Download to read offline
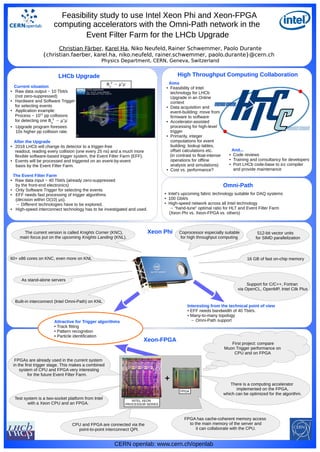


The document discusses a feasibility study by CERN for using Intel Xeon Phi and Xeon-FPGA computing accelerators in the LHCb upgrade's event filter farm. It outlines the changes in data processing and the need for high-speed interconnect technology to handle increased data rates effectively. The study emphasizes the importance of combining CPU and FPGA technologies for optimal event processing and trigger algorithms in the upgraded system.





































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)

















