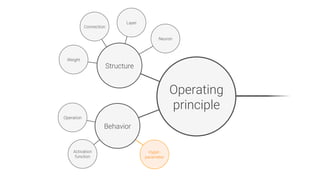
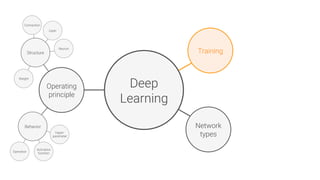
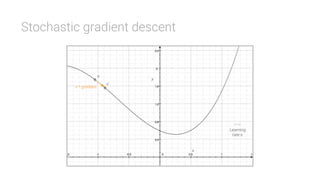
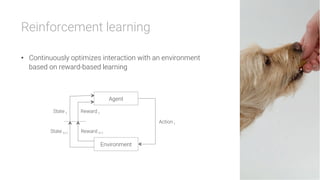
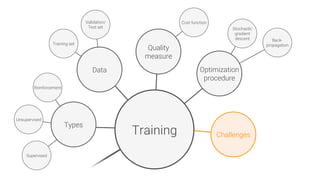
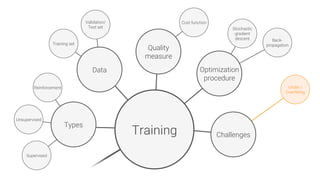
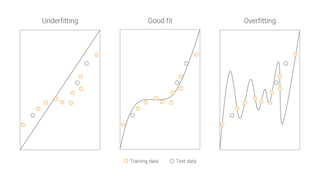
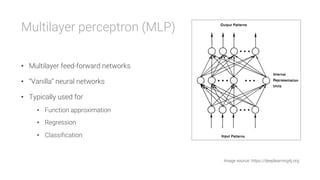
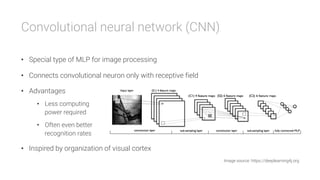
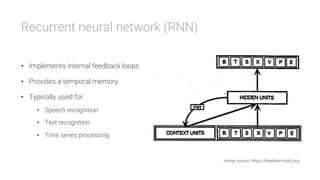
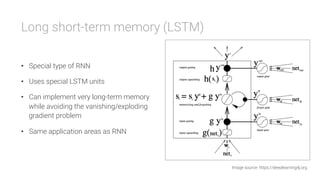
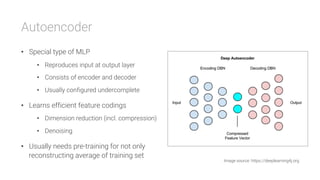
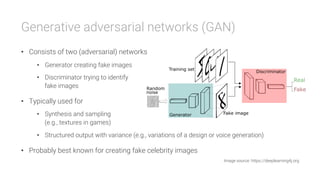
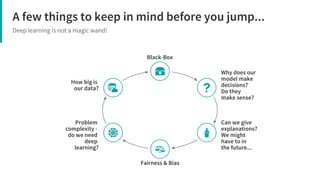
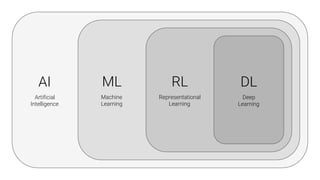
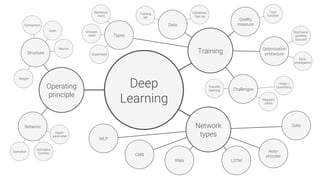
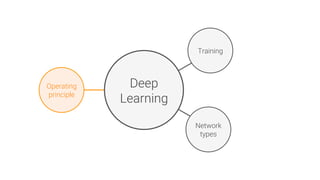
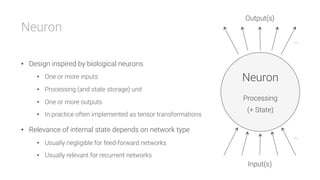
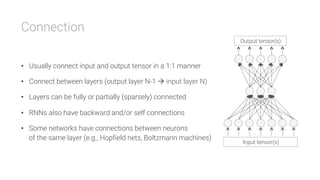
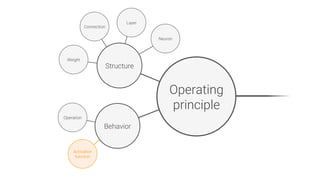
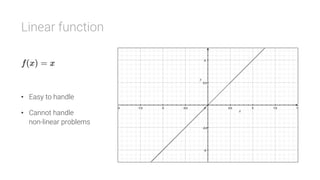
The document provides an overview of deep learning, its significance in various professional domains, and its evolution from traditional artificial intelligence to advanced models implementing neural networks. It highlights key concepts such as supervised and unsupervised learning, various network types including CNNs and RNNs, and discusses challenges like overfitting and the need for robust mathematical understanding. The authors emphasize the rapidly evolving nature of deep learning and the importance of continuously engaging with the field through research and practice.






















![Logistic sigmoid function
• Very widespread
• Delimits output to [0, 1]
• Vanishing gradient
problem](https://image.slidesharecdn.com/deeplearning-180427063627/85/Deep-learning-a-primer-48-320.jpg)
![Hyperbolic tangent
• Very widespread
• Delimits output to [-1, 1]
• Vanishing gradient
problem](https://image.slidesharecdn.com/deeplearning-180427063627/85/Deep-learning-a-primer-49-320.jpg)