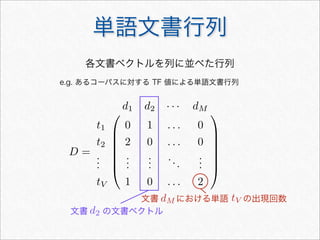
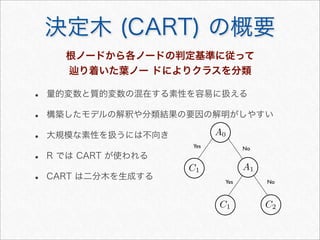
確率的言語モデル
• 単語列 の同時確率を与えるモデル
• 文書の生成方法をモデル化
‣ に従って単語列を生成することで文書を生成可能
wN
1 = w1w2 · · · wN
w N
M
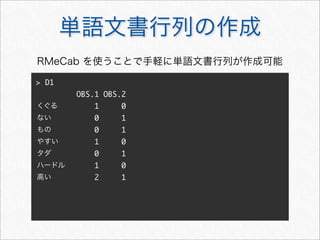
unigram の例(各単語が独立と仮定)
P(wN
1 )
P(wN
1 )
P(d) = P(wN
1 ) =
N
i=1
P(wi)
26.
Unigram Mixtures
w N
M
クラスごとにunigram を割り当てるモデル
• カテゴリの異なる文書は単語の出現確率も異なるはず
• 各文書は1つのクラス(トピック)から生成されると仮定
P(d) =
y
P(y)
N
i=1
P(wi|y)
ˆy = arg max
y
N
i=1
P(wi|y)P(y)
ナイーブベイズはこの値を最大化するクラスを真のクラスと推定する
y
素性関数
fb,s(x, y) =
1if b(x) is true and y = s
0 otherwise
素性の有無を表す2値関数
• e.g.
文書のクラスが class1 で最初が数字で始まれば1,そうでなければ0
• 単語文書行列を扱う場合は「コーパスの語彙数」x 「クラス数」個の素
性関数が存在し、出現頻度などを返す関数
fbegins−with−number,class1










![N-gram による行列
>
> D2 <- t(docNgramDF(texts, type=1, pos=pos, N=2))
number of extracted terms = 7
to make matrix now
> D2
Row1 Row2
1 0
0 1
0 1
1 0
1 0
0 1
1 0
[くぐる-やすい]
[もの-ない]
[タダ-高い]
[ハードル-高い]
[高い-くぐる]
[高い-もの]
[高い-高い]
# 2-gram (bigram) による行列を作成](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-13-320.jpg)

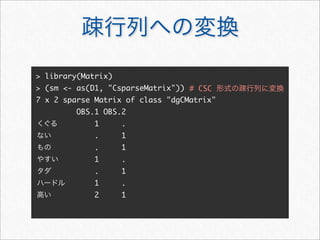
![> str(sm)
Formal class 'dgCMatrix' [package "Matrix"] with 6
slots
..@ i : int [1:8] 0 3 5 6 1 2 4 6
..@ p : int [1:3] 0 4 8
..@ Dim : int [1:2] 7 2
..@ Dimnames:List of 2
.. ..$ : chr [1:7] "くぐる" "ない" "もの" "やすい" ...
.. ..$ : chr [1:2] "OBS.1" "OBS.2"
..@ x : num [1:8] 1 1 1 2 1 1 1 1
..@ factors : list()
疎行列の構造
行のインデックス (0-origin)
列の開始ポインタ (0-origin)
非零の要素の値](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-16-320.jpg)
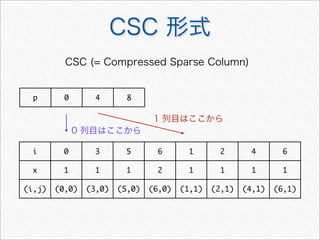
![疎行列の操作
> sm[c(3, 5), ]
2 x 2 sparse Matrix of class "dgCMatrix"
OBS.1 OBS.2
. 1
. 1
> colSums(sm)
[1] 5 4
> rowSums(sm)
[1] 1 1 1 1 1 1 3
> as.matrix(sm[c(3, 5), ])
OBS.1 OBS.2
0 1
0 1
# 3行目と5行目を抽出
もの
タダ
# 各文書の単語数を算出
# 各単語の出現回数を算出
もの
タダ
# 普通の行列に変換
基本的な操作は普通の行列と同様に行うことが可能](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-18-320.jpg)



![サンプルデータ
>
> rownames(D)[which(rownames(D) == "...")] <- "X..."
> set.seed(0)
>
> trainIndex <- sample.int(ncol(D), ncol(D) * 0.5)
> trainData <- t(D[, trainIndex])
> testData <- t(D[, -trainIndex])
> trainTopic <- topic[trainIndex]
> testTopic <- topic[-trainIndex]
# データの半分を学習データとして使用
# rpart でエラーになるので単語名を変更
maxent パッケージの New York Times データを使用](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-22-320.jpg)





![ナイーブベイズを実装
myNaiveBayes - function(x, y) {
lev - levels(y)
ctf - sapply(lev, function(label) {
colSums(x[y == label,])
})
ctp - t(t(ctf + 1) / (colSums(ctf) + nrow(ctf)))
nc - table(y, dnn = NULL)
cp - nc / sum(nc)
structure(list(lev = lev, cp = cp, ctp = ctp),
class = myNaiveBayes)
}
# 各クラスにおける単語出現頻度
# ラプラススムージングによるクラスごとの単語の出現確率
# 各クラスの生成確率
# 各クラスに所属する文書数](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-28-320.jpg)
![ナイーブベイズを実装
predict.myNaiveBayes - function(model, x) {
prob - apply(x, 1, function(x) {
colSums(log(model$ctp) * x)
})
prob - prob + log(as.numeric(model$cp))
level - apply(prob, 2, which.max)
model$lev[level]
}
# 予測用の関数](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-29-320.jpg)
![R でナイーブベイズ
model - myNaiveBayes(trainData, trainTopic)
pred - predict(model, testData)
(tbl - table(pred, truth = testTopic))
truth
pred 16 20
16 193 33
20 27 166
sum(diag(tbl)) / sum(tbl)
[1] 0.8568019
# 正解率](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-30-320.jpg)


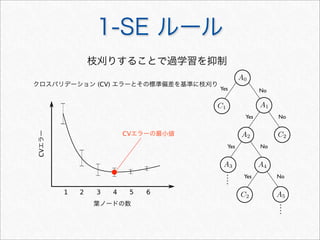
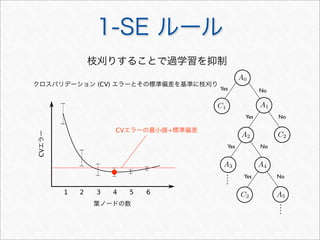
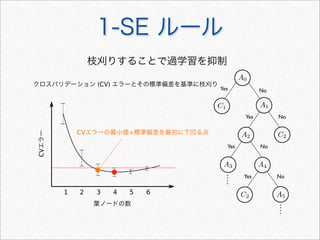
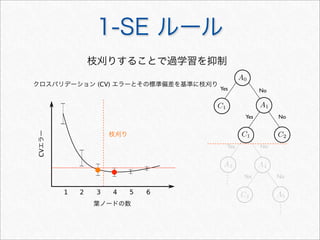
![R で決定木
library(mvpart)
model - rpart(topic ~ .,
+ data.frame(trainData, topic = trainTopic))
pred - predict(model, data.frame(testData),
+ type = class)
(tbl - table(pred, truth = testTopic))
truth
pred 16 20
16 88 6
20 132 193
sum(diag(tbl)) / sum(tbl)
[1] 0.6706444](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-41-320.jpg)




![R で ME モデル
library(maxent)
model - maxent(trainData, trainTopic)
pred - predict(model, testData)[, labels]
(tbl - table(pred, truth = testTopic))
truth
pred 16 20
16 190 36
20 30 163
sum(diag(tbl)) / sum(tbl)
[1] 0.8424821](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-46-320.jpg)

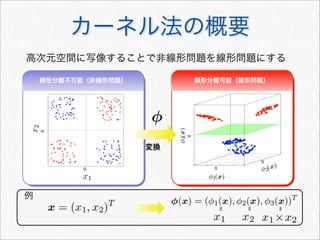
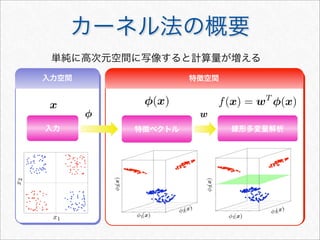
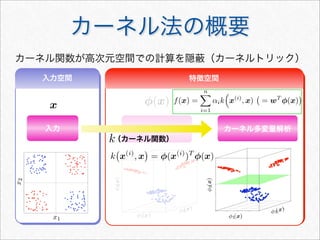
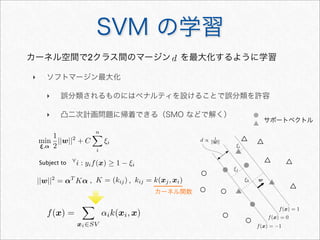
![サポートベクターマシン(SVM)
2つのクラス間のマージンを最大化させるモデル
y = sgn [f(x)] =
1 if f(x) ≥ 0
−1 if f(x) 0
f(x) =
xi∈SV
αik(xi, x)
• パラメータ数の割に過学習に陥りにくい
• カーネル関数により複雑な素性を容易に扱うことが可能
• 構築したモデルの解釈や分類結果の要因の解明が難しい
• 多クラス分類をするには一工夫必要
cf. カーネル多変量解析 4章](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-48-320.jpg)

![R で SVM
library(kernlab)
model - ksvm(trainData, trainTopic,
+ kernel = vanilladot, kpar = list(),
+ scaled = FALSE)
pred - predict(model, testData)
(tbl - table(pred, truth = testTopic))
truth
pred 16 20
16 184 28
20 36 171
sum(diag(tbl)) / sum(tbl)
[1] 0.8472554](https://image.slidesharecdn.com/documentclassificationusingr-130602064804-phpapp01/85/R-54-320.jpg)


















































































