Downloaded 19 times



![Stable Learning Rates (Quadratic) Stability is determined by the eigenvalues of this matrix. Eigenvalues of [ I - A ]. Stability Requirement: ( i - eigenvalue of A )](https://image.slidesharecdn.com/algoritmosgdngc-090922014009-phpapp02/85/REDES-NEURONALES-Performance-Optimization-6-320.jpg)
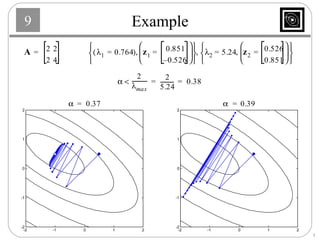

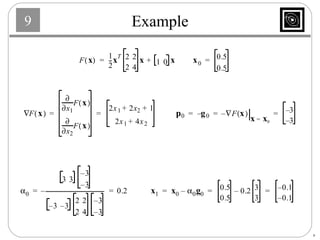
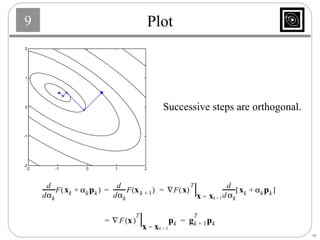

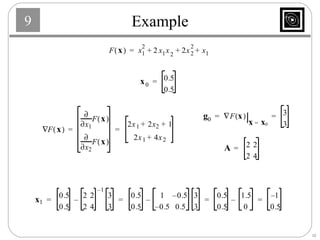
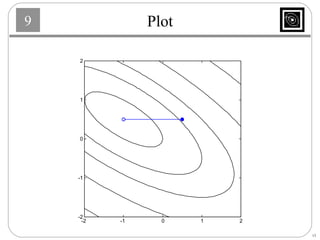
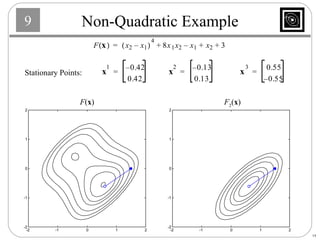
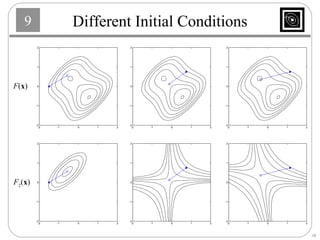




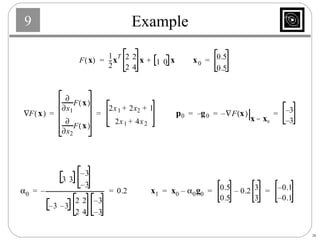
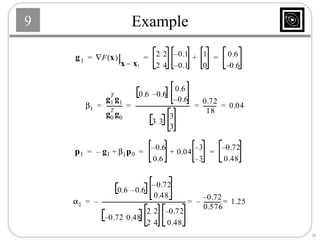
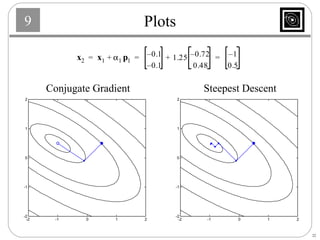

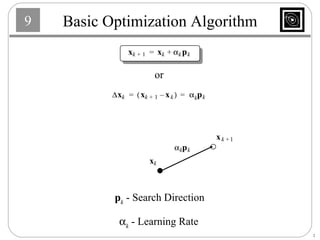
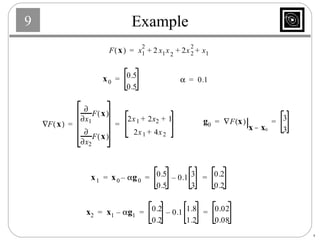
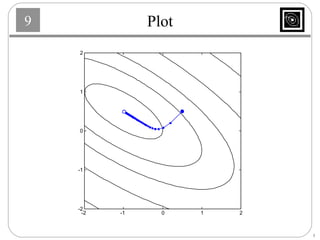
This document discusses several basic optimization algorithms: 1) Steepest descent chooses the search direction to maximize decrease in the function at each step. 2) Newton's method approximates the function as a quadratic and finds the stationary point by setting the gradient of this approximation to zero. 3) Conjugate gradient methods choose subsequent search directions to be conjugate to improve convergence for non-quadratic functions. The directions are updated to be conjugate to previous directions.









![ARIMA Models - [Lab 3]](https://cdn.slidesharecdn.com/ss_thumbnails/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

































































































