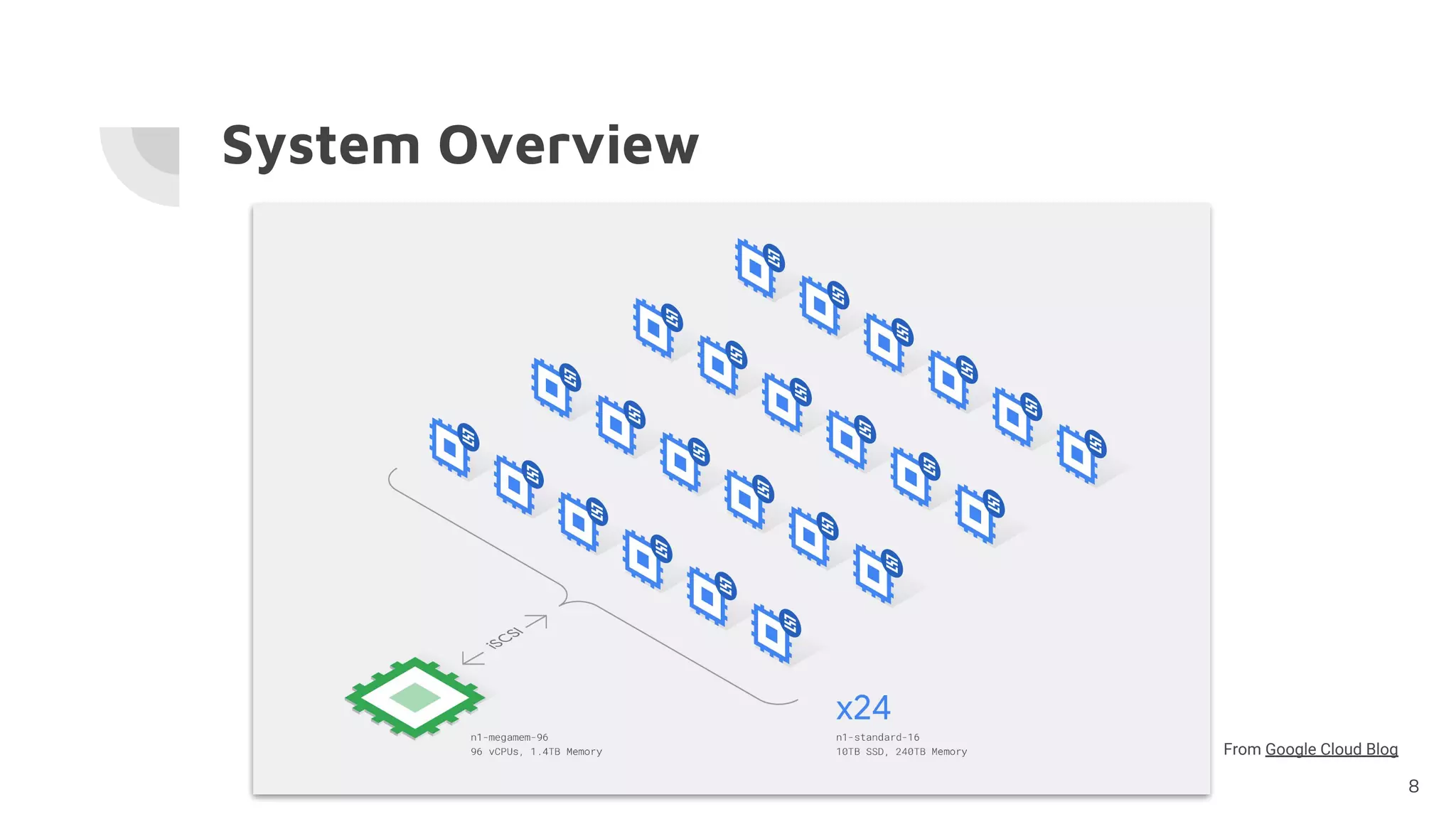
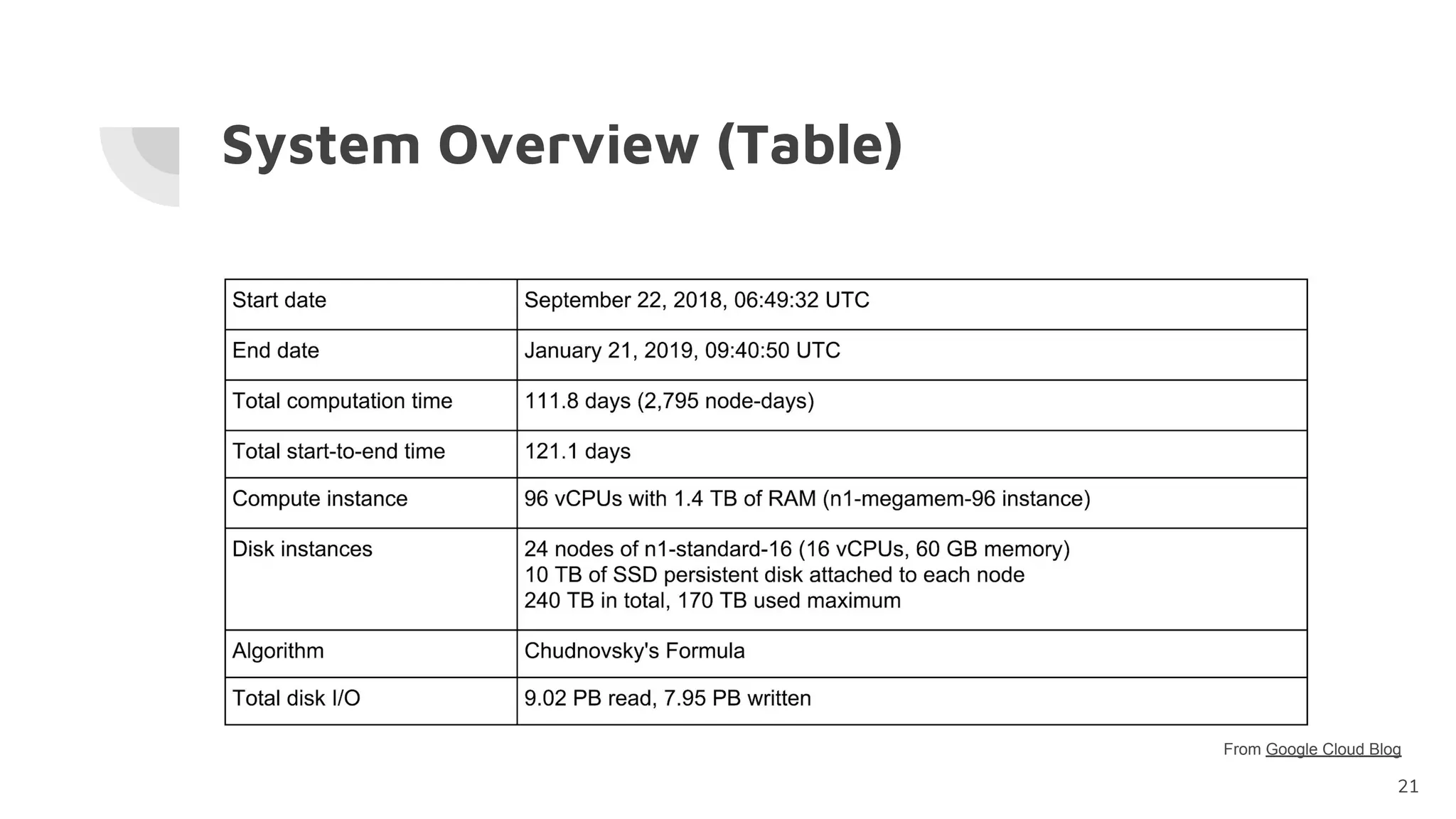
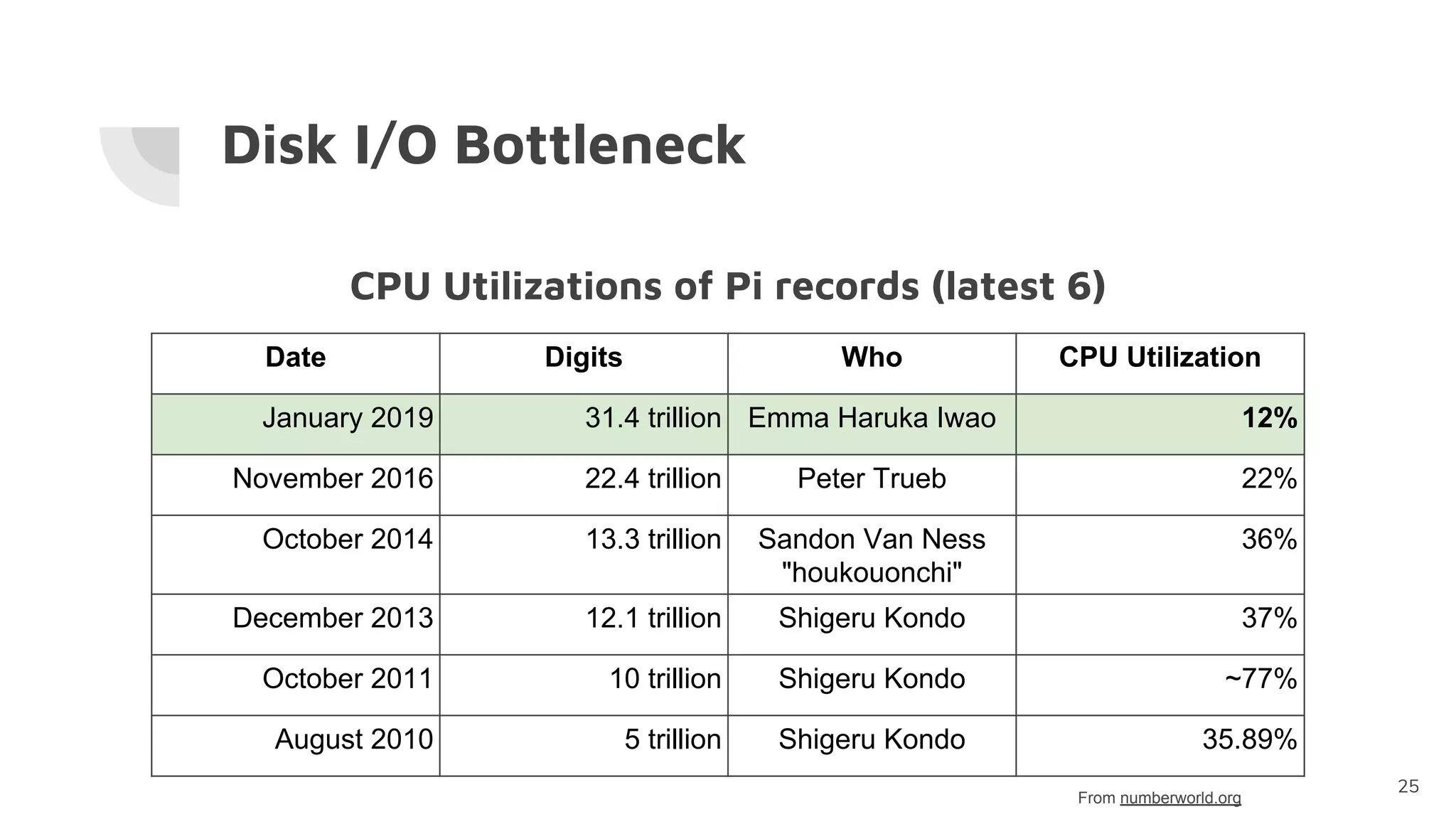
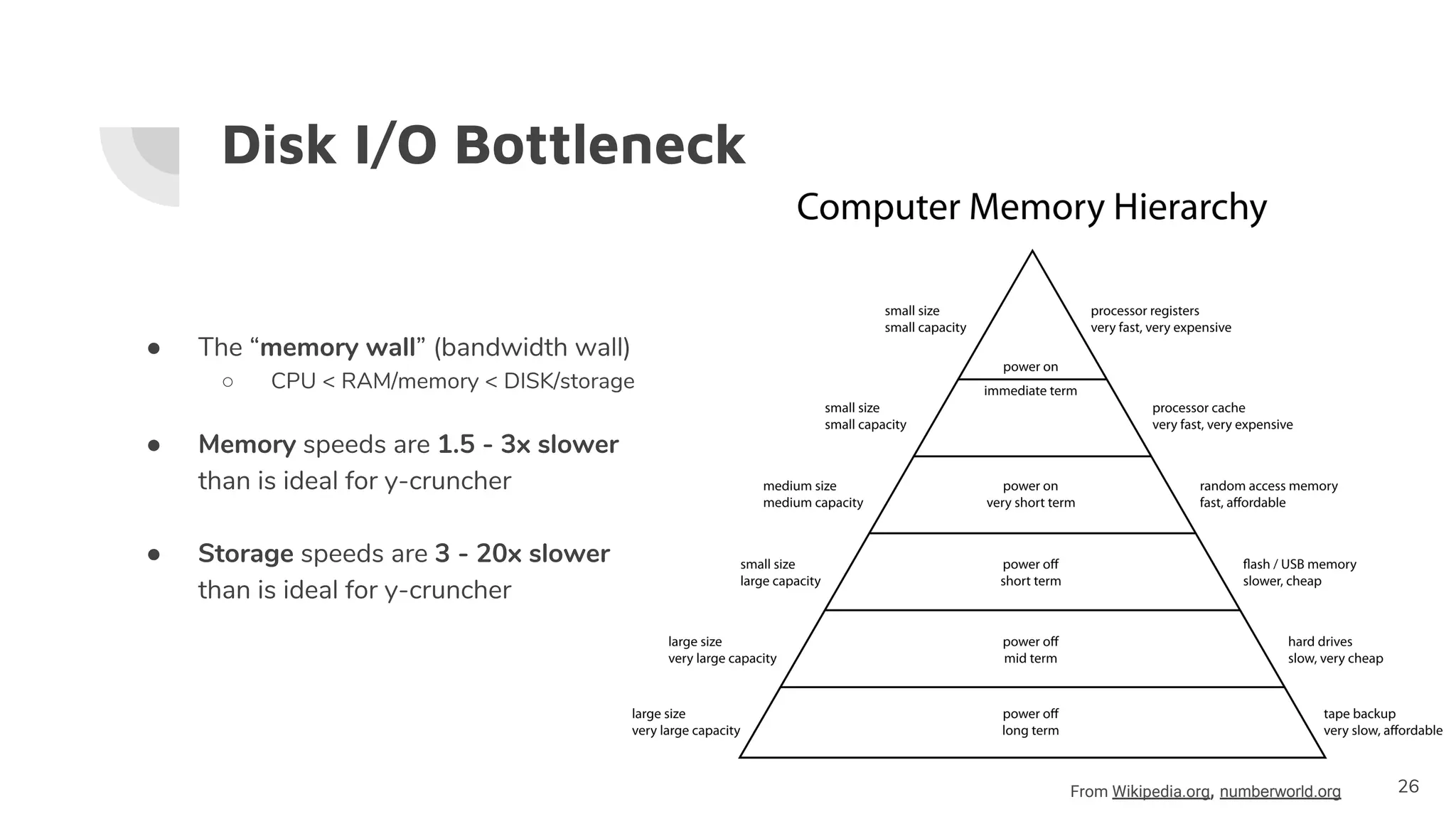
The document discusses the successful computation of pi to a record-breaking 31.4 trillion decimal digits using 'y-cruncher' on Google Cloud, taking 121 days and highlighting the challenges related to storage bandwidth and error detection. Key contributors included Emma Haruka Iwao and Alexander J. Yee, who faced difficulties such as hardware errors and load imbalances during computation. The findings underscore the importance of storage bandwidth and error detection in long-duration computations, acknowledging limitations in error coverage.













![Pi Computation - Chudnovsky formula[a]
with A = 13591409, B = 545140134, C = 640320
Every iteration in the n loop, the generated Pi digits is increased by 14 digits.
“It was evaluated with the binary splitting algorithm. The asymptotic running time is O( M(n)
log(n)^2 ) for a n limb result. It is worst than the asymptotic running time of the
Arithmetic-Geometric Mean algorithms of O(M(n) log(n)) , but it has better locality and many
improvements can reduce its constant factor.” [b]
15
[b] F. Bellard, “Computation of 2700 billion decimal digits of Pi using a Desktop Computer Evaluation of
the Chudnovsky series,” Computer (Long. Beach. Calif)., vol. 2010, pp. 1–11, 2010.
[a] D. V. Chudnovsky and G. V. Chudnovsky, “Approximations and complex multiplication according to
Ramanujan, in Ramanujan Revisited,” Academic Press Inc., Boston, p. 375-396 & p. 468-472, 1988.](https://image.slidesharecdn.com/20190422journalclubshare-190422064603/75/Reading-Pi-in-the-sky-Calculating-a-record-breaking-31-4-trillion-digits-of-Archimedes-constant-on-Google-Cloud-15-2048.jpg)

















































![[EMNLP2017読み会] Efficient Attention using a Fixed-Size Memory Representation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2017-171122025333-thumbnail.jpg?width=640&height=640&fit=bounds)















































