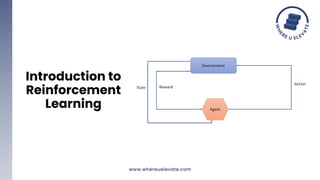
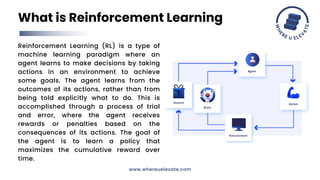
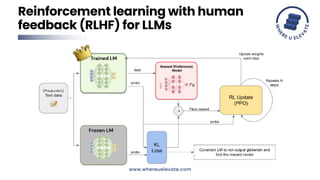
The document discusses reinforcement learning with human feedback (RLHF) for improving language models. RLHF incorporates human feedback during training to refine models. This allows models to consider the outcomes of their actions and modify their behavior. Examples where RLHF could enhance language models are text generation, dialogue systems, translation, summarization, and question answering by improving quality through human feedback during training.