More Related Content

PDF
自然言語処理はじめました - Ngramを数え上げまくる 
PDF
実践・最強最速のアルゴリズム勉強会 第二回講義資料(ワークスアプリケーションズ & AtCoder) 
PPTX
Text classification zansa ![[DL輪読会]Learn What Not to Learn: Action Elimination with Deep Reinforcement Le...](https://cdn.slidesharecdn.com/ss_thumbnails/learnwhatnottolearn-180914011647-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Learn What Not to Learn: Action Elimination with Deep Reinforcement Le... 
PDF

PDF

PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V6 
PDF
PFI Christmas seminar 2009 Viewers also liked

PDF
ComplementaryNaiveBayesClassifier 
PDF
Hadoop/Mahout/HBaseで テキスト分類器を作ったよ 
PDF
Introduction to fuzzy kmeans on mahout 
PDF
Introduction to Mahout Clustering - #TokyoWebmining #6 
PDF

PDF
Apache Mahout - Random Forests - #TokyoWebmining #8 
PDF

PDF
Mahout Canopy Clustering - #TokyoWebmining 9 
PDF
"Mahout Recommendation" - #TokyoWebmining 14th 
PDF
MapReduceによる大規模データを利用した機械学習 
PPTX
20161029 TVI Tokyowebmining Seminar for Share 
PDF

PDF
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京 
PDF
はじめてでもわかるベイズ分類器 -基礎からMahout実装まで- Similar to Mahoutにパッチを送ってみた

PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl... 
PDF

PDF

PPTX
さくっとはじめるテキストマイニング(R言語) スタートアップ編 
PPTX
今さら聞けないHadoop勉強会第2回 セントラルソフト株式会社(20120228) 
PDF

PDF

PDF

PPTX

PDF

PDF

PDF

PDF
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010) 
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP 
PDF

PDF

PDF

PDF

PPT

PDF
Introduction to ensemble methods for beginners Mahoutにパッチを送ってみた
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
実装している手法
• クラスタリング
– K-means / Fuzzy K-means
– 階層クラスタリング
– Canopyクラスタリング
– EM アルゴリズム
– Mean shift
– ディリクレ過程
– Latent Dirichlet Allocation
– スペクトラルクラスタリング
– LSH(Minhash)
- 9.
実装している手法
• 分類
–Naïve Bayes / Complemetaly Naïve Bayes
– ランダムフォレスト
– 確率的勾配降下法(SGD)
• ロジスティック回帰
• Passive Aggressive
– SGDはMapReduceでの分散に対応していない
• パッチを送ってみたよ
- 10.
- 11.
- 12.
- 13.
- 14.
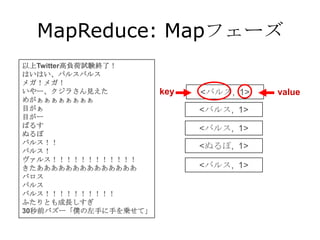
MapReduce: Shuffleフェーズ
以上Twitter高負荷試験終了! <ぬるぽ, 1>
はいはい、バルスバルス
メガ!メガ! <バルス, 1>
いやー、クジラさん見えた
めがぁぁぁぁぁぁぁぁ
目がぁ <バルス, 1>
目がー Key順にソート
ばるす <バルス, 1>
ぬるぽ
バルス!! <バルス, 1>
バルス!
ヴァルス!!!!!!!!!!!! <バルス, 1>
きたああああああああああああああ
バロス <バルス, 1>
バルス
バルス!!!!!!!!!! <バルス, 1>
ふたりとも成長しすぎ
30秒前バズー「僕の左手に手を乗せて」 <バルス, 1>
- 15.
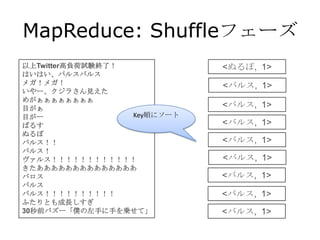
MapReduce: Shuffleフェーズ
以上Twitter高負荷試験終了!
はいはい、バルスバルス
メガ!メガ!
いやー、クジラさん見えた <ぬるぽ, 1>
めがぁぁぁぁぁぁぁぁ
目がぁ
目がー
ばるす
<バルス, [1,1,1,1,1,1,1,1,1,…]>
ぬるぽ
バルス!!
バルス!
ヴァルス!!!!!!!!!!!!
きたああああああああああああああ
バロス
Keyごとにまと
バルス
める
バルス!!!!!!!!!!
ふたりとも成長しすぎ
30秒前バズー「僕の左手に手を乗せて」
- 16.
- 17.
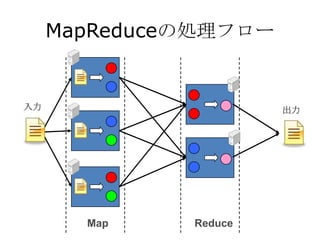
- 18.
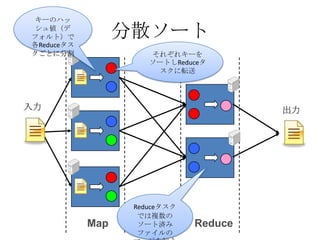
キーのハッ
シュ値(デ
フォルト)で 分散ソート
各Reduceタス
クごとに分割 それぞれキーを
ソートしReduceタ
スクに転送
入力 出力
Reduceタスク
では複数の
Map ソート済み Reduce
ファイルの
- 19.
- 20.
- 21.
- 22.
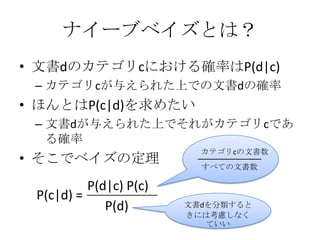
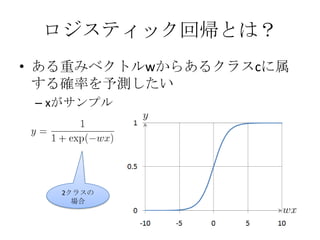
ナイーブベイズとは?
• 単語wのカテゴリcにおける確率
カテゴリcの単語wの頻度の合計
カテゴリcのすべての単語の頻度の合計
• 文書dのカテゴリcにおける確率
– 文書dに出てくる単語wの確率の積と定義
0.07 × 0.1 × 0.01… = 0.000025
• 確率が最も高いカテゴリに分類すればよ
い
• 単語の相関関係や語順は考慮していない
- 23.
- 24.
- 25.
ゼロ頻度問題
• 単語の確率が一つでもゼロになると文書
全体の確率もゼロになってしまう
0.07 × 0.1 × 0.01 × 0 … = 0
• 単語wがクラスcに出現しないからといっ
て確率がゼロなわけではない
• スムージングを行う
カテゴリcの単語wの頻度の合計 + 1
カテゴリcのすべての単語の頻度の合計 + すべての単語の種類数
- 26.
さらなる実装の工夫
• Mahoutでは、以下の論文に書かれている
実装の工夫を行っている
Tackling the Poor Assumptions of Naive Bayes Text
Classifiers (2003)
• 単語頻度(TF)の変換
• 文書頻度の逆数(IDF)を掛ける
• 文書長正規化
• Competent Naïve Bayes
• カテゴリ正規化
- 27.
- 28.
- 29.
- 30.
Complement Naïve Bayes
•カテゴリごとの文書数にばらつきがあると精度が
出ない
• カテゴリcに含まれない文書で学習すればよい
– カテゴリc以外の文書ならば、数のばらつきが少ない
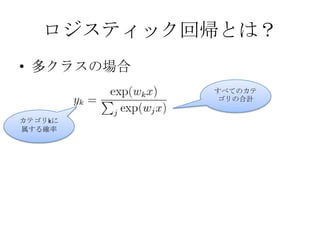
• カテゴリc以外の全てのカテゴリでの単語wの確率
全体での単語wの重み合計 - カテゴリcの単語wの重み合計
全体での全ての単語の重みの合計 - カテゴリcの単語全ての重みの合計
• 確率が最も低いカテゴリに分類すればいい
– カテゴリc以外での確率が最も低い=カテゴリcでの確
率が最も高い
- 31.
- 32.
Mahoutでの実装
• 基本的にはカウント問題
–Mapper
• 何かのKeyと、それに対する数値をValueで出力
– Reducer
• Valueをすべて足し合わせて出力
• カウントしなければならないものが多いので
MapReduceを4回行っている
• Mapperで複数の種類のKeyを出力し、Reducer
では種類ごとに出力先を変えている
• 単語の分割はスペース区切りでしか対応して
いない
- 33.
ナイーブベイズの学習
• BayesFeatureDriver
• BayesTfIdfDriver
• BayesWeightSummerDriver
• CBayesThetaNomalizerDriver(BayesThetaNom
alizerDriver)
- 34.
BayesFeatureDriver
• 文書と正解カテゴリを入力とする
• Mapper
– 単語wの重みを計算する(TF正規化+文書長正規化)
<Key: カテゴリc+単語w> <Value: 単語wの重みの合計>
<Key: カテゴリc+単語w> <Value: 1>
<Key: 単語w> <Value: 1>
<Key: カテゴリc> <Value: 1>
• Reducer
– カテゴリcでの単語wの重みの合計
– カテゴリcで単語wを含む文書数
– 単語wを含むすべての文書数
– カテゴリcに属する文書数
- 35.
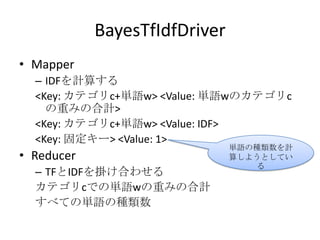
BayesTfIdfDriver
• Mapper
– IDFを計算する
<Key: カテゴリc+単語w> <Value: 単語wのカテゴリc
の重みの合計>
<Key: カテゴリc+単語w> <Value: IDF>
<Key: 固定キー> <Value: 1>
単語の種類数を計
• Reducer 算しようとしてい
る
– TFとIDFを掛け合わせる
カテゴリcでの単語wの重みの合計
すべての単語の種類数
- 36.
BayesWeightSummerDriver
• Mapper
<Key: 単語w> <Value: 単語wのカテゴリcの重みの合計>
<Key: カテゴリc> <Value: 単語wのカテゴリcの重みの合
計>
<Key: 固定キー> <Value: 単語wのカテゴリcの重みの合計
>
• Reducer
– すべての文書の単語wの重み合計
– カテゴリcにおけるすべての単語の重み合計
– すべての文書のすべての単語の重み合計
- 37.
- 38.
- 39.
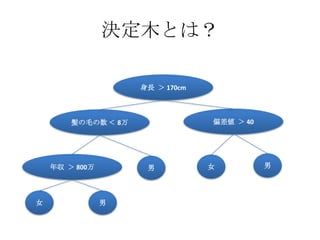
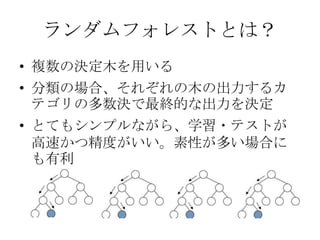
決定木とは?
身長 > 170cm
髪の毛の数 < 8万 偏差値 > 40
年収 > 800万 男 女 男
女 男
- 40.
- 41.
決定木の構築
• 学習データをブートストラップサンプリング
し、B組のデータセットを作成する
– 重複を許したサンプリング
• それぞれのデータセットごとにB組の決定木
を構築する
– M個の素性を選択する
– M個の素性のうち、最も学習データをよく分類す
る素性と閾値を用いて、枝を分岐
– 分岐した先の学習データがすべて同じカテゴリに
属していれば終了
- 42.
- 43.
- 44.
相互情報量
• 枝を分岐前と分岐後のエントロピーの差が、
どれだけ良く学習データを分類しているかの
指標になる
I(X,Y) = H(Y) – H(Y|X)
• 相互情報量とも呼ばれ、どれだけ2つの確率
分布が独立に近いかを表す
独立なときI(X,Y)=0
• 相互情報量が大きい=2つの確率分布に関係
がある
– カテゴリがcである確率と、素性がx以上である確
率により関係があるような素性とxで分類
- 45.
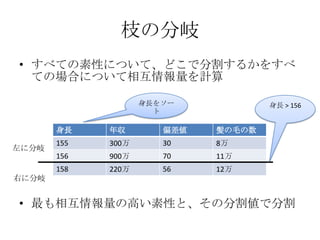
枝の分岐
• すべての素性について、どこで分割するかをすべ
ての場合について相互情報量を計算
身長をソー 身長 > 156
ト
身長 年収 偏差値 髪の毛の数
155 300万 30 8万
左に分岐
156 900万 70 11万
158 220万 56 12万
右に分岐
• 最も相互情報量の高い素性と、その分割値で分割
- 46.
- 47.
Mahoutでの実装
• ImMemInputFormat
– Mapperの数 / 決定木の数 だけ各Mapperに処理
を割り当てる
– 学習データを各Mapperの入力にするのではな
い
• InMemMapper
– 決定木の数だけmap関数が呼ばれる
• それぞれの繰り返しで、ブートストラップサンプ
リングを行って、決定木の構築を行う
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
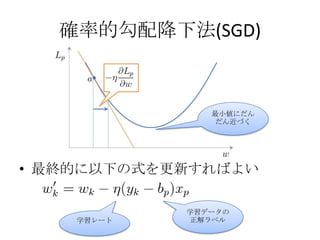
Mahoutの実装
• L1/L2正則化に対応している
– 過学習を防ぐために損失関数にペナルティ項を設ける
L1正則化
重みが大きな
• FOBOSでペナルティ項も含めてオンラインで更新 値を取り過ぎ
– 重みがゼロになりやすいように工夫 るとペナル
ティ
• Lazy Updateで高速化
– 0の素性は更新しない
– 素性が0ではないデータが来た場合、今までゼロだった分を一気に更新
する
– スパースなベクトル(ほとどんどゼロなベクトル)の場合有効
• 学習レート
– 素性ごとと、全体の2種類の学習レートがある
– それぞれ、更新されるごとに減少させている
- 56.
Adaptive Logistic Regression
•ハイパーパラメータ(学習レートなど)
が違う学習器をn個用意
• データ数件を、それぞれの学習器で学習
– スレッドで並列に学習させている
• 学習結果がよい学習器(尤度の合計がよ
いもの)上位m件を選択
• 上位m件の学習器と、上位の学習器のパラ
メータを少しランダムに変化させたn-m個
の学習器で再度学習を行う
- 57.
送ったパッチの概要
• オンライン学習をMapReduceで行う
–近年オンライン学習を並列分散する手法が多
く提案されている
– 最も良い結果が出ているIterative Parameter
Mixingという手法を実装
• 以下のアルゴリズムに対応
– Logistic Regression
– Adaptive Logistic Regression
– Passive Aggressive
- 58.
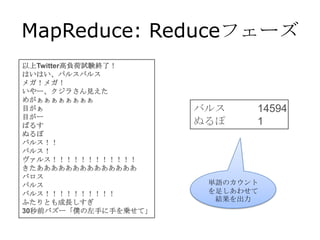
Iterative Parameter Mixing
Mapper Mapper Mapper
重みベクトル 重みベクトル 重みベクトル
を更新 を更新 を更新
Reducer
重みベクトル
を平均
[Mann et al. 09]
[Mcdonald et al. 10]
- 59.
MapReduce
• Mapper
– 正解データを入力
– 前回の繰り返しの重みをMapの初期化処理で読み
込んでおく
– オンライン学習で、重みを更新
Key スコア(尤度の合計など)
Value 重み
• Reducer
– Reducerは一つだけ立ち上げる
– 重みをスコアで重み付き平均して出力する
• このMapReduceを繰り返す
- 60.
送ろうパッチ
• Mahoutはパッチを送ってみるにはいいの
かも
– MahoutはHadoop本体などと比べて、それほど
完成されておらず、改善の余地も多い
– 全体のコード量もHadoop本体と比べて少ない
– Hadoop / MapReduce使わなくてもJavaで書き
さえすればいいらしい
- 61.
- 62.
- 63.
- 64.












![MapReduce: Shuffleフェーズ
以上Twitter高負荷試験終了!
はいはい、バルスバルス
メガ!メガ!
いやー、クジラさん見えた <ぬるぽ, 1>
めがぁぁぁぁぁぁぁぁ
目がぁ
目がー
ばるす
<バルス, [1,1,1,1,1,1,1,1,1,…]>
ぬるぽ
バルス!!
バルス!
ヴァルス!!!!!!!!!!!!
きたああああああああああああああ
バロス
Keyごとにまと
バルス
める
バルス!!!!!!!!!!
ふたりとも成長しすぎ
30秒前バズー「僕の左手に手を乗せて」](https://image.slidesharecdn.com/mahout-111210004854-phpapp02/85/Mahout-15-320.jpg)































![Iterative Parameter Mixing
Mapper Mapper Mapper
重みベクトル 重みベクトル 重みベクトル
を更新 を更新 を更新
Reducer
重みベクトル
を平均
[Mann et al. 09]
[Mcdonald et al. 10]](https://image.slidesharecdn.com/mahout-111210004854-phpapp02/85/Mahout-58-320.jpg)





