Downloaded 47 times












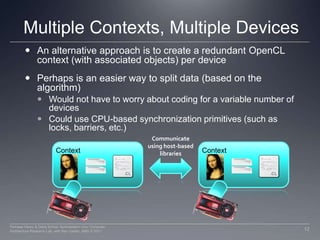







This document discusses approaches to programming multiple devices in OpenCL, including using a single context with multiple devices or multiple contexts. With a single context, memory objects are shared but data must be explicitly transferred between devices. Multiple contexts allow splitting work by device but require extra communication. Load balancing work between heterogeneous CPUs and GPUs requires considering scheduling overhead and data location.



































































