Download to read offline




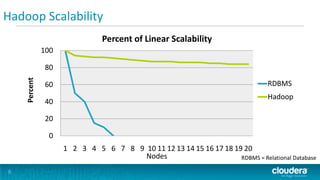




The document discusses randomness and the infinite monkey theorem through three key points: 1) With enough random combinations, even unlikely events become probable, like monkeys randomly typing Shakespeare. 2) Hadoop has near-linear scalability, allowing computational power and storage to increase predictably by simply adding more nodes, unlike relational databases. 3) This scalability provides business value by enabling applications to expand without massive engineering efforts or code rewrites.


























































