The document discusses algorithms for spatial joins and query processing, focusing on the unique challenges posed by spatial databases compared to traditional relational databases. It outlines various types of spatial queries and operations, highlights the importance of query optimization in terms of time efficiency, and introduces techniques such as spatial indexes and dynamic programming for effective query execution. Additionally, it covers the two-step query processing approach and provides examples of different spatial join methods and their optimizations.






![Spatial Operations
O Spatial Operations can be classified into four
groups:
Update - Modify, Create etc.
Selection –
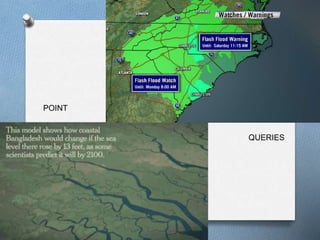
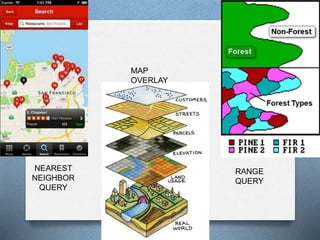
o Point Query (𝑃𝑄): Given a query point 𝑝, find all spatial
objects 𝑂 that contain it:
𝑃𝑄 𝑝 = {𝑂|𝑝 ∈ 𝑂. 𝐺 ≠ ∅}
where 𝑂. 𝐺 is the geometry of the object 𝑂.
Ex. “Find all river flood-plains which contain the CITY” [CITY
is assumed to be a point type]
o Range Query (𝑅𝑄): Given a query polygon 𝑃, find all spatial
objects 𝑂 which intersect 𝑃. [If 𝑃 is a rectangle, 𝑅𝑄 is a
window query]
𝑅𝑄(𝑃)={𝑂│𝑂.ܩ ∧ 𝑃.}∅≠ܩ
Ex. “Get all forests which overlap with flood plain of River
Nile”](https://image.slidesharecdn.com/algorithmsandoptimizationofspatialoperations-151229010600/85/Algorithms-for-Query-Processing-and-Optimization-of-Spatial-Operations-9-320.jpg)


























![Cost Based Optimization:
Dynamic Programming
O Cost Functions
𝑐𝑜𝑠𝑡 = 𝐸𝑥𝑝 𝑟𝑒𝑐𝑜𝑟𝑑𝑠_𝑒𝑥𝑎𝑚𝑖𝑛𝑒𝑑 + 𝐾 ∗ 𝐸𝑥𝑝(𝑝𝑎𝑔𝑒𝑠_𝑟𝑒𝑎𝑑)
𝐸𝑥𝑝 𝑟𝑒𝑐𝑜𝑟𝑑𝑠_𝑒𝑥𝑎𝑚𝑖𝑛𝑒𝑑 = expected number of records read
[measure of CPU time]
𝐸𝑥𝑝(𝑝𝑎𝑔𝑒𝑠_𝑟𝑒𝑎𝑑)= expected number of pages read from
storage [measure of I/O time]
𝐾= measure of how important CPU resources are relative to
I/O resources
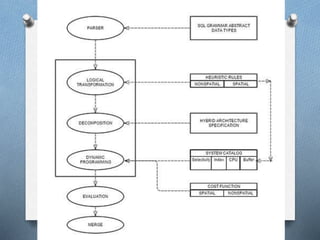
O Decomposition and Merge in Hybrid Architecture
A query is decomposed into spatial and non-spatial part.
Subqueries are optimized in separate modules and are
merged.](https://image.slidesharecdn.com/algorithmsandoptimizationofspatialoperations-151229010600/85/Algorithms-for-Query-Processing-and-Optimization-of-Spatial-Operations-40-320.jpg)




































































