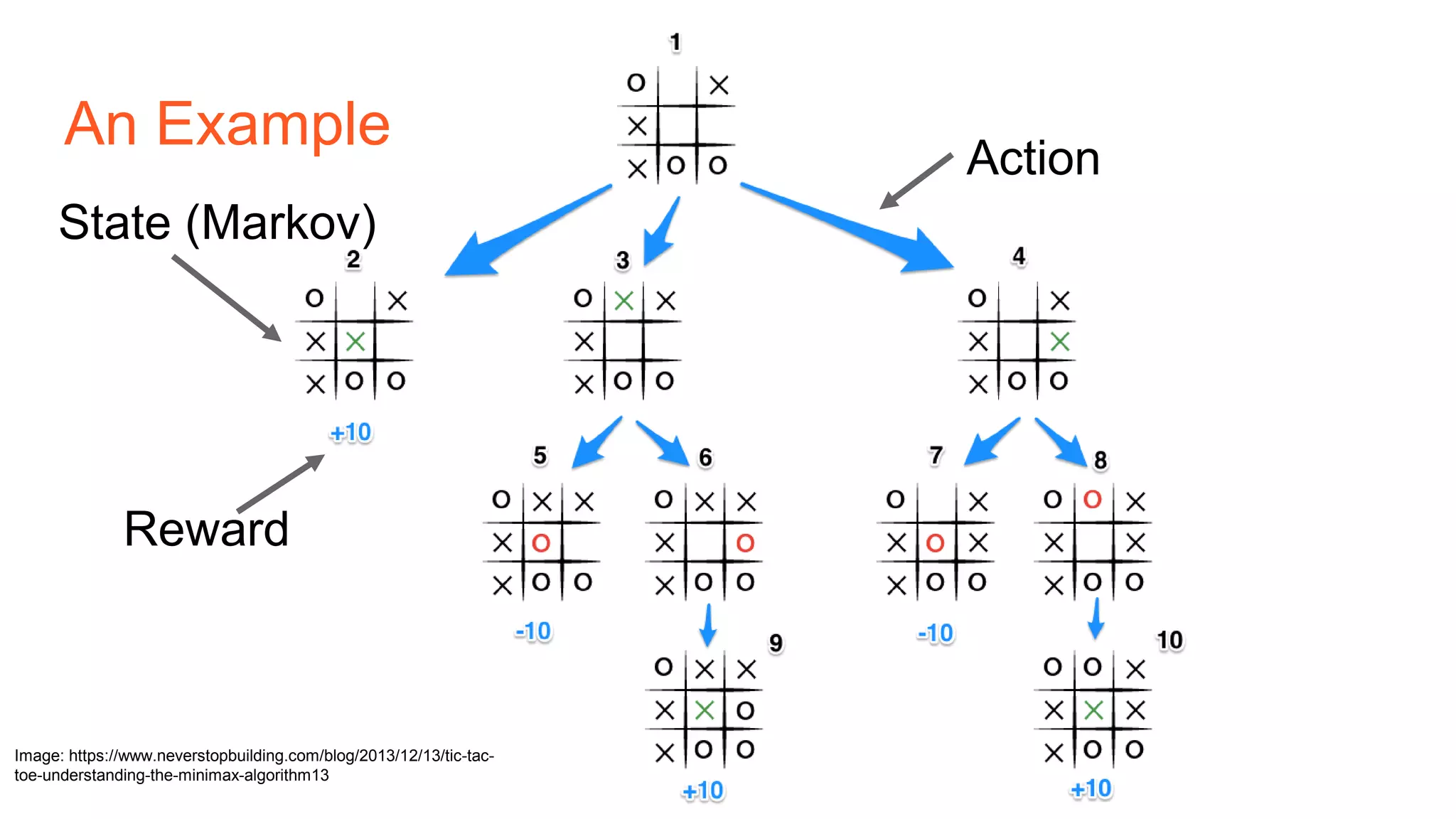
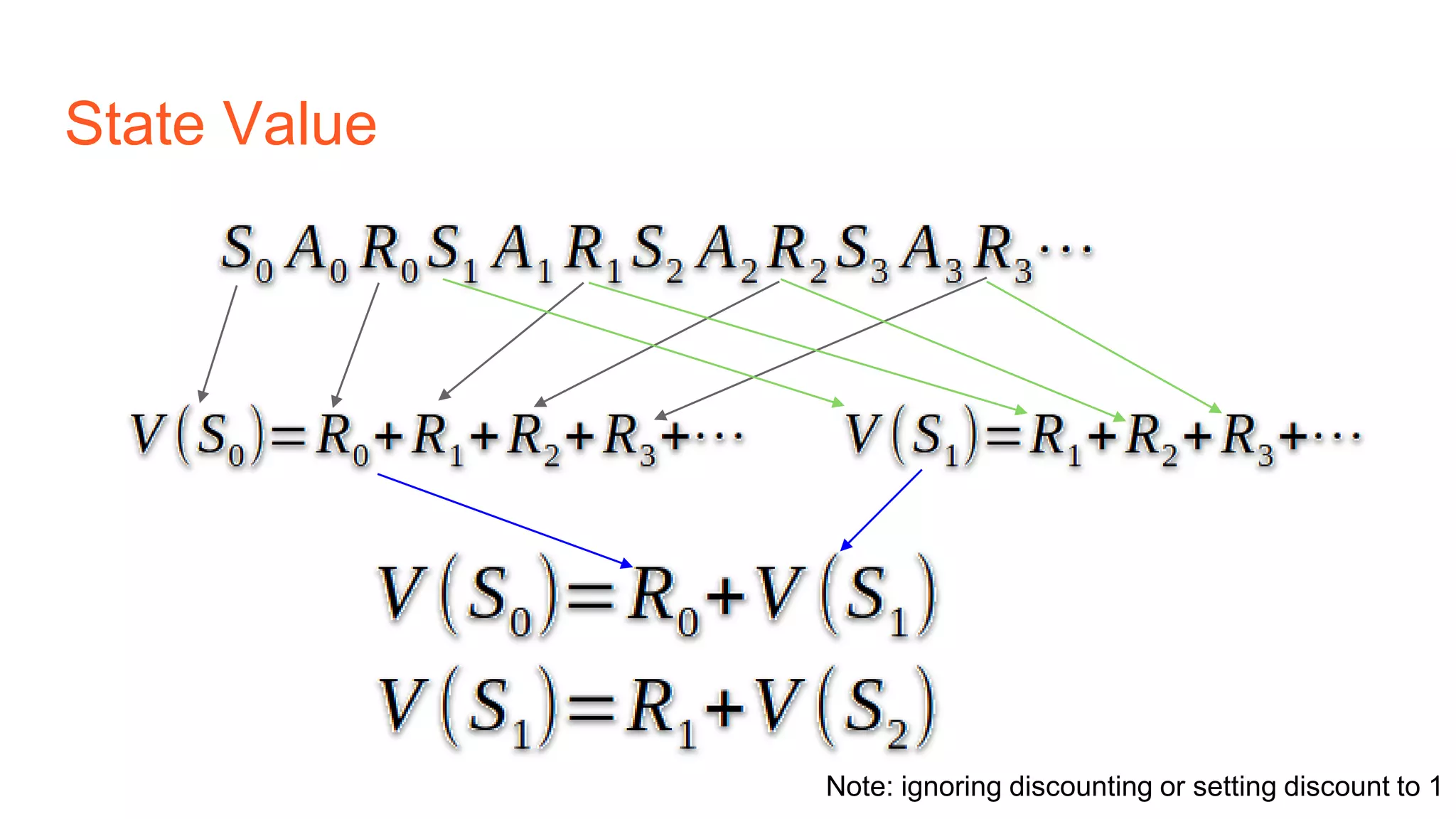
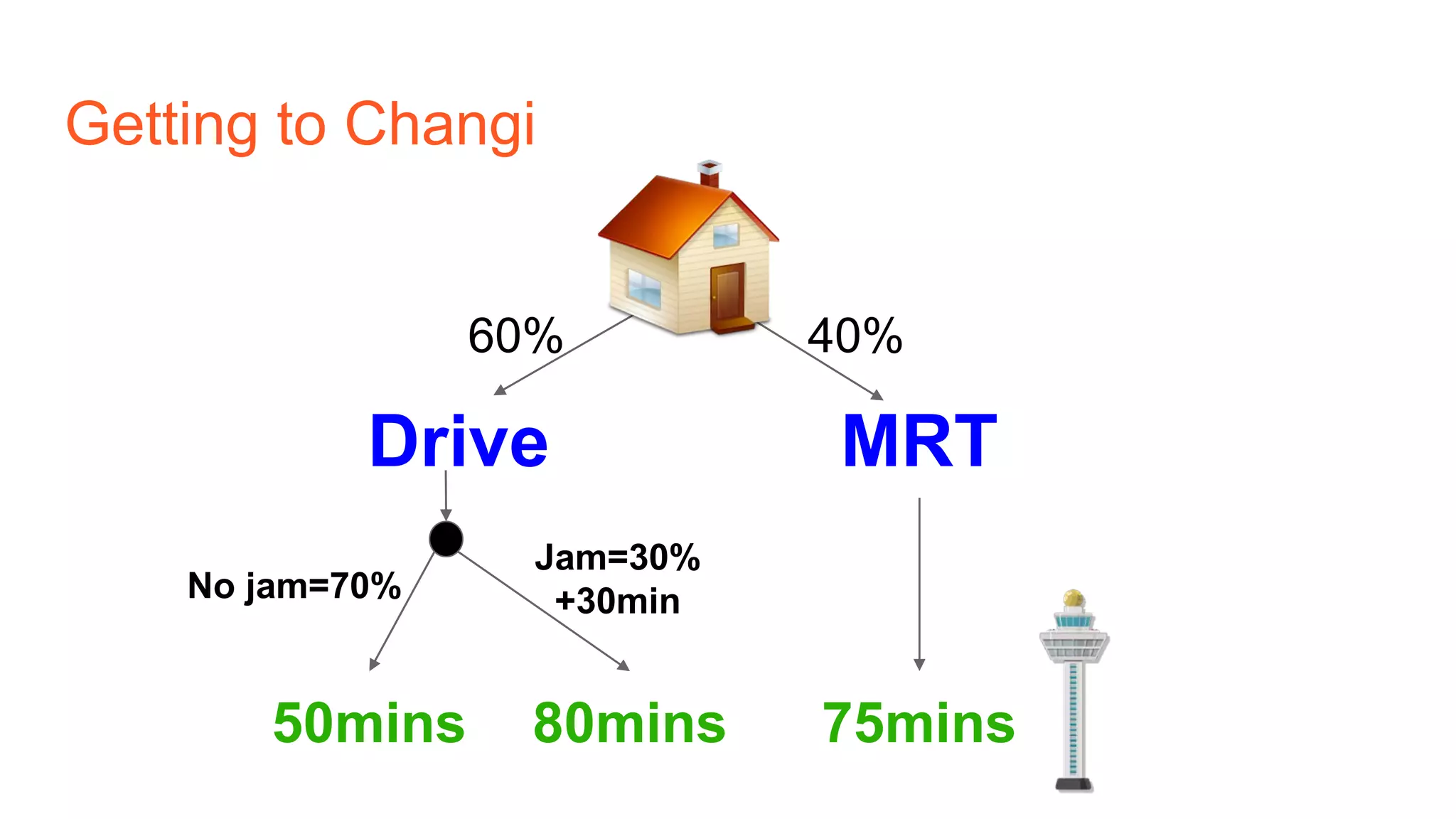
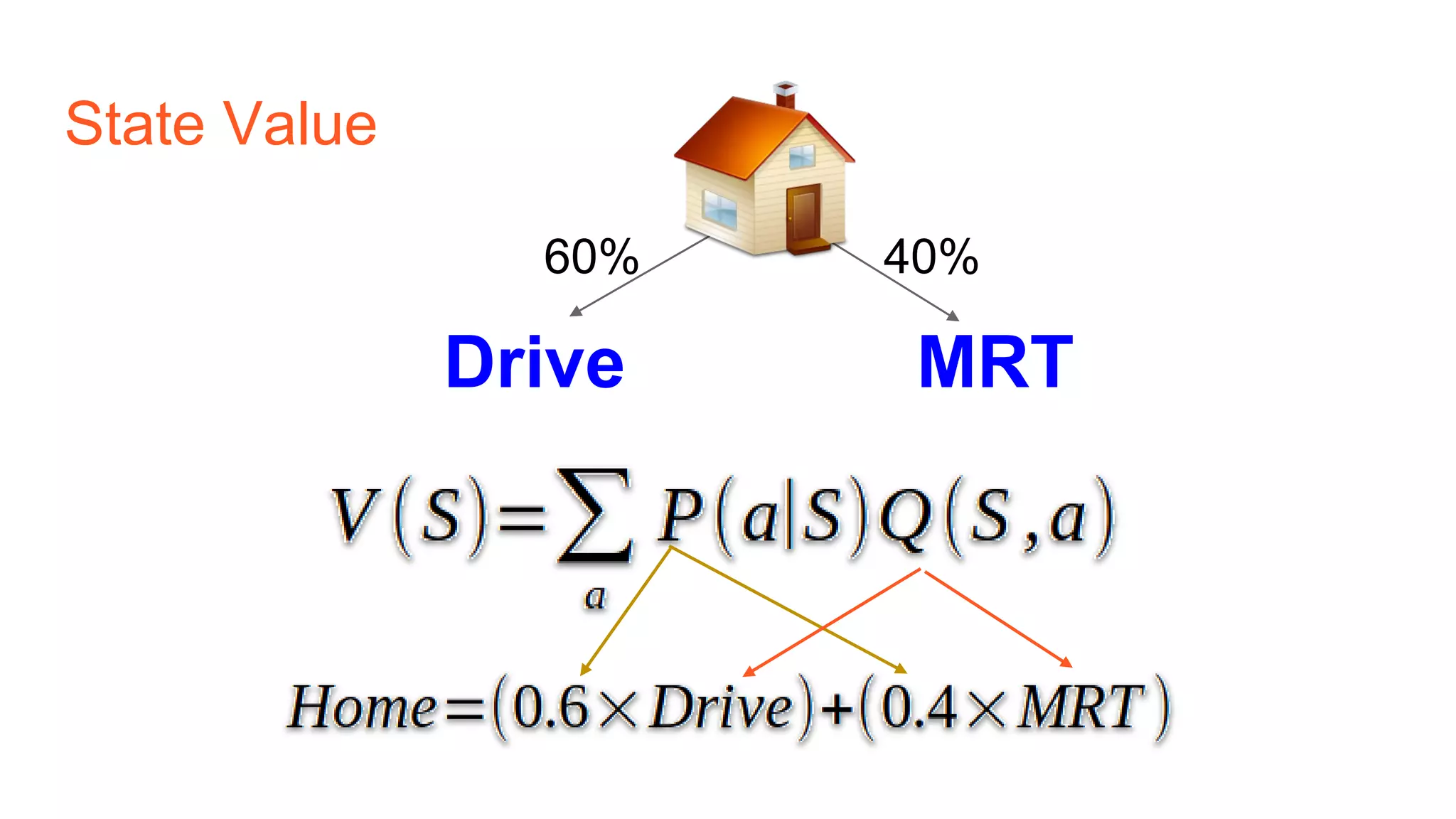
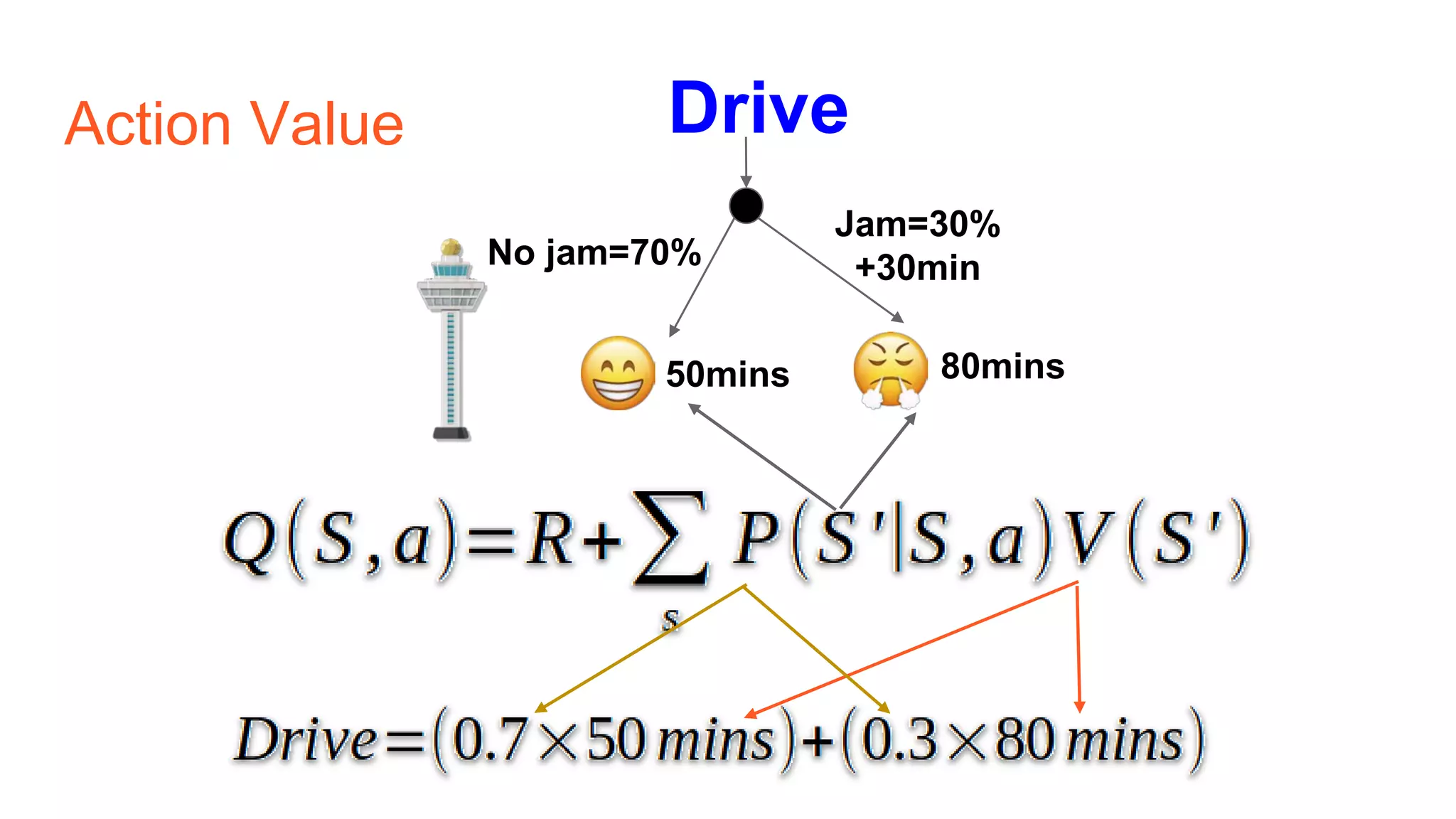
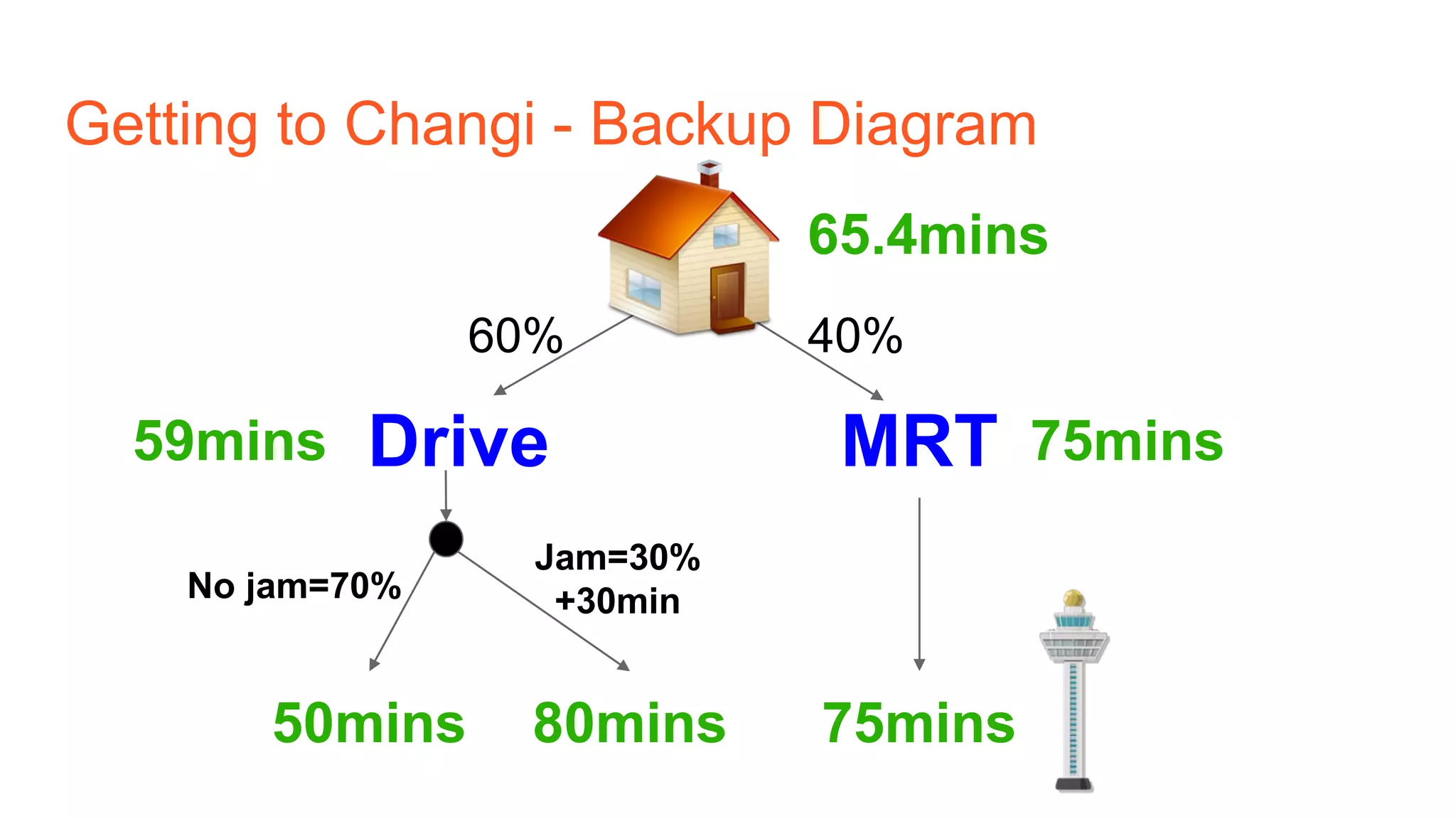
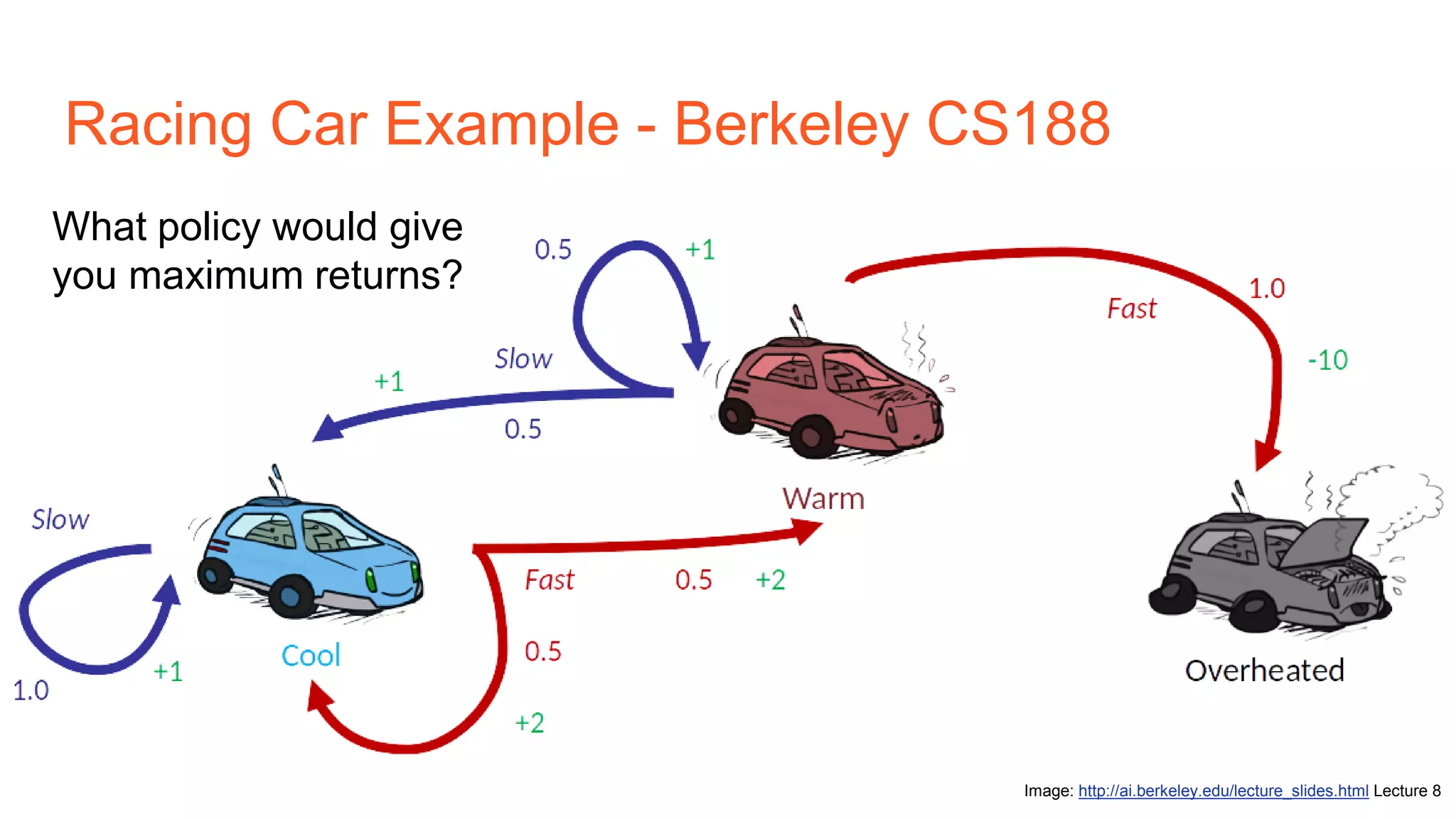
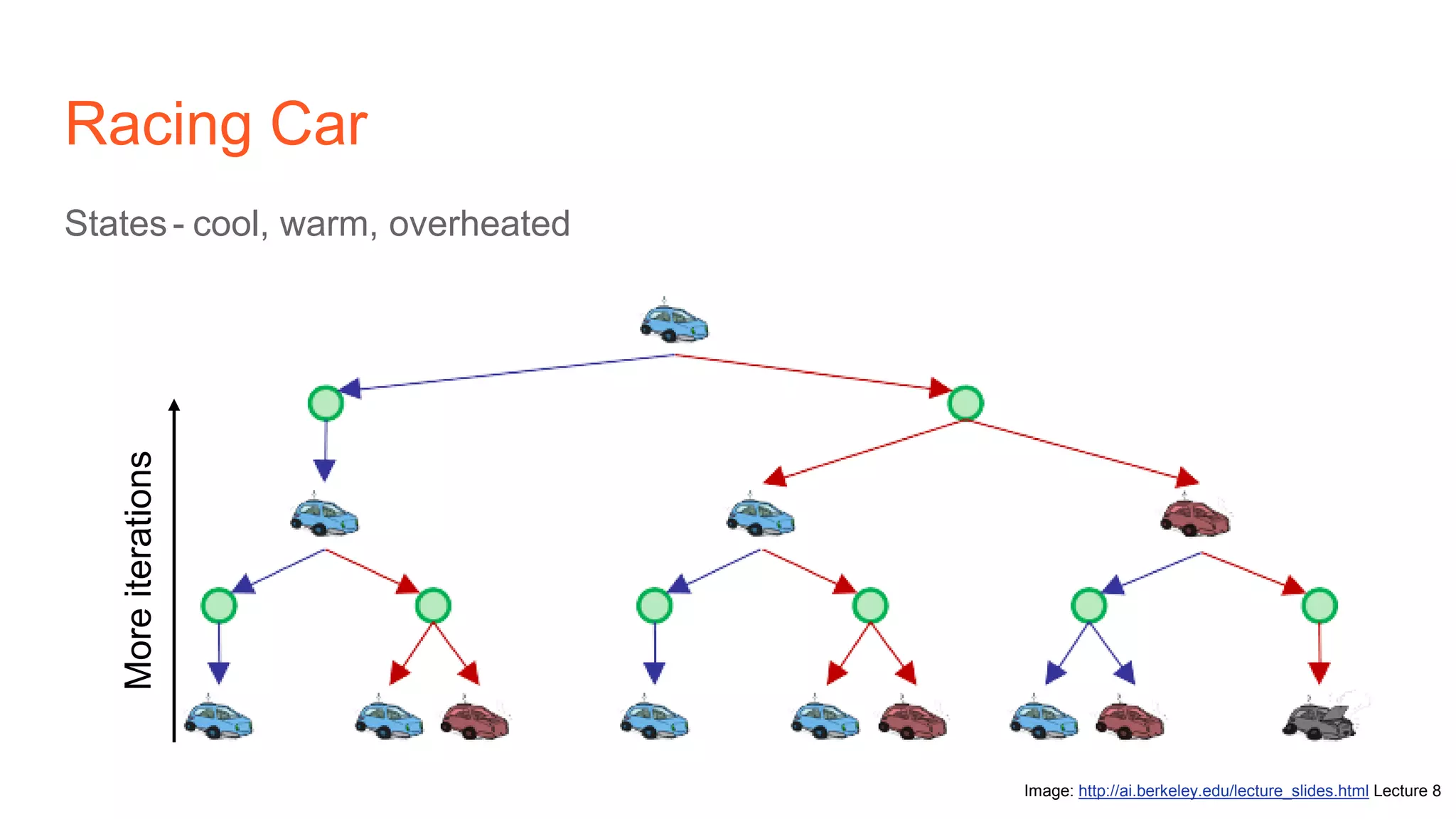
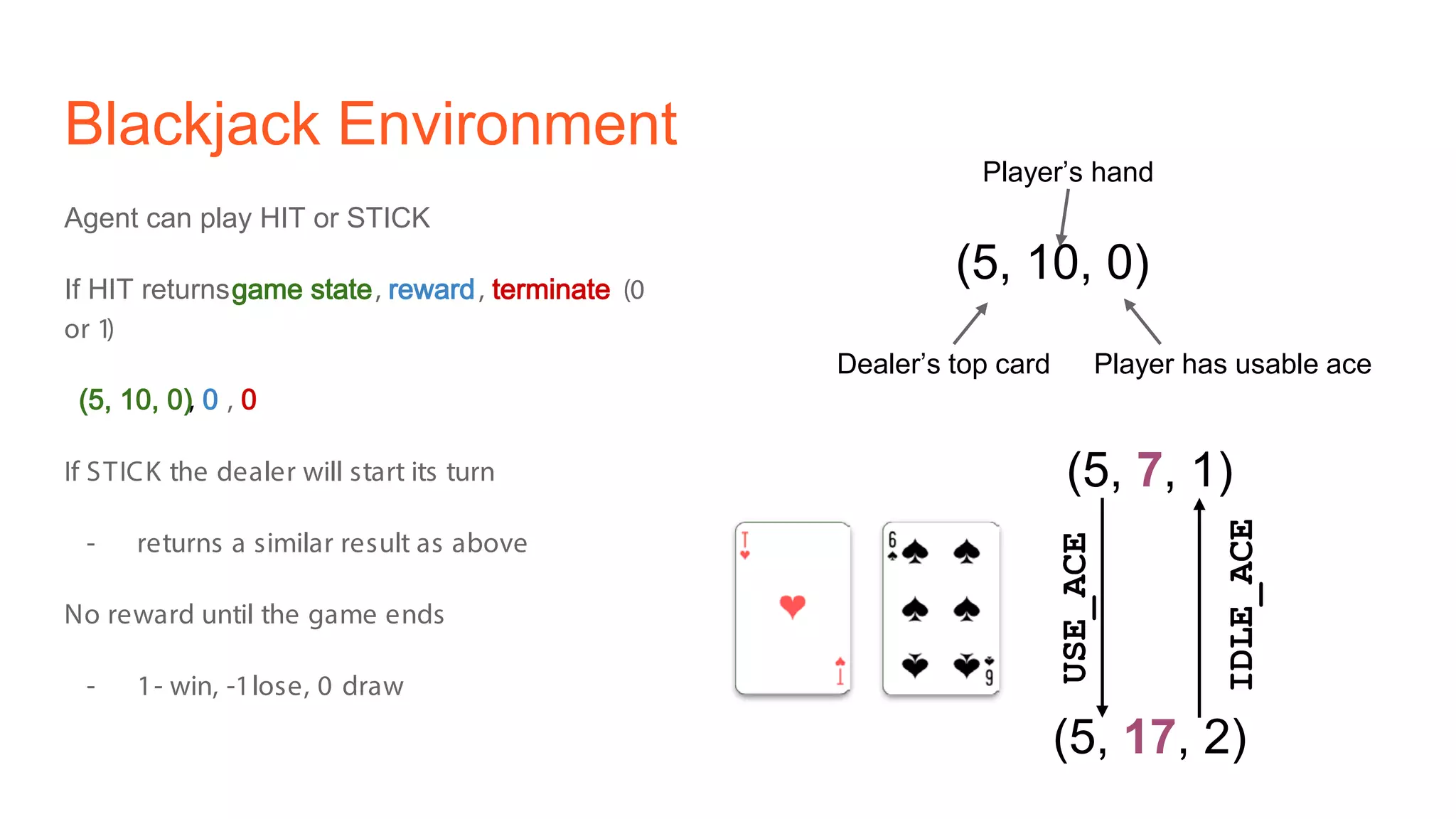
The document provides an introduction to reinforcement learning concepts like Markov decision processes, Monte Carlo methods, and epsilon-greedy policies and uses the example of training an agent to play the card game Blackjack using reinforcement learning. It describes the Blackjack environment and actions available to the agent as it learns through trial-and-error to develop a policy for maximizing its chances of winning games against a dealer.